3 Ways to Keep Stale Facts Fresh in Large Language Models
Large Language Models (LLM) like GPT3, ChatGPT and BARD are all the rage today. Everyone has an opinion about how these tools are good or bad for society and what they mean for the future of AI. Google received a lot of flak for its new model BARD getting a complex question wrong (slightly). When asked “What new discoveries from the James Webb Space Telescope can I tell my 9-year-old about?” – the chatbot provided three answers, out of which 2 were right and 1 was wrong. The wrong one was that the first “exoplanet” picture was taken by JWST, which was incorrect. So basically, the model had an incorrect fact stored in its knowledgebase. For large language models to be effective, we need a way to keep these facts updated or augment the facts with new knowledge.
Let’s first look at how facts are stored inside of large language model (LLM). Large language models do not store information and facts in a traditional sense like databases or files. Instead, they have been trained on vast amounts of text data and have learned patterns and relationships in that data. This enables them to generate human-like responses to questions, but they don’t have a specific storage location for their learned information. When answering a question, the model uses its training to generate a response based on the input it receives. The information and knowledge that a language model has is a result of the patterns it has learned in the data it was trained on, not a result of it being explicitly stored in the model’s memory. The Transformers architecture on which most modern LLMs are based on have an internal encoding of facts that is used for answering the question asked in the prompt.

So, if facts inside the internal memory of the LLM are wrong or stale, new information needs to be provided via a prompt. Prompt is the text sent to LLM with the query and supporting evidence that can be some new or corrected facts. Here are 3 ways to approach this.
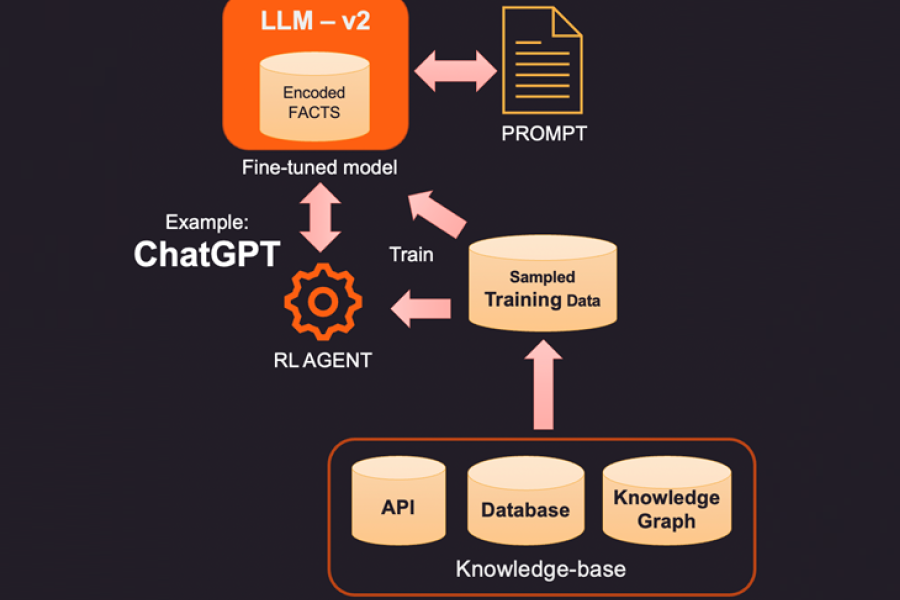
1. One way to correct the encoded facts of a LLM is to provide new facts relevant to the context using an external knowledge base. This knowledge base may be API calls to get relevant information or a lookup on a SQL, No-SQL, or Vector database. More advanced knowledge can be extracted from a knowledge graph that stores data entities and relations between them. Depending on the information user is querying for, the relevant context information can be retrieved and given as additional facts to the LLM. These facts may also be formatted to look like training examples to improve learning process. For example, you may pass a bunch of question answer pairs for model to learn how to provide answers.

2. A more innovative (and more expensive) way to augment the LLM is actual fine-tuning using training data. So instead of querying knowledge base for specific facts to add, we build a training dataset by sampling the knowledge base. Using supervised learning techniques like fine tuning we could create a new version of the LLM that is trained on this additional knowledge. This process is usually expensive and can cost a few thousand dollars to build and maintain a fine-tuned model in OpenAI. Of course, the cost is expected to get cheaper over time.
3. Another option is to use methods like Reinforcement Learning (RL) to train an agent with human feedback and learn a policy on how to answer questions. This method has been highly effective in building smaller footprint models that get good at specific tasks. For example, the famous ChatGPT released by OpenAI was trained on a combination of supervised learning and RL with human feedback.

In summary, this is a highly evolving space with every major company wanting to get into and show their differentiation. We will soon see major LLM tools in most areas like retail, healthcare and banking that can respond in a human-like manner understanding the nuances of language. These LLM-powered tools integrated with enterprise data can streamline access and make right data available to right people at right time.
Credit: Source link
Comments are closed.