Facebook AI and University of Guelph Open-Sources Graph HyperNetworks (GHN-2): A Meta-Model That Predicts Starting Parameters For Deep-Learning Neural Networks

In machine learning pipelines, deep learning has proved successful in automating feature design. However, many researchers reveal that the techniques for improving neural network parameters are still mostly hand-crafted and computationally inefficient.
To overcome such shortcomings, Facebook AI Research (FAIR) and the University of Guelph have released an updated Graph HyperNetworks (GHN-2) meta-model that predicts starting parameters for deep-learning neural networks. With no extra training, GHN-2 runs in less than a second on a CPU and predicts values for computer vision (CV) networks that reach up to 77 percent top-1 accuracy on CIFAR-10.
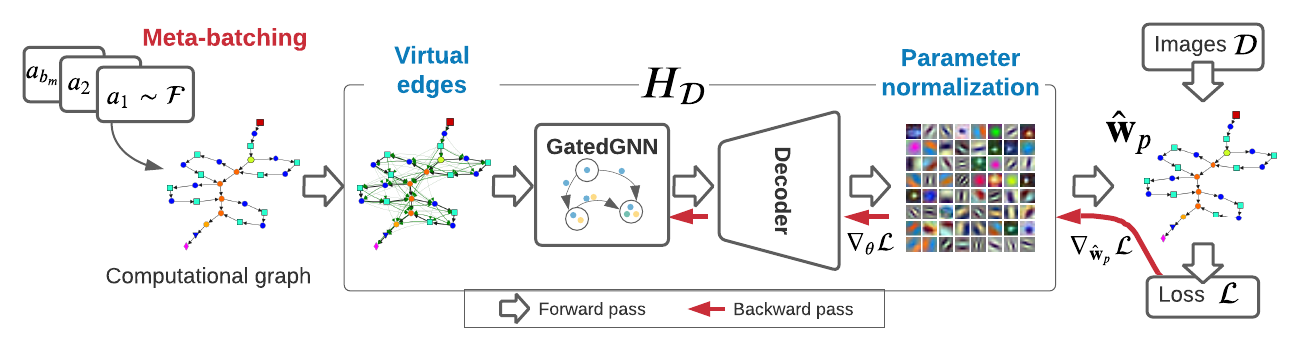
The researchers created the DeepNets-1M dataset to solve the problem of guessing initial parameters for deep-learning models. This dataset contains one million examples of neural network architectures expressed as computational graphs. They then employed meta-learning to train a modified graph hyper-network (GHN) using this dataset, which can be used to forecast parameters for a network architecture that has never been seen before. Even for architectures far larger than the ones used in training, the resulting meta-model performs better at the task. The meta-model revealed parameters that achieved 60% accuracy on CIFAR-10 with no gradient updates when used to start a 24M-parameter ResNet-50.
Training a deep-learning model on a dataset is the process of finding a set of model parameters that minimize the model’s loss function when assessed on training data. For this, generally, an iterative optimization technique such as stochastic gradient descent (SGD) or Adam is used. However, it can take many hours of calculation and a lot of energy to minimize. In many cases, researchers have to frequently train multiple models to discover the ideal network architecture and collection of hyperparameters, further increasing the cost.
Therefore, the team designed a hyper-model that is trained on a specific dataset to cut the cost of training models. The hyper-model can forecast network performance metrics when given a specified network topology. The researchers devised a meta-learning challenge after working on a network architecture search (NAS) technique called Differentiable ARchiTecture Search (DARTS). A domain-specific dataset, such as ImageNet, and a training set of model network designs defined as computational graphs are required for this task. The researchers then used graph-learning approaches to train a hyper-model to predict parameters for input network designs that minimize network loss on domain-specific data.
The researchers trained meta-models for two domain-specific datasets: ImageNet and CIFAR-10. To evaluate the model’s performance, they compared the performance of GHN-2 parameters to those created by two additional baseline meta-models and model parameters generated by typical iterative optimizers. The parameters were predicted using a set of network designs that were not used in the meta-models’ training. The results show that GHN-2 outperforms the baseline meta-models with significant margins. Furthermore, the parameters predicted by GHN-2 with only a single forward pass on CIFAR-10 and ImageNet datasets show an accuracy equivalent to 2500 and 5000 iterations of SGD.
One of the limitations of the GHN-2 model is that for each domain-specific dataset, a new meta-model must be trained first. Furthermore, while GHN-2 can forecast parameters that outperform random choices, the predictions depend on the design and may not be precise.
GitHub: https://github.com/facebookresearch/ppuda
Paper: https://arxiv.org/pdf/2110.13100.pdf
Reference: https://www.infoq.com/news/2021/11/facebook-ghn-meta-model/
Suggested

Credit: Source link
Comments are closed.