Google Research Release Reinforcement Learning Datasets For Sequential Decision Making
")
Most reinforcement learning (RL) and sequential decision-making agents generate training data through a high number of interactions with their environment. While this is done to achieve optimal performance, it is inefficient, especially when the interactions are difficult to generate, such as when gathering data with a real robot or communicating with a human expert.
This problem can be solved by utilizing external knowledge sources. However, there are very few of these datasets and many different tasks and ways of generating data in sequential decision making, so it has become unrealistic to work on a small number of representative datasets. Furthermore, some of these datasets are released in a format that only works with specific methods, making it impossible for researchers to reuse them.
Google researchers have released Reinforcement Learning Datasets (RLDS) and a collection of tools for recording, replaying, modifying, annotating, and sharing data for sequential decision making, including offline reinforcement learning, learning from demonstrations, and imitation learning. RLDS makes it simple to share datasets without losing any information. It also allows users to test new algorithms on a broader range of jobs easily. RLDS also includes tools for collecting data and examining and altering that data.
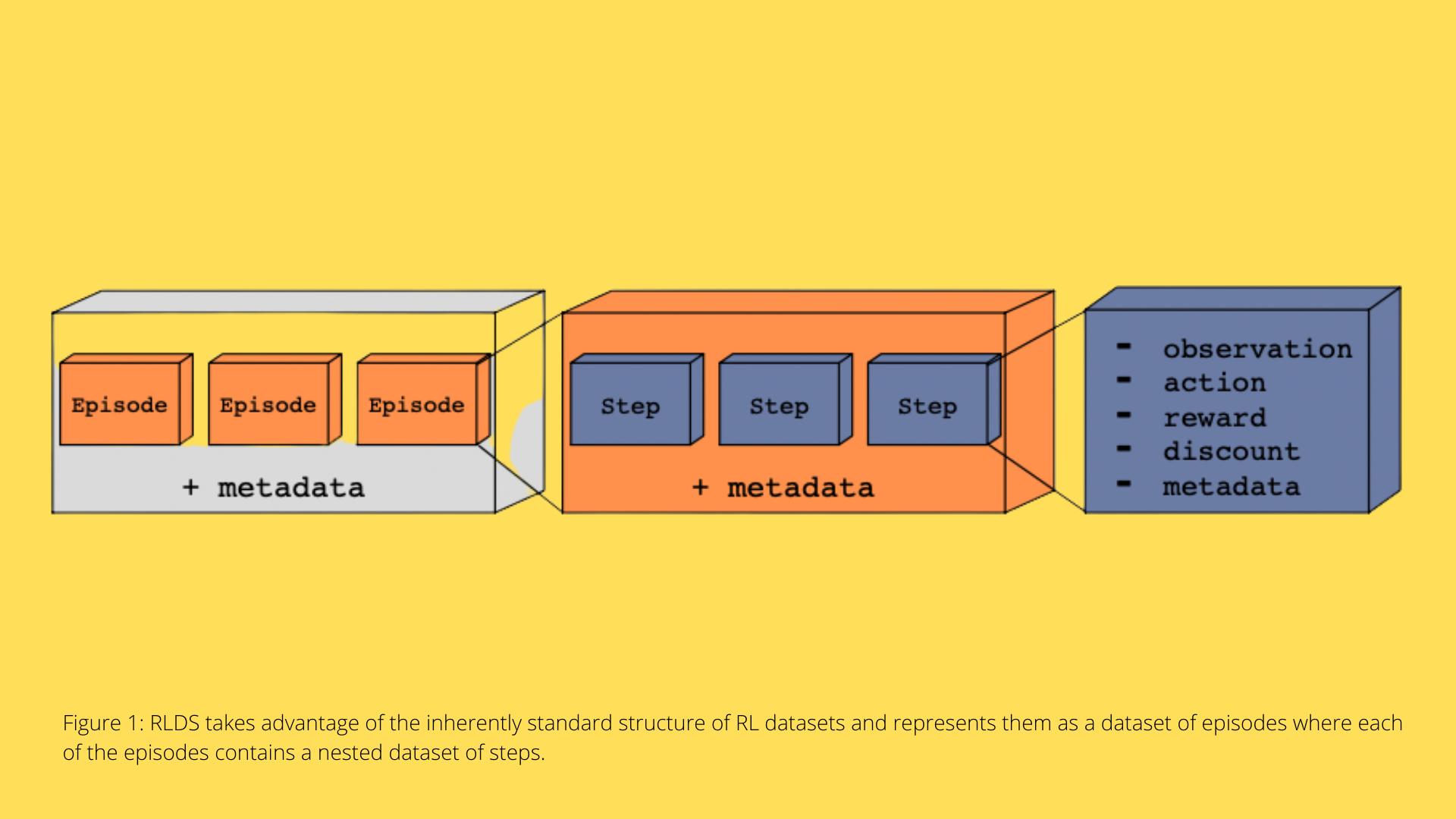
Most RL-based algorithms consume data in a variety of formats. That is why it’s easy to introduce flaws due to misinterpretations of the underlying data if the dataset format is unclear. RLDS specifies the data format by specifying the contents and meaning of each field in the dataset. It offers tools for re-aligning and transforming the data to meet the format required by any algorithm implementation. RLDS uses the intrinsically standard structure of RL datasets to define the data format — that is, sequences (episodes) of interactions (steps) between agents and environments, where agents can be any agent.
Each of these phases includes:
- The current observation
- The action taken in response to the current observation
- The reward earned as a result of the action
- The discount obtained in conjunction with the reward.
Additional information is included in each step to indicate whether it is the first or last step in the episode or if the observation corresponds to a terminal condition. Each step and episode may also include custom metadata that can be used to hold data about the environment or the model.
As datasets are time-consuming to create, sharing them with the broader research community allows it to speed up research by making it easier to test and evaluate new methods across a variety of settings. TensorFlow Datasets (TFDS), an existing library for sharing datasets throughout the machine learning community, is integrated with RLDS for this purpose. The dataset is indexed in the TFDS catalog on becoming part of TFDS, making it searchable by any researcher.
Because TFDS is unaffected by the original dataset’s underlying format, any existing dataset in an RLDS-compatible format can be utilized with RLDS, even if it was not created with EnvLogger or RLDS Creator. Users retain full ownership and management of their data using TFDS. In addition, all datasets include a citation to credit the dataset creators.
With RLDS, researchers can now utilize the datasets to analyze, visualize, and train a range of machine learning algorithms, which consume data in formats other than that in which it was stored. RLDS provides a library of transformations for RL scenarios to help with this. These transformations have been improved to account for the hierarchical structure of the RL datasets. Furthermore, auto-batching has been used to speed up some of the procedures. RLDS users can quickly create various high-level functionality using those efficient transformations, and the pipelines developed are reusable across RLDS datasets.
TFDS currently has the following datasets (all of which are compatible with RLDS):
- A subset of D4RL containing Mujoco and Adroit tasks
- the DMLab, Atari, and Real World RL datasets from RLUnplugged
- Three Robosuite datasets created using RLDS technologies.
Paper: https://arxiv.org/pdf/2111.02767.pdf
Github: https://github.com/google-research/rlds
Reference: https://ai.googleblog.com/2021/12/rlds-ecosystem-to-generate-share-and.html
Suggested

Credit: Source link
Comments are closed.