Purdue University Researchers Introduce A Compositional Reader Model That Composes Multiple Documents In One Shot To Form A Unified Political Entity Representation
")
Natural language processing (NLP) is an area of computer science—more specifically, a branch of artificial intelligence (AI)—that deals with computers’ capacity to understand the text and spoken words in the same way that humans can. But even humans sometimes find it difficult enough to decipher the deeper meaning and context of social media and news items. It’s nearly impossible to ask computers to accomplish it. Even C-3PO, who can communicate in over 6 million different ways, misses the subtext a lot of the time.
Natural language processing analyses language using statistical methods frequently without considering the real-world context required to comprehend human society’s shifts and currents. To accomplish the task mentioned above, it must convert online communication and the context in which it occurs into a format that computers can understand and reason about.
Researchers at Purdue University are working on new approaches to model human language so that computers can understand people better. Part of the problem, according to them, is that so much of online communication relies on readers already knowing the context—whether it’s Twitter shorthand or the foundation for comprehending a meme. The context is an essential aspect of the message when analyzing it.
For example, in the event of a school shooting, consider the following tweet: “We must treat our teachers with more respect! We must safeguard them”. Suppose the tweet’s author is Kamala Harris, who is known to be pro-gun control. In that case, the tweet will most likely be interpreted as “ban guns to prevent mass shootings in schools.” If the identical tweet comes from Mike Pence, who believes that “firearms in the hands of citizens who abide by the law make our communities safer,” the post may mean “arming school instructors stops active shooters.” This example highlights how the same language can signal radically different real-world actions depending on the context.
Hence, the model needs to understand the broader context of the text to understand its true meaning. This approach, which combines text and context analysis, necessitates two computational settings:
- The ability to generate a meaningful unified representation in one shot that captures the complementary strengths of the many inputs
- An input representation that meaningfully incorporates all of the distinct sources of information.
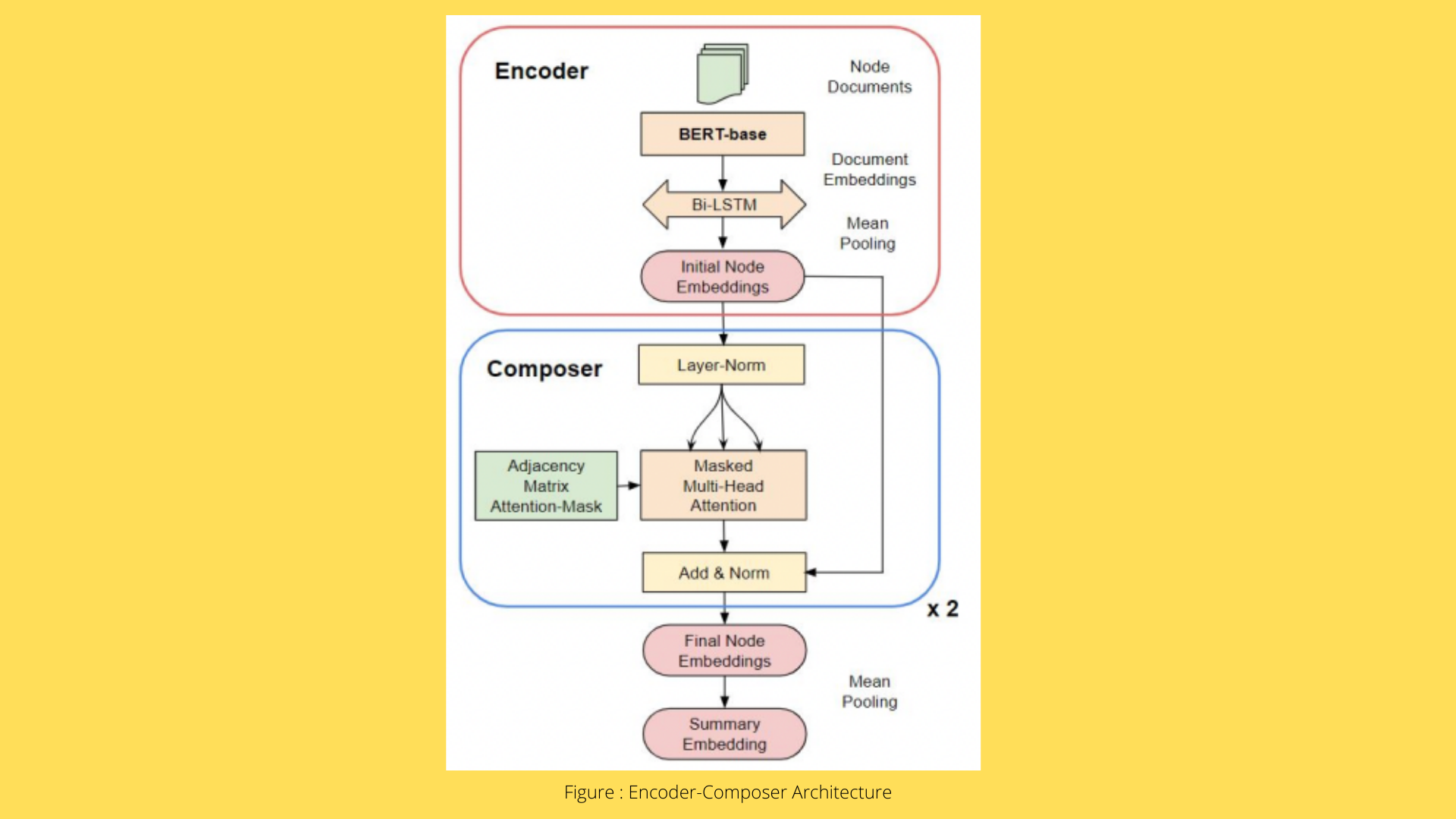
The first challenge is addressed by establishing a graph structure that connects first-person informal (tweets), formal (press releases and viewpoints), third-person current (news), and consolidated (Wikipedia) discourse. The authors, the issues/events they describe, and the entities named in them all tie these papers together. An Encoder combines all documents relevant to a specific node to provide an initial node representation. A Composer, a Graph Attention Network (GAT), composes the graph structure to generate contextualized node embeddings, is employed in this neural network design.
To get the model trained and capture structural dependencies across the rich discourse representation, two self-supervised learning tasks that predict Authorship and Referenced Entity linkages over the graph structure are created. Intuitively, the model is required to comprehend complex language usage; authorship prediction necessitates the model to distinguish between:
- the language of one author from that of another,
- the author’s language in the context of one issue vs. another issue.
Given the author’s previous discourse, referenced entity prediction necessitates comprehending the language employed by a particular author when discussing a specific entity. On both qualitative and quantitative tasks, the above model outperforms the BERT-based traditional model.
To comprehend the context and assumptions of the speakers and writers, researchers at Purdue University examined the language used on social media, in traditional media stories, and in legislative texts. Being able to study and analyze that writing in an unbiased manner is vital to human comprehension of culture in a world when the written world is growing, and everyone with an internet connection may function as a journalist.
Paper: https://aclanthology.org/2021.emnlp-main.102.pdf
Github: https://github.com/pujari-rajkumar/compositional_learner
Reference: https://techxplore.com/news/2021-11-subtext-text.html
Suggested
Credit: Source link
Comments are closed.