Google AI Introduces MURAL (Multimodal, Multi-task Retrieval Across Languages) For Image–Text Matching
")
There is no straight one-to-one translation from one language to another for many concepts. Even when there is, such translations typically contain various connections and meanings that a non-native speaker would easily miss. However, when the idea is anchored in visual examples, the meaning may be more evident. Although each person’s associations with the term may differ significantly, the meaning becomes more evident when they are presented with a visual of the intended concept. Take the word “wedding,” for example. In English, a bride in a white gown and a groom in a tuxedo are frequently associated, however in Hindi (शादी), a bride in brilliant colors and a guy in a sherwani may be a more fitting association.
It is now feasible to eliminate ambiguity in translation by displaying a text combined with a supporting image, thanks to recent developments in neural machine translation and image recognition. For high-resource languages like English, previous research has made significant progress in learning image–text combined representations. These representation models aim to store the picture and text as vectors in a shared embedding space where the image and the text describing it are close to each other. For example, ALIGN and CLIP have shown that when given enough training data, training a dual-encoder model (i.e., one with two independent encoders) on image-text pairs using a contrastive learning loss works exceptionally well.
Unfortunately, for most languages, comparable image–text pair data does not exist at the same scale. In fact, the top ten languages with the most data, such as English and Chinese, account for more than 90% of this sort of online data, with substantially less data for under-resourced languages. To get around this problem, manual collection of image–text pair data should be done for under-resourced languages. However, this would be a difficult task given the project’s scope, or use pre-existing datasets (e.g., translation pairs) to inform the necessarily learned representations for multiple languages.
Google has launched MURAL: Multimodal, Multitask Retrieval Across Languages, a representation model for image–text matching that leverages multitask learning applied to image–text pairs in tandem with translation pairs encompassing 100+ languages. With MURAL, users can use visuals instead of words to express words that don’t have a direct translation in the target language. For example, the Malagasy term “valiha” refers to a form of tube zither that has no direct translation in most languages but may be simply communicated through visuals.
MURAL Architecture
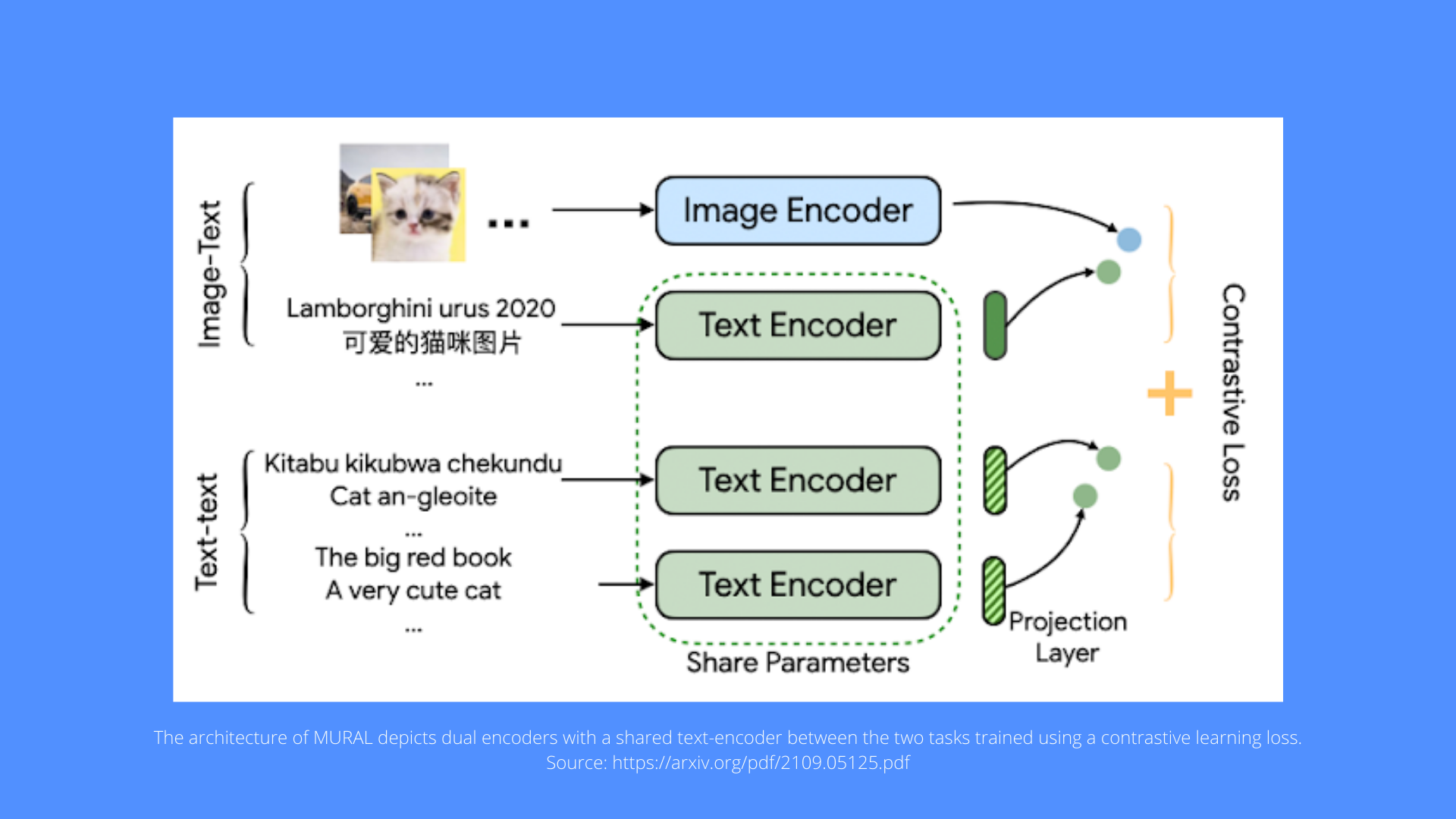
The MURAL architecture is based on the ALIGN structure. However, it is used in a multitasking manner. Unlike ALIGN that utilizes a dual-encoder architecture to bring together image representations and related text descriptions, MURAL does the same thing while also extending it across languages by integrating translation pairings.
MURAL handles two contrastive learning tasks:
- Image-Text matching
- Text–text (bitext) matching, with the text encoder module shared by both.
From the image–text data, the model learns correlations between images and text, as well as representations for hundreds of different languages from translation pairs.
Image-to-Text and Text-to-Image Retrieval in Multiple Languages
The team chose the task of cross-modal retrieval (i.e., retrieving relevant images given a text and vice versa) to demonstrate MURAL’s capabilities, and the main focus was on the results of a variety of academic image–text datasets covering well-resourced languages, such as MS-COCO (and its Japanese variant, STAIR), Flickr30K (in English) and Multi30K (extended to German, French, and Czech), XTD (extended to German, French, and Czech), and (test-only set with seven well-resourced languages: Italian, Spanish, Russian, Chinese, Polish, Turkish, and Korean).
MURAL consistently outperforms state-of-the-art models, other benchmarks, and competitive baselines across the board, according to empirical evidence. Furthermore, MURAL performs admirably for the vast majority of under-resourced languages on which it has been tested.
Retrieval Analysis
ALIGN and MURAL for English (en) and Hindi (hindi) retrieved zero-shot samples on the WIT dataset (hi) were compared. In under-resourced languages like Hindi, MURAL outperforms ALIGN in retrieval, indicating a greater understanding of text semantics. Even in a language with a lot of resources, like French, MURAL exhibits a higher understanding of specific terms.
Embeddings Visualization
Researchers have previously demonstrated that displaying model embeddings can reveal interesting links between languages — for example, representations acquired by a neural machine translation (NMT) model have been shown to form clusters based on their language family membership. A subset of languages from the Germanic, Romance, Slavic, Uralic, Finnic, Celtic, and Finno-Ugric language families are visualized in a similar way (widely spoken in Europe and Western Asia). The text embeddings of MURAL are compared to those of LaBSE, a text-only encoder.
MURAL’s embeddings, which are trained with a multimodal aim, display some clusters that are consistent with areal linguistics (where elements are shared by languages or dialects in a geographic area) and contact linguistics, in contrast to LaBSE’s representation (where languages or dialects interact and influence each other).
For many under-resourced languages, utilizing translation pairings helps overcome the lack of image-text pairs and increases cross-modal performance. In addition, there are clues of areal and contact linguistics in the text representations trained using a multimodal model, which is intriguing. This necessitates a deeper investigation into the various connections learned implicitly by multimodal models like MURAL. Beyond well-resourced languages, this study will encourage more research in the multimodal, multilingual domain, where models develop representations of and link across languages (represented via images and text).
Paper: https://arxiv.org/pdf/2109.05125.pdf
Reference: https://ai.googleblog.com/2021/11/mural-multimodal-multi-task-retrieval.html
Suggested
Credit: Source link
Comments are closed.