Meta AI Develops A Conversational Parser For On-Device Voice Assistants

A variety of devices such as computers, smart speakers, cellphones, etc., utilize conversational assistants for helping users with tasks ranging from calendar management to weather forecasting. These assistants employ semantic parsing to turn a user’s request into a structured form with intents and slots that may be executed later. However, to access larger models operating in the cloud, the request frequently needs to go off-device.
Complex semantic parsers use seq2seq modeling. Auto-regressive generation (token by token) has a latency that makes such models impractical for on-device modeling.
Facebook/Meta AI introduces a new model for on-device assistants and illustrates how to make larger server-side models less computationally expensive.
Their recent work improves the efficiency of seq2seq modeling while maintaining scalability. They offer non-autoregressive semantic parsing, a new paradigm for decoding all tokens in parallel. They use parallel decoding to overcome the latency penalty of seq2seq modeling, resulting in considerable latency reductions and accuracy comparable to autoregressive models.
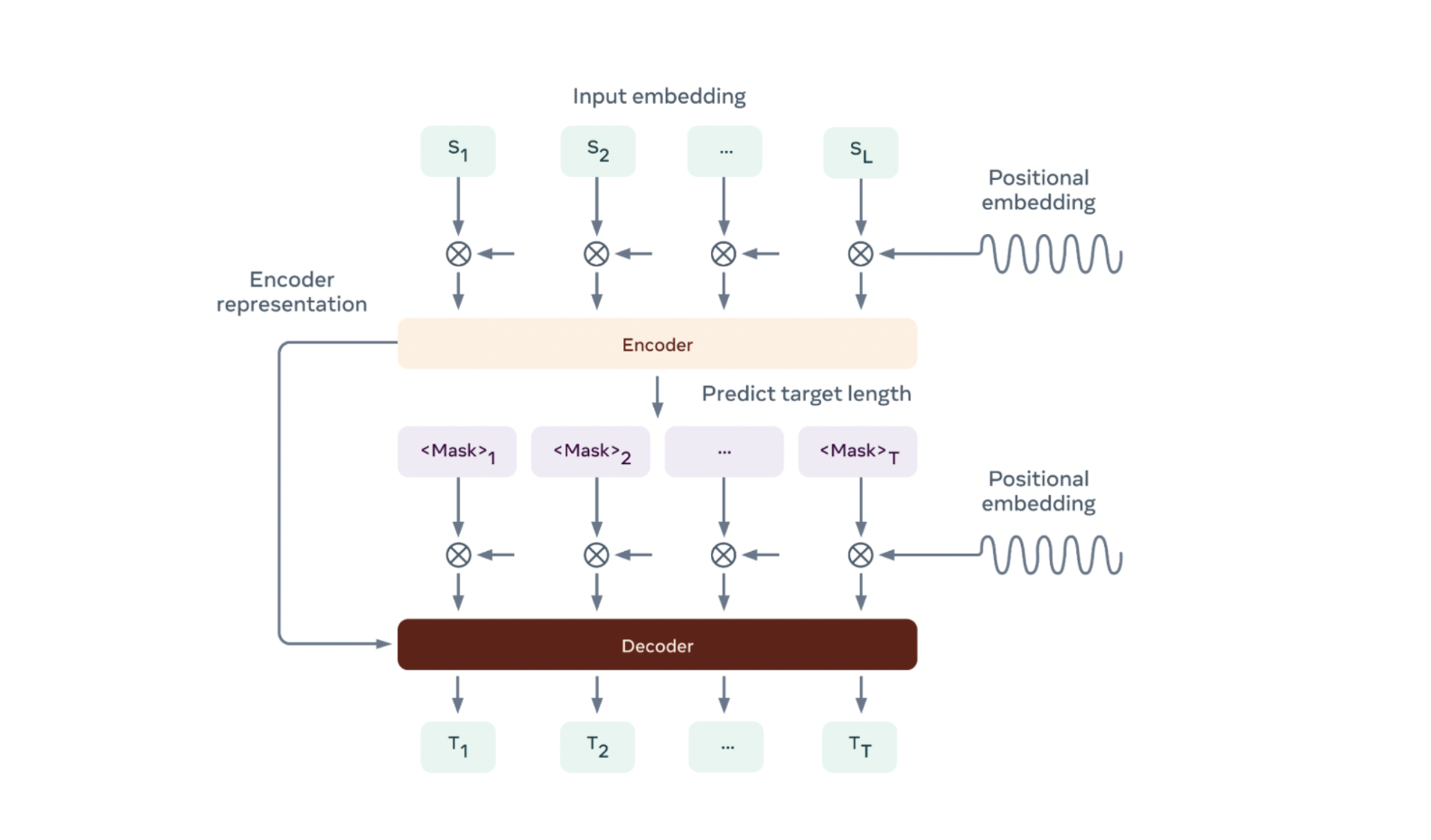
The researchers state that due to the rigidity of the length prediction job, non-autoregressive semantic parsers have trouble generalizing. This is because length prediction necessitates knowledge of both the user utterance (slot text) and the target ontology (intent/slot labels). To circumvent this issue, they suggest using span pointer networks. It is a non-autoregressive approach that uses only the target ontology for length prediction and relies on span-based decoding. Using this span formulation increase quality and generalization while lowering latency and memory usage when working with bigger beam sizes.
The new architecture is based on: non-autoregressive semantic parsing and non-autoregressive parsing with span pointer networks. While Autoregressive (conventional) parsing involves linear decoding, token by token, non-autoregressive modeling allows for fully parallel decoding (producing the entire sequence at once). Non-autoregressive approaches are frequently associated with a trade-off in accuracy. However, the suggested methods for span-based non-autoregressive parsing reach parity with autoregressive methods.

Source: https://ai.facebook.com/blog/building-a-conversational-parser-for-on-device-voice-assistants
The semantic parsers are divided into three parts in the first model: encoding, length prediction, and decoding. The model is in charge of encoding the speech, predicting the length of the output and constructing that many mask tokens, and then decoding each token in turn. The results show that the non-autoregressive parsers achieve accuracy parity with autoregressive parsers of similar architectures while giving significant advantages in decoding speed through rigorous testing.

Source: https://ai.facebook.com/blog/building-a-conversational-parser-for-on-device-voice-assistants
According to researchers, the generalization of such a model is limited by the length prediction task. The model needs to know the number of intent and slot labels and the length of any relevant slot text in the output parse to anticipate the right length.
In this context, they developed a novel parser that focuses on span-based prediction rather than slot text creation. Because a slot is represented by only two tokens (start/end index), switching to span decoding decouples the length of the output from the user’s utterance text. Slot text is always two characters long, regardless of the content or language it is written in, resulting in a far more consistent modeling task.
The new generation form demonstrates considerable gains in quality (+1.2% absolute vs. earlier non-autoregressive parsers), cross-domain generalization (an average 15% improvement on the reminder domain vs. prior non-autoregressive parsers), and cross-lingual benefits (13.7 percent improvement over an XLM-R autoregressive baseline).
These enhancements could pave the way for retaining on-device privacy at scale without losing accuracy or performance and also serve as a blueprint for bringing larger models to the server. Compared to previous work in both non-autoregressive modeling in machine translation and efficient modeling in semantic parsing, the findings show that it is possible to decode full semantic parsers to state-of-the-art quality in a single decoding step while retaining the quality and generalization properties of auto-regressive parsers.
Paper 1: https://arxiv.org/pdf/2104.04923.pdf
Paper 2: https://arxiv.org/pdf/2104.07275.pdf
Reference: https://ai.facebook.com/blog/building-a-conversational-parser-for-on-device-voice-assistants
Suggested
Credit: Source link
Comments are closed.