The Researchers Propose a Family of Next Generation Transformer Models That Use Sparse Layers to Scale Efficiently and Perform Unbatched Decoding Much Faster than the Standard Type

Large-scale transformer systems have drastically enhanced natural language processing (NLP) tasks. The original Transformer significantly improved the state-of-the-art in machine translation. However, the advantages of this progress are outweighed by the enormous expenses that these models entail. The models are so slow at decoding that they are challenging to use and study.
Researchers from the University of Warsaw, Google Research, and OpenAI propose Scaling Transformers. These transformers use sparse layers to scale efficiently and perform unbatched decoding much faster than original transformers, allowing fast inference on long sequences even with limited memory.
Interestingly, the sparse layers are sufficient to achieve the same perplexity as the regular Transformer with the same number of parameters. The researchers also incorporate previous sparsity attention techniques, allowing quick inference on extended sequences even with limited memory.
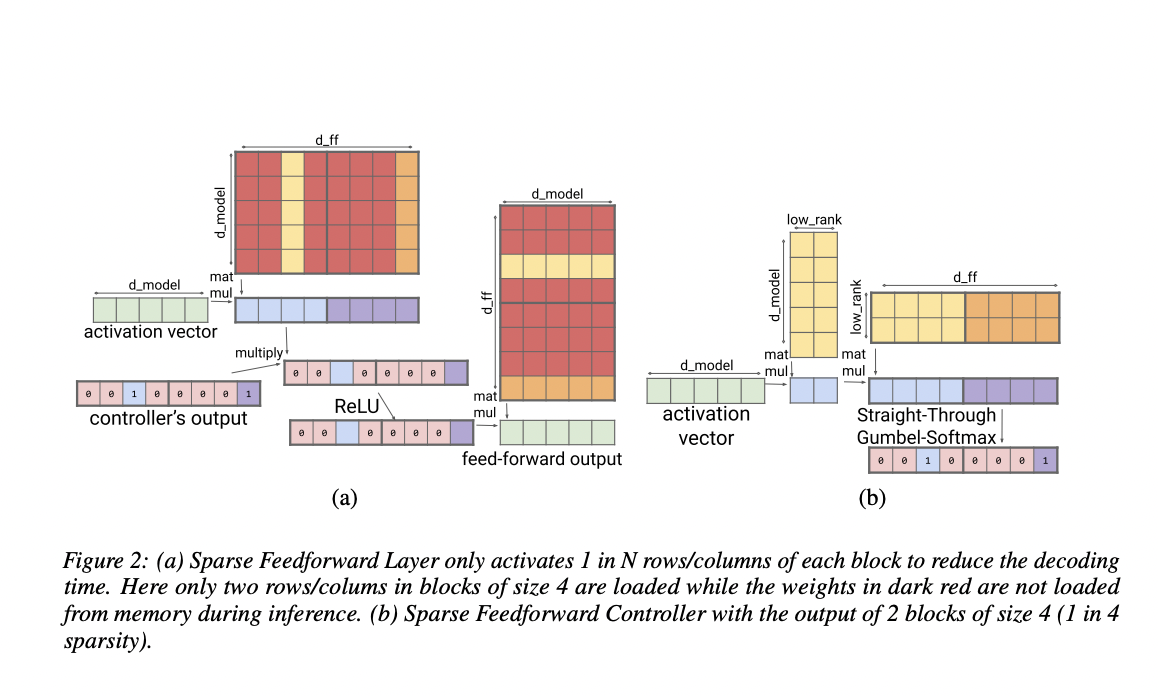
The team begins by creating sparse analogs for the feedforward blocks, the dense QKV (query, key, value) and output layers in attention, and the final dense layer before the softmax and loss. This process is undertaken to prevent the non-sparse parts of a transformer model from dominating decoding time and becoming a roadblock.
The team proposed dividing the layer’s dimensionality (d) into S modules of size; M = d/S to make QKV layers sparse, analogous to splitting an activation vector into many heads. These modules can be handled with a convolutional layer with fewer weights and run faster.
However, this design can access only a tiny part of a given token embedding. To address this, the researchers created a multiplicative layer that can represent any permutation and has fewer parameters, and takes less time to compute than a thick layer. This multiplicative layer comes before the convolutional layer and allows each head to access any embedding section. With this solution, decoding time is reduced while perplexity is maintained.

On the other hand, model scaling isn’t the only aspect contributing to high computing costs. This is because the long-sequence processing necessitates a high level of attention complexity and can take up a significant amount of decoding time. The team uses a previous LSH (locality-sensitive Hashing) attention paradigm to gain a sustainable competitive advantage. This combines the sparse attention mechanism with recurrent blocks in a Scaling Transformer to produce their final model, Terraformer, as the study team calls it.
Terraformer achieves a decoding speed of 0.086s with similar perplexity performance to the original Transformer’s decoding speed of 0.061s on long-sequence-processing workloads. Terraformer achieves accuracy faithful to the original transformer model on various downstream tasks on the GLUE dataset. In addition, Terraformer obtains a 37x decoding speedup when the model is scaled to 17B parameters.
The sparse models perform as well as their dense counterparts while inferring at a much faster rate. When the models are scaled up, the benefits of sparsity become much more apparent. The current findings have several flaws. One drawback is that the observed practical speedups are just for inference, not training. Furthermore, the researchers investigated unbatched inference on CPUs, whereas inference on GPUs is frequently made in batched mode.
The fundamental result indicates that sparse models with the same parameters achieve the same perplexity as their dense counterparts. Hence, the researchers anticipate that with more work, sparsity can improve these settings as well.
The researchers expect the community to be inspired by Scaling Transformers and adapt them to their specific needs. With correct tuning and subsequent enhancements, a Scaling Transformer might be trained to rival GPT-3 in accuracy while making inferences on a laptop in an acceptable amount of time. This is an intriguing topic of discussion for the community, as Scaling Transformers will be more sustainable and make huge models more accessible to everyone.
Paper: https://arxiv.org/pdf/2111.12763.pdf
Suggested
Credit: Source link
Comments are closed.