Google AI’s New Study Focusses on Understanding What Linguistic Information is Captured by Language Models?

Language models which are pre-trained, such as BERT and GPT-3, have been getting increasingly popular in Natural Language Processing (NLP) in recent years. Language models gain comprehensive knowledge about the world through training on vast volumes of text, resulting in a good performance on many NLP benchmarks. On the other hand, these models are frequently opaque, making it difficult to understand why they perform so well, restricting further hypothesis-driven model improvement. As a result, a new area of science has emerged to investigate the level of linguistic knowledge possessed by each of these models.
While there are many different types of linguistic data to investigate, the subject-verb agreement grammar rule in English, which states that a verb’s grammatical number must match that of the subject, is one that provides a solid platform for research. “The cats run.” is grammatically correct because “cats” and “run” are both plural verbs, but “The cats runs.” is incorrect because “runs” is a singular verb.
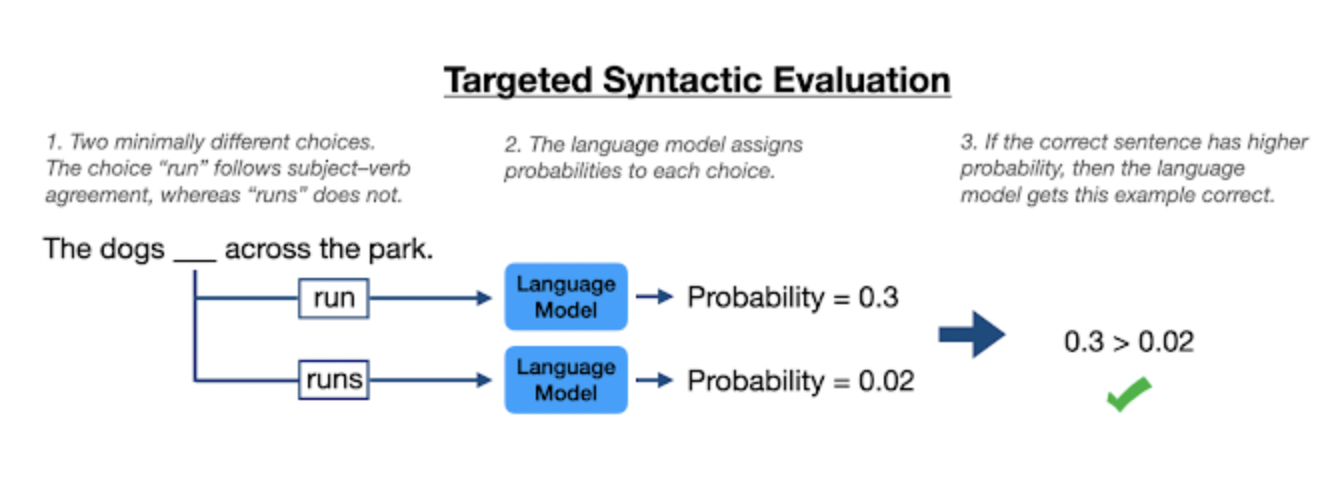
Targeted syntactic evaluation (TSE) is a methodology for evaluating a language model’s linguistic knowledge, in which a model is provided minimally different pairs of phrases, one grammatical and one ungrammatical, and the model must detect which one is grammatical. TSE can be used to assess knowledge of the English subject-verb agreement rule by asking the model to choose between two versions of the identical sentence, one in which a verb is written in its single form and the other in its plural form.
In “Frequency Effects on Syntactic Rule-Learning in Transformers,” presented at EMNLP 2021, the team studied how the amount of times a BERT model sees the words during pre-training affects the model’s ability to correctly apply the English subject-verb agreement rule. BERT models were pre-trained from scratch using carefully controlled datasets to evaluate specific scenarios, according to the researchers. The researchers pre-trained BERT models from scratch using carefully controlled datasets to test specified circumstances. It was discovered that BERT performs well on subject-verb pairs that did not exist together in the pre-training data, implying that it learns to apply subject-verb agreement. However, when the incorrect form is substantially more common than the correct form, the model prefers to predict the incorrect form, demonstrating that BERT does not treat the grammatical agreement as a norm that must be obeyed. These findings aid in a better understanding of the advantages and disadvantages of pre-trained language models.
TSE was previously employed in a BERT model to assess English subject-verb agreement skills. This earlier study compared BERT to natural statements (from Wikipedia) and nonce sentences, which are grammatically correct but semantically meaningless, such as Noam Chomsky’s famous example “colorless green concepts slumber fiercely.” When testing syntactic abilities, nonce sentences are useful because the model cannot rely on superficial corpus statistics. On nonce sentences, BERT achieves an accuracy of more than 80% (much better than the random-chance baseline of 50%), indicating that the model had learned to apply the subject-verb agreement rule.
The researchers initially compared how well the model works on subject-verb pairs encountered during pre-training to examples where the subject and verb were never seen together in the same sentence. According to the researchers, BERT isn’t just mirroring what it sees during pre-training: making decisions based on more than just raw frequencies and generalizing to novel subject-verb combinations are evidence that the model has learned to apply some underlying subject-verb agreement rule.
The team also looked at how the frequency of a term affects BERT’s ability to utilize it correctly with the subject-verb agreement rule, going beyond only seen versus unseen. A set of 60 verbs was chosen for this study, and then various versions of the pre-training data were constructed, each engineered to contain the 60 verbs at a specified frequency, ensuring that the singular and plural forms occurred the same amount of times in each version. BERT can model the subject-verb agreement rule, but it needs to encounter a verb around 100 times before it can reliably utilize it with the rule, according to the researchers.
The team also wanted to know how BERT’s predictions are affected by the relative frequency of single and plural variants of a verb. If one form of the verb (for example, “fight”) appears significantly more frequently in the pre-training data than the other verb form (for example, “combats”), BERT is more likely to give the more common version a high probability, even if it is grammatically incorrect. To test this, the same 60 verbs as before, were employed but this time, the pre-training data was modified by changing the frequency ratio between verb forms from 1:1 to 100:1.
When the two forms are encountered the same number of times during pre-training, BERT performs well in predicting the proper verb form, but the results deteriorate as the frequency imbalance increases. This means that, despite learning how to apply the subject-verb agreement, BERT does not always employ it as a “rule,” choosing instead to anticipate high-frequency terms regardless of whether they break the subject-verb agreement constraint.
Conclusions
TSE is used to evaluate BERT’s performance on syntactic tests, revealing its language ability. Furthermore, examining BERT’s syntactic ability in relation to the frequency with which words appear in the training dataset reveals how it manages competing priorities: it understands that subjects and verbs should agree and that high-frequency words are more likely, but it doesn’t understand that agreement is a rule that must be followed and that frequency is merely a preference. This study adds to the understanding of how language models reflect the qualities of the datasets they are trained on.
Paper: https://arxiv.org/abs/2109.07020
Reference: https://ai.googleblog.com/2021/12/evaluating-syntactic-abilities-of.html
Suggested
Credit: Source link
Comments are closed.