Google AI’s ‘TokenLearner’ Can Improve Vision Transformer Efficiency And Accuracy

Transformer models consistently obtain state-of-the-art computer vision tasks, including object detection and video classification. In standard convolutional approaches, images are processed pixel-by-pixel. To obtain visual tokens, this method uses hand-designed splitting algorithms. It entails processing a large number of densely sampled patches.
Instead of taking the traditional way, Google AI developed a method for extracting critical tokens from visual data. The Vision Transformers (ViT) is a technique developed by researchers to quickly and accurately locate a few key visual tokens. It allows for the modeling of paired attention between such tokens over a longer temporal horizon in the case of videos or the spatial content in the case of photos. An image is treated by the Vision Transformers (ViT) as a series of patch tokens. A token is a tiny portion of an image made up of multiple pixels, often known as a “patch.”
Using multi-head self-attention, a ViT model recombines and processes patch tokens at each layer based on relationships between each pair of tokens. ViT models can generate a global representation of the entire image in this way.
The tokens are created at the input level by uniformly splitting the image into numerous pieces. The outputs from the previous tier become the tokens for the next layer at the intermediate levels. The total quality of the Vision Transformer is determined by the amount and quality of the visual tokens.
The fundamental issue with many Vision Transformer systems is that they often require excessive tokens to achieve acceptable results. This is because the Transformer calculation scales quadratically with the number of tokens. For films with many frames, this means that each layer must handle tens of thousands of tokens. Transformers can become intractable for larger photos and longer films.
Is processing that many tokens at each tier essential?
The researchers show that creating a reduced number of tokens adaptively is the future. TokenLearner is a learnable module that generates a limited set of tokens from an image-like tensor (i.e., input). This module might be deployed in various places throughout the model of interest, significantly lowering the number of tokens that need to be handled in the following levels. TokenLearner has several advantages, one of which is that it saves much memory. It is a better alternative than depending on tokens created by uniform splitting. It allows Vision Transformers to run significantly faster and perform better.
The TokenLearner
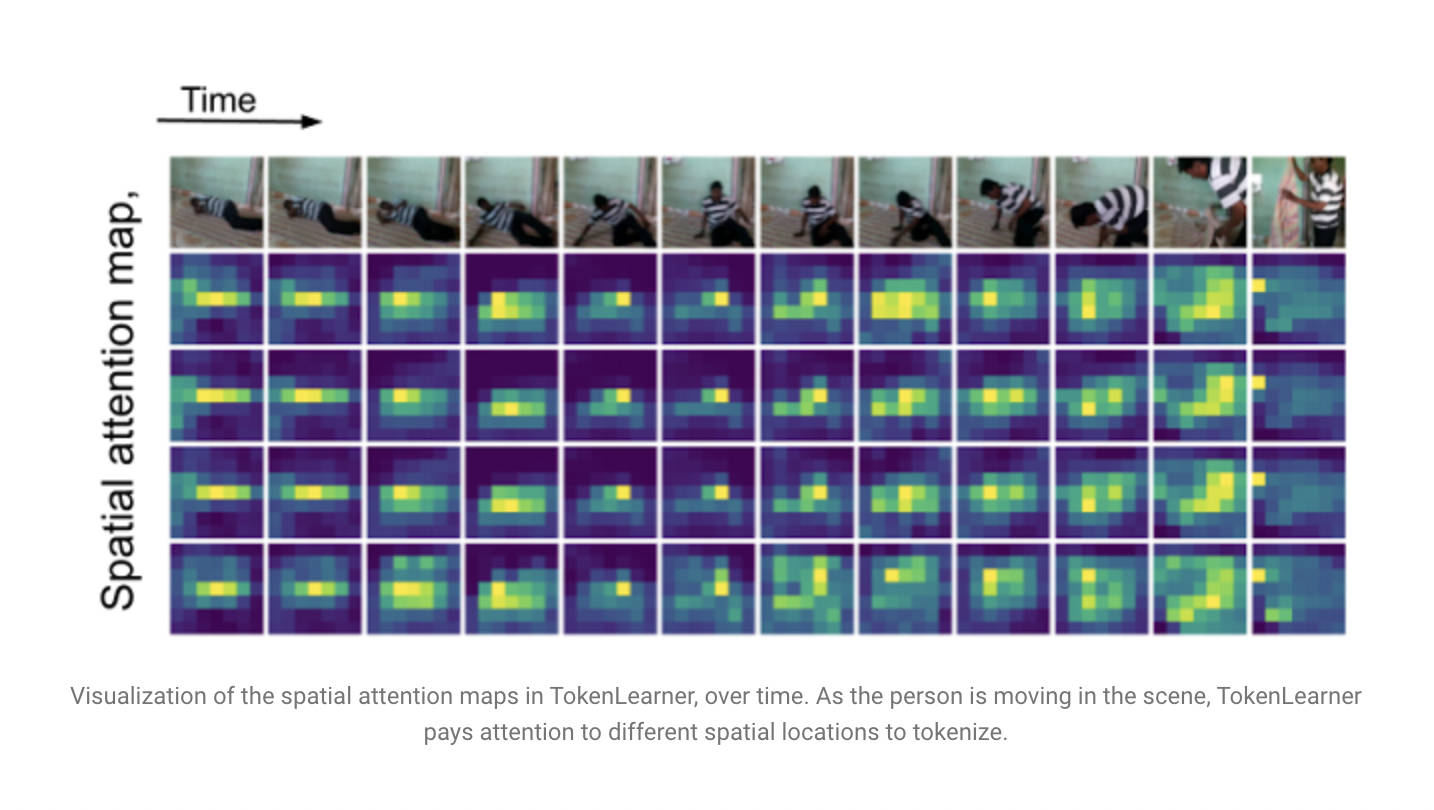
The researchers use convolutional layers to create a spatial attention map that highlights regions of interest to build each learned token. The input is subsequently subjected to a spatial attention map of some form, which weights each location differently. Unnecessary regions are also removed during the process, and the output is spatially pooled to form the final learned tokens.
This operation is repeated numerous times, yielding a few (10) tokens from the original input. It is also possible to consider it a soft selection of pixels based on weight values, followed by global average pooling. Different sets of learnable parameters govern the functions that compute the attention mappings, and they are trained end-to-end. This enables the attention functions to be optimized to capture various spatial information in the input.
TokenLearner allows models to process a smaller set of tokens relevant to the recognition job at hand. This method of processing has two advantages:
- It allows for adaptive tokenization, allowing tokens to be dynamically picked based on the input.
- Furthermore, it effectively reduces the total quantity of tokens, considerably decreasing the network’s computation.
Position of TokenLearner:
Initially, the researchers used 224×224 pictures in various spots within the typical ViT architecture. TokenLearner generated 8 and 16 tokens, far fewer than the 196 or 576 tokens used by typical ViTs.
TokenLearner is inserted after the first quarter of the network and achieves nearly equal accuracy as the baseline. At the same time, it cut the computation time in half compared to the previous method. Furthermore, utilizing TokenLearner after the third quarter of the network offers even better performance while running faster due to its adaptiveness, compared to not using TokenLearner. The relative computation of the transformers after the TokenLearner module becomes negligible. It is due to the significant difference in tokens before and after TokenLearner (e.g., 196 before and eight after).
Comparing Against ViTs:
TokenLearner was inserted at various points in the middle of each ViT model, such as 1/2 and 3/4. In terms of both accuracy and computation, TokenLearner models outperform ViT.
TokenLearner was also incorporated into larger ViT models, and the results were compared to the huge ViT G/14 model. TokenLearner was used on ViT L/10 and L/8, ViT models with 24 attention layers and initial tokens of 10×10 (or 8×8) patches. TokenLearner performs similarly to the huge G/14 model with 48 layers, although having fewer parameters and requiring less processing.
Other Applications:
One of the most fundamental difficulties in computer vision is video interpretation. Videos give more information to the image recognition problem by including a temporal component that allows for motion and other data.
Multiple video classification datasets were used to test TokenLearner. Video Vision Transformers (ViViT), which can be considered as a Spatio-temporal variant of ViT, now includes TokenLearner. Per timestep, TokenLearner learns 8 (or 16) tokens. TokenLearner achieves state-of-the-art (SOTA) performance on numerous prominent video benchmarks when paired with ViViT.
The whole motive behind this project is to show that retaining such a large number of tokens and fully processing them over the entire set of layers is not necessary. The researchers also aim to convey that learning a module that extracts tokens adaptively based on the input image allows obtaining even better performance while saving extensive computation.
Paper: https://arxiv.org/pdf/2106.11297.pdf
Github: https://github.com/google-research/scenic/tree/main/scenic/projects/token_learner
Reference: https://ai.googleblog.com/2021/12/improving-vision-transformer-efficiency.html
Suggested
Credit: Source link
Comments are closed.