Google AI Introduces ‘GSPMD’: A Largely Automated Parallelization System For Machine Learning Computation Graphs
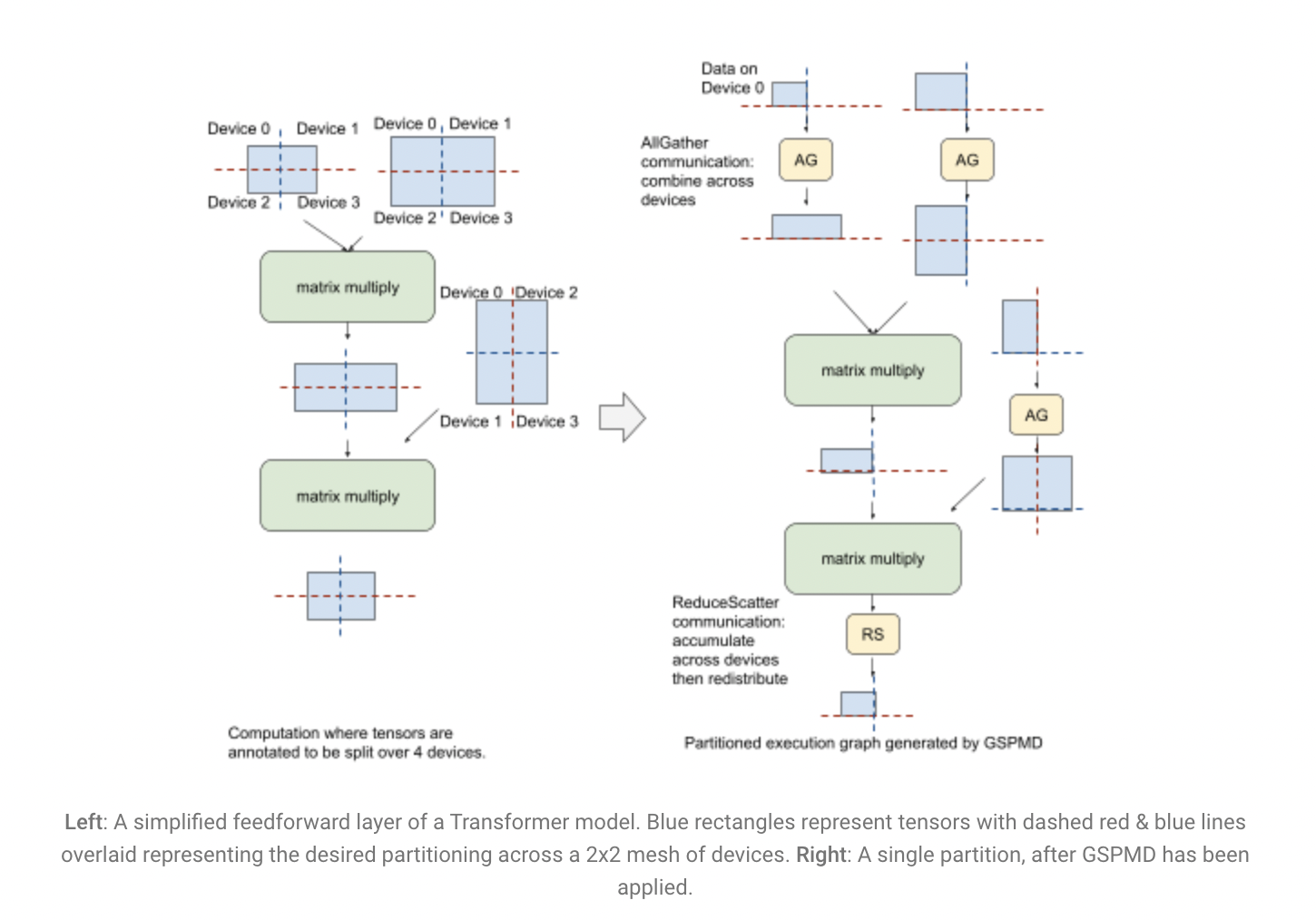

In many machine learning (ML) applications of the real world, such as language understanding, computer vision, and neural machine translation, scaling neural networks, whether it’s the amount of training data used, the model size, or the computing used, has been crucial for improving model quality. As a result, recent studies have looked into the parameters that play a key influence in the effectiveness of scaling a neural model.
Although expanding model capacity is a good way to improve model quality, it comes with a variety of systems and software engineering problems to address. For example, in order to train big models that surpass an accelerator’s memory capacity, the weights and computation of the model must be partitioned across numerous accelerators. This parallelization method increases network connection overhead, leading to device underutilization. Furthermore, a given parallelization approach, which normally necessitates a large amount of engineering effort, may not be compatible with other model designs.
Google research team introduces GSPMD (General and Scalable Parallelization for ML, Computation Graphs). The researchers describe an open-source automatic parallelization system based on the XLA compiler, to address these scalability difficulties. GSPMD can scale most deep learning network designs and has already been used to a number of deep learning models, including GShard-M4, LaMDA, BigSSL, ViT, and MetNet-2, producing state-of-the-art results in a variety of applications. GSPMD has also been included in a number of machine learning frameworks, such as TensorFlow and JAX, which both use XLA as a shared compiler.
GSPMD removes the issue of parallelization from the task of programming an ML model. Model developers can build programs as though they were running on a single device with a lot of memory and processing power — all they need to do is add a small number of lines of annotation code to a subset of essential tensors in the model code to tell it how to split the tensors. This allows users to concentrate on model development rather than parallelization implementation, and it makes it simple to migrate current single-device programs to bigger scales. Model programming and parallelism are separated, which allows developers to reduce code duplication.
Developers can utilize alternative parallelism algorithms for different use cases without reimplementing the model using GSPMD. As different model designs may benefit from different parallelization tactics, GSPMD is built to enable a wide range of parallelism algorithms suitable for various use cases. For example, Data Parallelism is favored in devices that train the same model using separate input data with smaller models that fit within the memory of a single accelerator. Models larger than a single accelerator’s memory capacity, on the other hand, are better suited to a Pipelining Algorithm (like GPipe’s) that divides the model into multiple, sequential stages. Operator-level Parallelism like Mesh-TensorFlow, in which individual computation operators in the model are divided into smaller, parallel operators, can also be used in this case. GSPMD also encourages parallelism algorithm innovation by allowing performance experts to concentrate on algorithms that make the most use of hardware rather than implementations that require a lot of cross-device communication.
For example, for large Transformer models, the researchers devised a novel operator-level parallelism technique that separates multiple dimensions of tensors on a 2D mesh of devices. It minimizes peak accelerator memory usage linearly with the number of training devices while retaining high utilization of accelerator computing due to its balanced data dissemination across various dimensions.
GSPMD also allows users to easily switch between parallelism modes in various regions of a model by providing a shared, resilient method. This is useful for models especially with many components that have varying performance characteristics, such as multimodal models that handle both pictures and sounds. Consider a model using the Transformer encoder-decoder architecture, which includes an embedding layer, a Mixture-of-Expert encoder stack, a dense feedforward decoder stack, and a final softmax layer. With simple configurations in GSPMD, a complicated combination of various parallelism modes that considers each layer individually can be produced, which in itself is a great achievement.
In large model training, GSPMD delivers industry-leading results. To coordinate numerous devices to do the computation, parallel models necessitate additional communication. Thus, the amount of time spent on communication overhead may be used to measure parallel model efficiency — the greater the percentage utilization and the less time spent on communication, the better. An encoder-only model which resembles BERT with 500 billion parameters that the team applied GSPMD for parallelization over 2048 TPU-V4 chips provided extremely competitive results in the current MLPerf set of performance benchmarks, leveraging up to 63 percent of the peak FLOPS that the TPU-V4s offer.
Many important machine learning applications, such as natural language processing, speech recognition, machine translation, and autonomous driving, rely on reaching the maximum level of accuracy feasible. Google’s publication on GSPMD is one of the steps in achieving this goal.
Paper: https://arxiv.org/pdf/2105.04663.pdf
Reference: https://ai.googleblog.com/2021/12/general-and-scalable-parallelization.html
Suggested
Credit: Source link
Comments are closed.