Understanding AlphaZero Neural Network’s SuperHuman Chess Ability


As a common and (sometimes) proven belief, deep learning systems seem to learn uninterpretable representations and are far from human understanding. Recently, some studies have highlighted the fact that this may not always be applicable, and some networks may be able to learn human-readable representations. Unfortunately, this ability could merely come from the fact that these networks are exposed to human-generated data. So, to demonstrate their ability to learn like humans (and not that they are simply memorizing human-created labels), it is necessary to test them without any label.
Following this idea, the DeepMind and Google Brain teams, together with the 14th world chess champion Vladimir Kramnik, studied their creature AlphaZero from this point of view. AlphaZero is the descendant of AlphaGo, the super neural network that beat the world champion Lee Sedol in a best-of-five GO match, a turning point in the history of deep learning, as can also be seen in the wonderful Netflix documentary AlphaGo.
Unlike AlphaGo, AlphaZero is trained through self-play (i.e., it learns to play competing against itself) and masters not only GO but also chess and shogi. This trait makes AlphaZero the perfect case study to explore this idea. Moreover, given the fact that it performs at a superhuman level, understanding its functionality is also particularly useful for highlighting unknown patterns which have never been discovered by chess theorists.
AlphaZero is composed of a CNN (convolutional neural network) based on ResNet50, which has two branches and computes a policy (p) and a value (v) and a Monte Carlo tree search to evaluate the state and update its action selection rule. p contains the probabilities associated with possible next moves, and v is a value that predicts the outcome of the game (win, lose or draw). As can be seen from the image below, the network takes an input of shape 8 x 8 x d, whose number of channels d depends on the parameter h (in the paper, h=8), which represents the number of previous positions considered. Different channels encode different information, such as who has the white pieces or the number of moves played.

Three approaches were conducted to investigate the capability of this architecture to acquire chess knowledge: 1) screening for human concepts, 2) studying behavioral changes, and 3) exploring activation.
1. Screening for human concepts
The aim is to find out if the internal representation (i.e., the activations) of AlphaZero can be related to human chess concepts. Concepts can vary from the basic, such as the existence of a passed pawn, to the more complex, such as the mobility of pieces.
Most of the concepts were retrieved from the evaluation function of Stockfish (a very famous hard-coded chess engine). Using a method based on sparse linear regression, the authors were able to compute the what-when-where (what concept is learned, when it was learned during training, and wherein the network) plots.

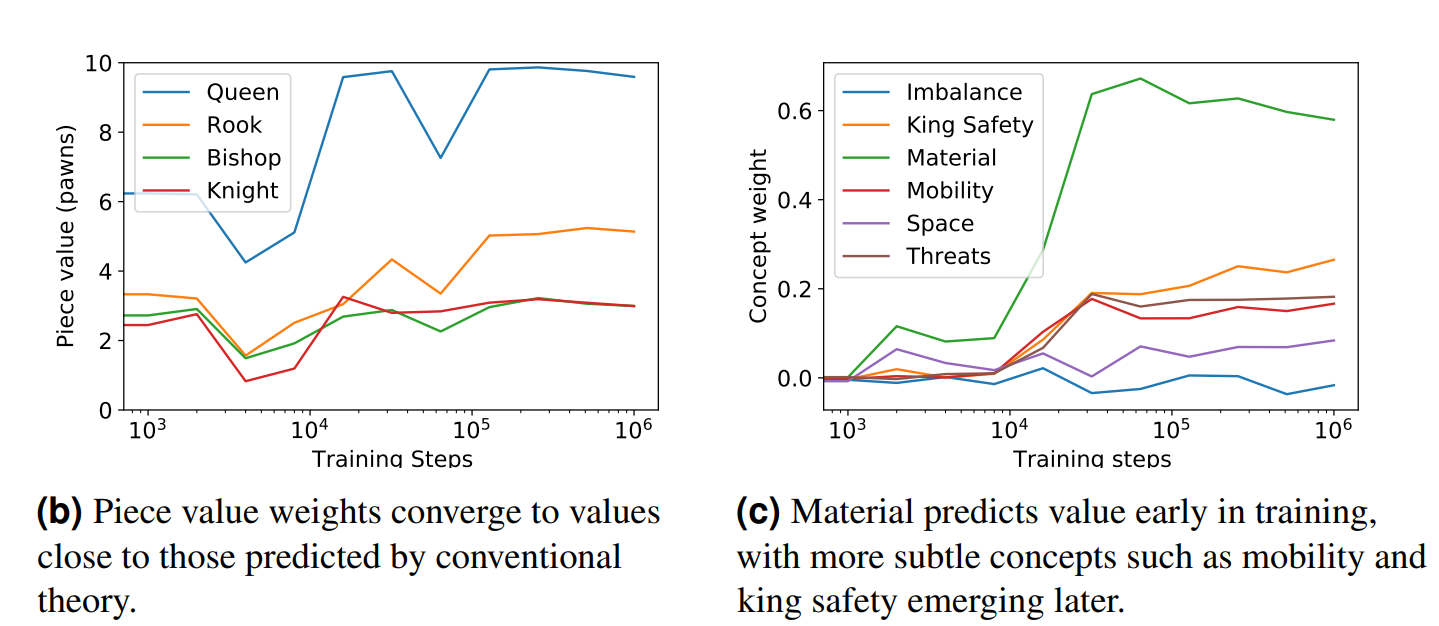
To demonstrate that AlphaZero develops representations that are closely related to human concepts over the training, the authors evaluated how much importance AlphaZero gives to different pieces and to different basic chess concepts during the training. It can be seen in the figure above how the value assigned to different pieces reaches the conventional theory (9-10 the queen, 5 the rooks, and 3 the knights and the bishops) and how some concepts become more and more important after a considerable number of steps, very close to how a human improve his way of playing.
2. Studying behavioral changes
The objective is to investigate, focusing on chess openings, which are highly theorized, how internal representations evolve over time and subsequently a) relate them to progression through human history b) study the behaviors change in relation to these changing representations.
- When the progression of AlphaZero was compared to the one of human games played after the 15th century (the first game in the dataset was played in 1475!), it was discovered that human players, during the different centuries, tend to focus on a specific opening and play it as default and then branch into different variations, while AlphaZero tries out a wide array of opening moves already in the early stages. A focus was also conducted on the famous Ruy Lopez opening (for chess players: 1. e4 e5, 2. Nf3 Nc6, 3. Bb5) where AlphaZero’s preferences and human knowledge can take different paths. The Berlin defense, which today is considered one of the most effective continuations, rapidly became AlphaZero’s favorite answer to the Ruy Lopez opening, while it took centuries for humans to understand deeply the Berlin defense.
- A very interesting qualitative assessment was also performed by the GM Vladimir Kramnik, who tried to understand different behaviors of AlphaZero related to the training steps done and, therefore to the evolving internal representations. The GM evaluated games played by two AlphaZero trained with a different number of iterations (k). From the comparison between AlphaZero-16k and AlphaZero-32k, Kramnik easily deduced that AlphaZero-16k has a quite basic understanding of material value, which often led to unwanted exchange sequences. From the games between AlphaZero-32k and AlphaZero-64k, came out that the main difference probably lies in the understanding of king safety in unbalanced positions. Finally, from AlphaZero-64k versus AlphaZero-128k, king safety re-emerges, and AlphaZero-128k has a much deeper understanding of which attacks will succeed and which will fail.
3. Analyzing activations
The third aim is to explore activation directly with unsupervised methods instead of the first two approaches. Indeed, the fact that the first two methods are supervised entails the risk of not finding relationships or concepts that have not been included in the dataset.
Hence, through non-negative matrix factorization (NMF), the authors were able to visualize patterns not related to labeled human data, by analyzing the model formerly trained for concept screening in a concept-agnostic (i.e., unsupervised) manner. Given a specific board position, the visualization process highlights the most fundamental squares considered by the network in evaluating the position, as shown in the figure below. Not all results were interpretable with a certain level of confidence (for example the column (d) has a high level of uncertainty) while some possible interpretations were given to other activations. For example, columns (a) and (b) show the development of diagonal moves for white and black respectively; column (c) probably shows a more complex factor: the number of opponent’s pieces that can move to a specific square (the darker the square, the more piece can move in that square).

Conclusion
This paper was a first step into the comprehension of complex systems such as AlphaZero. The next step is summarized at the end of the paper with the following sentence:
“Can we go beyond finding human knowledge and learn something new?”
Paper: https://arxiv.org/pdf/2111.09259.pdf
Suggested
Credit: Source link
Comments are closed.