Microsoft Research Introduces ‘BugLab’: A Deep Learning Model to Detect and Fix Bugs Without Using Labelled Data

Finding and repairing problems in code is a time-consuming and frequently unpleasant element of software engineers’ day-to-day work. Can deep learning solve this challenge and help engineers offer better software faster? In a new study, Self-Supervised Bug Detection and Repair, presented at the 2021 Conference on Neural Information Processing Systems (NeurIPS 2021), a promising deep learning model was proposed called BugLab. BugLab can be trained to find and repair flaws without the need for labeled data by playing a “hide and seek” game.
Finding and fixing flaws in code necessitates not just thinking about the structure of the code but also interpreting confusing natural language cues left by software engineers in code comments, variable names, and other places. For example, the code snippet below resolves an issue in a GitHub open-source project.
The developer’s aim is evident here, thanks to the natural language comment and the high-level structure of the code. However, a flaw crept through, and the incorrect comparison operator was utilized. The deep learning model correctly identified this problem and notified the developer.
In another open-source project, the code (below) wrongly examined if the variable write_partitions was empty rather than the proper variable read_partition.
The research aims to create better AI that can automatically detect and correct flaws like those described above, which appear simple but frequently challenging to identify. Freeing developers from this duty allows them to focus on other crucial (and fascinating) aspects of software development. However, detecting defects – even seemingly minor ones – can be tricky since a piece of code does not often come with a clear explanation of its intended behavior. A lack of training data complicates teaching machines to identify flaws automatically. While large volumes of program source code are available on sites like GitHub, only a few remote databases contain explicitly marked problems.
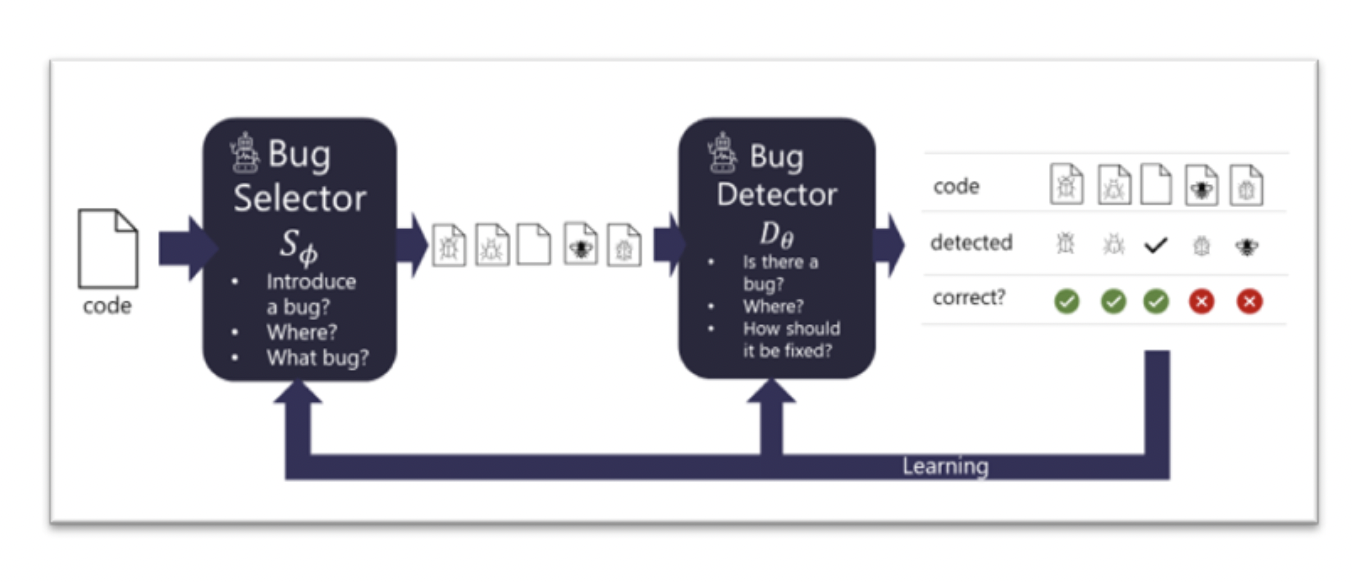
BugLab can be employed to address this issue, which uses two competing models that learn by engaging in a “hide and seek” game inspired by Generative Adversarial Networks (GAN). Given some presumptively valid existing code, a bug selector model determines whether or not to introduce a problem, where to present it, and its particular form (e.g., replace a specific “+” with a “-“). The code is changed to introduce the problem based on the selector option. The bug detector model then attempts to assess whether a bug was introduced in the code and locate and repair it.
These two models are jointly trained on millions of code snippets without labeled data, i.e., in a self-supervised manner. The bug selector attempts to learn to “hide” interesting defects within each code snippet, while the detector attempts to outperform the selector by discovering and correcting them. During this process, the detector improves its ability to find and correct errors, while the bug selector learns to provide progressively difficult training samples.
In simple words, the “hide and seek” game may be viewed as a teacher-student paradigm. The selector attempts to “teach” the detector to discover and correct defects robustly.
GANs are fundamentally comparable to this training procedure. On the other hand, the bug selector does not build a new code snippet from the start but instead rewrites an existing piece of code (assumed to be correct). Furthermore, code rewrites must be discrete, and gradients cannot be transferred from the detector to the selector. In contrast to GANs, what is rather interesting is acquiring a good detector (similar to a GAN’s discriminator) than a good selection (identical to a GAN’s generator).
Results
In theory, the hide-and-seek game could be used to teach a machine to recognize arbitrarily complex bugs. However, such problems are still beyond the capabilities of contemporary Artificial Intelligence (AI) technologies. Instead, a subset of issues that emerge frequently was focused. Wrong comparisons (e.g., using “=” instead of “” or “>”), incorrect Boolean operators (e.g., using “and” instead of “or” and vice versa), variable abuse (e.g., using “i” instead of “j”), and a few more are examples. Python code was used to test the system.
Once trained, the detector was used to find and correct flaws in real-world code. And to assess the performance, a manually annotated small dataset of defects from Python Package Index packages were created with such bugs, and models trained with the “hide-and-seek” strategy outperformed other options, such as detectors trained with randomly inserted bugs, by up to 30%. The results were promising, indicating that around 26% of defects may be detected and corrected automatically. Among the issues discovered by the scanner were 19 previously undiscovered bugs in real-world open-source GitHub code. However, the findings revealed a high number of false-positive alerts, suggesting that further progress is required before such models can be used in practice.
How machine learning “understands” code?
Going further in detail in the detector and selector models. Curious about how deep learning models “understand” what a piece of code does? Previous research has demonstrated that expressing code as a sequence of tokens (approximately “words” of code) produces inferior outcomes. Instead, the code’s complex structure must be maintained, including syntax, data, and control flow. To do this, nodes in a graph can be utilized to represent items within the code (syntax nodes, expressions, identifiers, symbols, and so on) and show their relationships using edges.
Given such a representation, bug detectors and pickers could be trained using a variety of common neural network topologies. Although graph neural networks (GNNs) and relational transformers were employed in practice. These designs can use the graph’s complex structure and reason about the entities and their relationships. This study analyzes the two distinct model designs and discovers that GNNs outperform relational transformers in general.
Developing deep learning models to find and correct flaws is a critical challenge in AI research. A solution involves human-level knowledge of program code and contextual information like variable names and comments. The BugLab study demonstrated that by jointly training two models to play a hide-and-seek game, one can teach computers to be promising bug detectors, albeit much more effort is required to make such detectors dependable for practical usage.
Paper: https://arxiv.org/pdf/2105.12787.pdf
Github: https://github.com/microsoft/neurips21-self-supervised-bug-detection-and-repair
PyPiBugs Dataset: https://www.microsoft.com/en-us/download/103554
Reference: https://www.microsoft.com/en-us/research/blog/finding-and-fixing-bugs-with-deep-learning/
Suggested
Credit: Source link
Comments are closed.