OpenAI Researchers Find Ways To More Accurately Answer Open-Ended Questions Using A Text-Based Web Browser

Long-form question-answering (LFQA), a paragraph-length answer created in response to an open-ended question, is a growing difficulty in NLP. LFQA systems hold the potential to become one of the most important ways for people to learn about the world, yet their performance currently lags behind that of humans. Existing research has tended to concentrate on two key aspects of the task: information retrieval and synthesis.
Researchers at OpenAI have recently developed WebGPT. They outsource document retrieval to the Microsoft Bing Web Search API and use unsupervised pre-training to produce high-quality synthesis by fine-tuning GPT-3. Rather than striving to improve these factors, they concentrate on integrating them with more consistent training goals. The team leverages human feedback to directly enhance the quality of answers, allowing them to compete with humans in terms of performance.
In this paper, the team offers two significant contributions. They create a text-based web-browsing environment that can be interacted with by a fine-tuned language model. This enables the use of general approaches like imitation learning and reinforcement learning to improve both retrieval and synthesis in an end-to-end manner. The team also creates replies with references, sections collected by the model when exploring web pages. This is critical because it allows labelers to assess the factual accuracy of answers without having to engage in a time-consuming and subjective independent research procedure.
The models are primarily trained to answer questions from ELI5, a dataset of questions culled from the Reddit community “Explain Like I’m Five.” They also collect two types of data: examples of individuals answering questions using the web browser environment and comparisons of two model-generated replies to the same question (each with their own set of references). The accuracy, coherence, and general usefulness of the answers are evaluated.
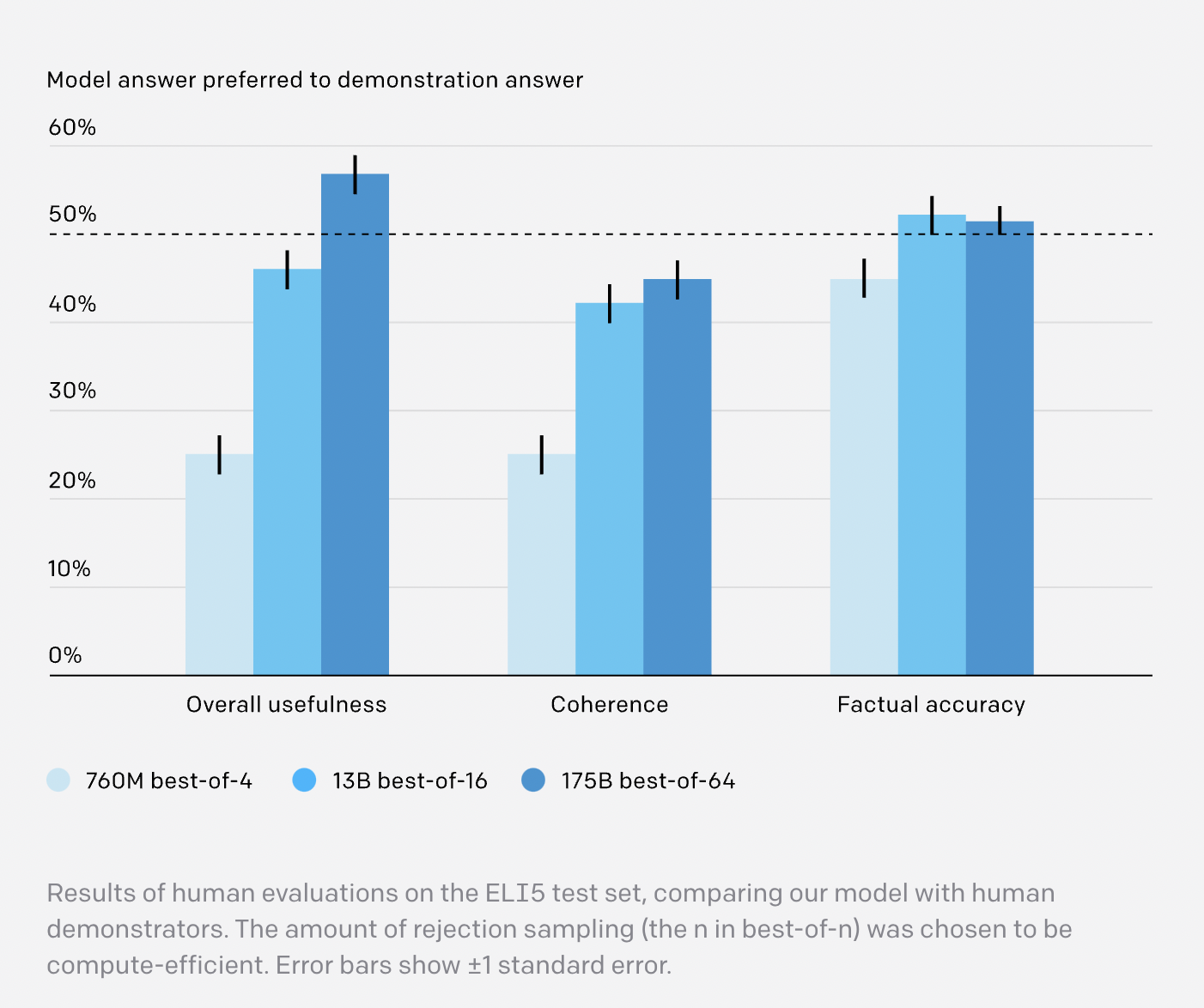
The demonstrations are used for behavior cloning (i.e., supervised fine-tuning), reward modeling is used for comparisons, reinforcement learning is used against the reward model, and rejection sampling is used against the reward model. A combination of behavior cloning and rejection sampling is used in the best model. The team finds that reinforcement learning can help when the inference-time computation is constrained.
Three methods are used to assess the model:
- The model’s responses are compared to responses written by the team’s human demonstrators on a series of questions that have been held out. The model’s responses are favored 56% of the time, indicating that the text-based browser is being used at a human level.
- The model’s results are compared to the ELI5 dataset’s highest-voted solution. Sixty-nine percent of the time, the model’s responses are preferred.
- The model is tested on TruthfulQA, a dataset of short-form questions that is adversarial.
The model’s answers are correct 75% of the time and both accurate and informative 54% of the time, beating the baseline model (GPT-3) but falling short of human performance.
Prior question-answering research, such as REALM and RAG focused on enhancing document retrieval for a specific query. Instead, the team employs a tried-and-true method: a modern search engine (Bing). This has two significant benefits. To begin with, modern search engines are already extremely powerful, indexing a considerable number of current documents. Second, it frees up the team to focus on the higher-level task of using a search engine to answer inquiries, which humans excel at and which a language model can replicate.
A text-based web-browsing environment was created for this method. A written summary of the current state of the environment, along with the query, the content of the current page at the current cursor location, and some other information, is presented to the language model. As a result, the model must issue one command, which can be anything from a Bing search to clicking on a link to scrolling around. After that, the process is repeated with a new context.
One of the activities the model can take when surfing is to quote an excerpt from the current page. The page title, domain name, and extract are logged during this process and can be used as a reference later. The surfing continues until the model issues a command to stop browsing, the maximum number of actions is reached, or the total number of references is reached. The model is prompted with the query and the references at this point and must create its final answer if there is at least one reference.
Experiments were also carried out to see how model performance differed depending on the size of the dataset, the number of model parameters, and the number of rejection samples employed. Because human evaluations can be noisy and expensive, these tests employed the score of a 175B “validation” reward model (trained on a separate dataset split).
Doubling the number of demonstrations boosted the policy’s reward model score by around 0.13, and doubling the number of comparisons enhanced the reward model’s accuracy by about 1.8 percent in terms of dataset size. The trends in parameter count were more erratic, although doubling the number of parameters in the policy raised its reward model score by around 0.09 and its accuracy by roughly 0.4 percent.
Conclusion
The OpenAI research team has presented an innovative approach to long-form question answering that involves fine-tuning a language model to leverage a text-based web-browsing environment. This enables the use of broad approaches like imitation learning and reinforcement learning to directly improve answer quality. Answers must be backed up by references gathered during surfing to make human judgment easier. Their most potent model outperforms humans on ELI5 but suffers from out-of-distribution queries using this method. As NLP systems improve and become more extensively used, developing ways for lowering the number of incorrect assertions they make becomes increasingly crucial, and WebGPT assists in finding a solution.
Paper: https://arxiv.org/pdf/2112.09332.pdf
Reference: https://openai.com/blog/improving-factual-accuracy/
Suggested
Credit: Source link
Comments are closed.