Researchers from the University of Chicago and Tel Aviv University Introduce ‘Text2Mesh’: A Novel Framework to Alter both Color and Geometry of 3D Meshes According to a Textual Target

")
In recent years, neural-based generative models have been at the center of attention for their exceptional capability of creating aesthetically attractive graphical content seemingly out of nowhere. Recent solutions of this kind, like VQGAN and in general all derivations of Generative Adversarial Networks and their combination with other Deep Learning techniques, like CLIP from OpenAI (a joint image-text embedding model), led to amazing results, using very complex and powerful generative techniques. With the advent of NFTs and the application of transformer-based techniques to computer graphics in videogames, the hype built during recent years for generative models might finally lead AI-generated art to meet the growing market demand in the field of entertainment.
The main perk of generative models, that is, their versatility in learning latent representations of given datasets, comes at the cost of higher complexity and lower success rate of training experiments. Researchers from the University of Chicago and Tel Aviv University Introduce the’ Text2Mesh’ model. The Text2Mesh model tries to avoid the above problem by proposing a non-generative method to alter the appearance of 3D meshes by using a “Neural Style Field” (NSF), learned with neural techniques, that maps vertices of an input mesh to RGB color and a local displacement along their normal direction, based on a text prompt that determines the style and appearance of the result. The model is powered by the CLIP joint text-image embedding space and appropriate regularization to avoid degenerate solutions.

Previous works have explored the manipulation of stylistic features for images or meshes using CLIP, such as StyleCLIP, that uses a pre-trained StyleGAN to perform CLIP-guided image editing, VQGAN-CLIP that leverages the joint text-image embedding space of CLIP to perform text-guided image generation or CLIPDraw, generating text-guided 2D vector graphics. Some approaches instead tried to alter stylistic features on 3D meshes: for example, 3DStyleNet edits shape content with a part-aware low-frequency deformation and synthesizes colors on a texture map, guided by a target mesh, while ALIGNet deforms a template shape to a target one. Differently, from previous models, which highly depend on the dataset used for training, Text2Mesh considers a wide range of styles, guided by a compact text specification.
Previous attempts at synthesizing a style for an input 3D mesh had to deal with the problem of guessing a correct texture parameterization (imagine having a 2D world map and having to fit it on a sphere). This approach overcomes this problem by generating the texture and local fine-grained displacements vertex-by-vertex, so there is no need to guess a mapping from points in a 2D shape to a 3D surface.
Text2Mesh uses the “Neural Style Field” as a “neural prior“, leveraging its inductive bias (that is the tendency of a neural network to “assume” that every sample presented to it exhibits characteristics that are common to the samples used for training) to drive the results away from degenerate solutions present in the CLIP embedding space (due to the many false positives in the association of images to text).
Vertices, that can be considered low-dimensional (as they’re represented by 3D vectors), are fed to a Multi-Layer Perceptron (MLP) to learn the Neural Style Field (that acts as a “style map” from a vertex to a color and a displacement along the normal direction). In cases in which the mesh has sharp edges or very detailed 3D features, this leads to the occurrence of spectral bias, that is the tendency of shallow networks to be unable to learn complex or high-frequency functions. Text2Mesh overcomes this problem by the use of a positional encoding based on Fourier feature mappings.
Text2Mesh also exhibits some emergent properties in its ability to correctly stylize parts of a mesh in accordance to their semantic role, as shown below: each part of the input mesh of a human body is correctly stylized, and the resulting styles of different body parts are seamlessly blended.

Given a 3D mesh, we can decouple content (its global structure defining the overall shape surface and topology) from style (determined by the object color and texture and by its local fine-grained geometric details). In this setting, Text2Mesh maps the content of a mesh to a style that best fits the descriptive text provided in input along with the 3D mesh.
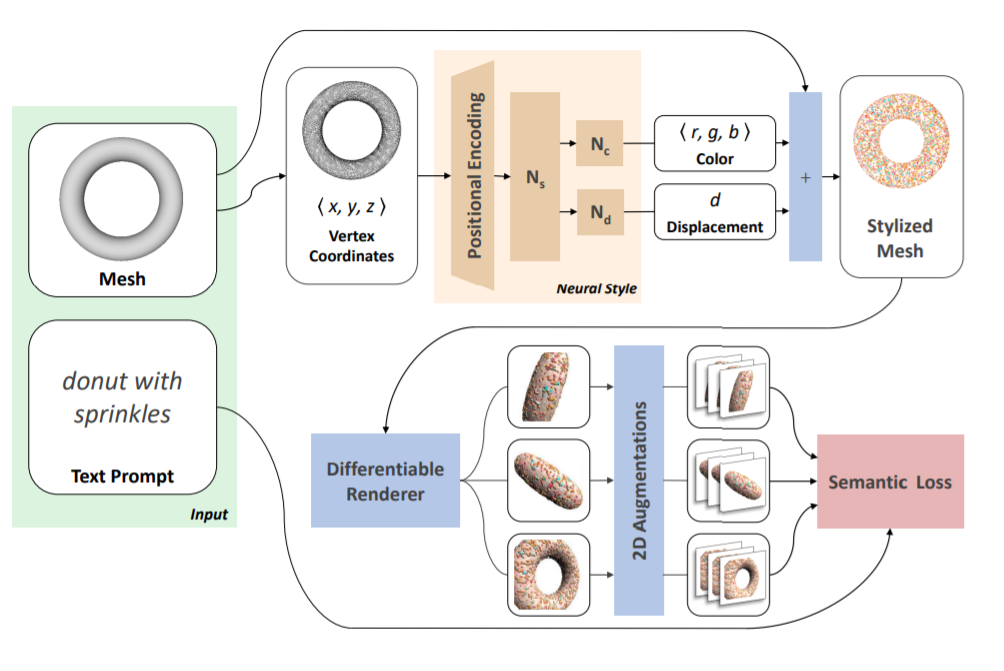
A mesh represented as a list of vertex coordinates and an input text prompt, that will serve as a description of the required target features, are provided as input to the model. The mesh will be fixed throughout the whole process and each text prompt requires of course a different training process.
First off, a positional encoding is applied to each vertex in the mesh: for every point p, the positional encoding is given by the following equation:
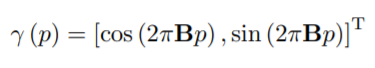
we can see that Fourier feature mappings are used to enable the neural network that learns the Neural Style Field to overcome spectral bias, in order to correctly synthesize high-frequency details. In this equation, B is a random Gaussian matrix where each entry is randomly sampled from a zero-mean Gaussian distribution with variance determined as a hyperparameter. We can see that by tuning this variance we change the range of input frequencies in the positional encoding, leading to higher-frequency details, like in the image below.

Typically, a standard deviation of 5.0 is used to sample the B matrix.
The obtained positional encoding is then fed to a Multi-Layer Perceptron with a 256-dimensional input layer, followed by other 3 256-dimensional hidden layers with ReLU activation. The neural network then branches into two 256-dimensional layers with ReLU activations: one branch is used to estimate the vertex color while the other one is used to estimate the vertex displacement. After a final linear layer, a tanh activation is applied to each branch, with both layers initialized to zero so that the original content mesh is unaltered at initialization. The color output prediction, which is in the output range of the tanh activation function (-1, 1), is divided by 2 and added to [0.5, 0.5, 0.5] (grey color) so that each color is in the range (0.0, 1.0) and also to avoid undesirable solutions in the early iterations of training. The displacement, which is also in the output range of the tanh activation function, is instead multiplied by 0.1 so that it lies in the range (-0.1, 0.1), to prevent content-altering displacements. Two meshes are now obtained: the first one, called the stylized mesh, is obtained by applying both color and vertex displacements to the original mesh, while the other one, called the displacement-only mesh, is obtained by only applying vertex displacements.
Now, the mesh is rendered at uniform intervals around a sphere, using a differentiable renderer, that is a renderer that allows the backpropagation of gradients, meant to be embedded in a neural network. For each render, the CLIP similarity with the target text prompt is computed and the render corresponding to the best similarity is chosen as an anchor view.
Other 2D renders, in a number that is determined as a hyperparameter (5 during the experiments) are now performed around the anchor view, at angles that are sampled using a Gaussian distribution centered on the anchor and with a variance of π/4. This process is performed for both the stylized mesh and the displacement-only mesh.
Next, two image augmentations are drawn from a set of possible augmentation parameters: a global one (that applies a random perspective transformation) and a local one (that crops the render to 10% of its original size and then applies a random perspective transformation). The global augmentation is applied to the renders of the stylized mesh, while the local augmentation is applied to both the renders of the stylized mesh and the displacement-only mesh.
The augmented renders are then embedded into CLIP space and the embeddings are averaged across all views, according to the following equations:
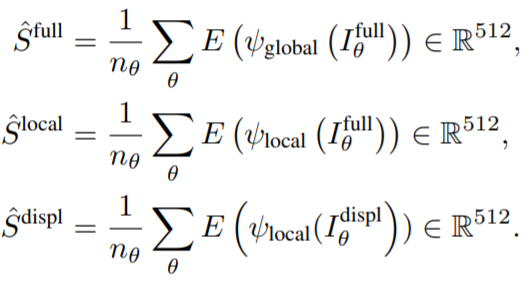
Where the I full and I displ terms are the original 2D renders and the embeddings are averaged over all rendered views once, with the global augmentation, for the stylized view and twice, with the local augmentation, for the stylized view and the displacement-only view. The resulting embeddings belongs in a 512-dimensional space. Next, the target text t is embedded too in CLIP space as follows:
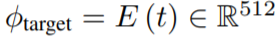
Finally, the semantic loss value is computed according to the following equation, simply by summing the cosine-similarity of the averaged embeddings of augmented 2D renders in CLIP space with the CLIP embedding of the target text:
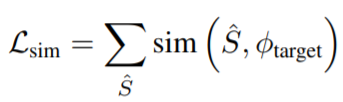
where:
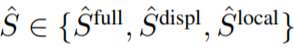
The above is repeated with new sampled augmentations for a certain number of times, determined as a hyperparameter, for each update of the Neural Style Field.
Experiments were performed using a wide variety of input source meshes (taken from various sources, including COSEG, Thingi10K, Shapenet, Turbo Squid, and ModelNet), also including low-quality meshes. Training required less than 25 minutes on a single Nvidia GeForce RTX2080Ti GPU, using Adam optimizer with learning decay. Various ablation studies, conducted by deactivating parts of the model, show that this combination of processing steps and this choice of hyperparameters leads to optimum performance.
This novel technique shows very interesting results and can be considered a major improvement over the specificity of previous applications of generative models to graphical and artistic tasks. Considering the high complexity of this task and the relatively low training time and computational resources required, this technology may open many new possibilities, especially in the field of videogames and entertainment, given the simultaneous interplay between content and styling of meshes and their underlying semantics. It might even contribute to fueling the creation of digital artistic content, with interesting implications in the newborn NFT marketplaces.
Paper: https://arxiv.org/pdf/2112.03221.pdf
GitHub: https://github.com/threedle/text2mesh
Project Page: https://threedle.github.io/text2mesh/
Suggested
Credit: Source link
Comments are closed.