UC Berkeley Researchers Introduce the Unsupervised Reinforcement Learning Benchmark (URLB)

Reinforcement Learning (RL) is a robust AI paradigm for handling various issues, including autonomous vehicle control, digital assistants, and resource allocation, to mention a few. However, even the best RL agents today are narrow. Most RL algorithms currently can only solve the single job they were trained on and have no cross-task or cross-domain generalization ability.
The narrowness of today’s RL systems has the unintended consequence of making today’s RL agents incredibly data inefficient. Agents overfit to a specific extrinsic incentive, limiting their ability to generalize in RL.
Unsupervised pre-training has shown to be the most promising method for generalist AI systems in language and vision to date. RL algorithms dynamically impact their data distribution, unlike vision and language models, which act on static data. Representation learning is crucial in RL. But the unsupervised difficulty that is unique to RL is how agents may generate interesting and diverse data through self-supervised purposes.
Unsupervised reinforcement learning is quite similar to supervised reinforcement learning. Both strive to maximize rewards and presume that the underlying environment is defined by a Markov Decision Process (MDP) or a Partially Observed MDP. However, supervised RL assumes that the environment provides supervision in the form of an extrinsic reward. In contrast, unsupervised RL defines an intrinsic incentive in the form of a self-supervised task.
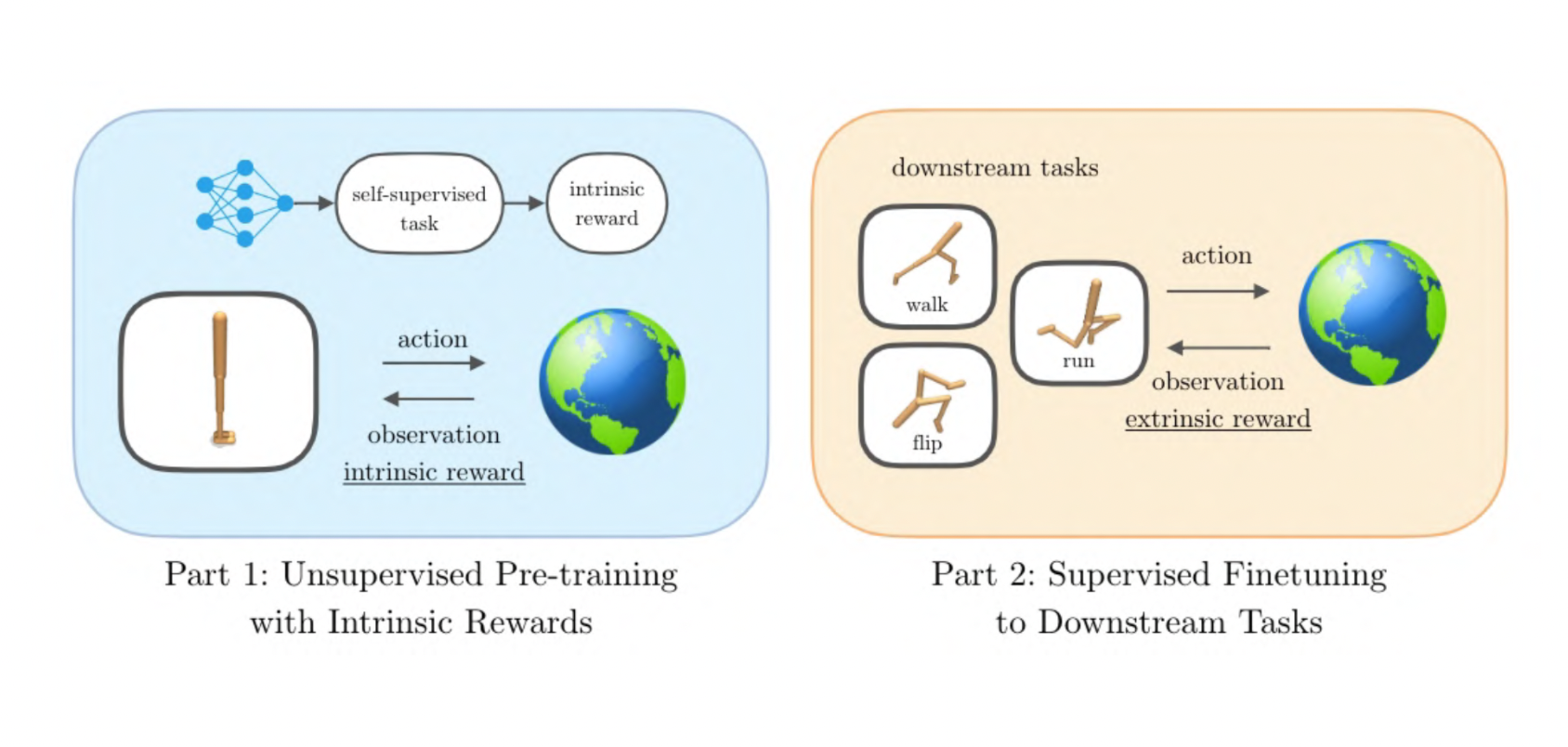
A team of researchers at the Robot Learning Lab (RLL) have been working to make unsupervised reinforcement learning (RL) a viable option for developing generalizable RL agents. To that purpose, they have created and released an unsupervised RL benchmark for 8 leading or popular baselines using open-source PyTorch code.
Several unsupervised RL algorithms have been suggested in recent years. But due to differences in assessment, environments, and optimization, it has been impossible to compare them objectively. As a result, the team presents URLB (The Unsupervised Reinforcement Learning Benchmark) a tool that offers defined evaluation processes, domains, downstream tasks, and optimization for unsupervised RL algorithms.
URLB divides training into two stages:
- An unsupervised pre-training phase
- A supervised fine-tuning phase.
In the initial edition, there are three domains, each with four tasks, for 12 downstream tasks to evaluate.
The majority of unsupervised RL algorithms can be divided into three types:
- Knowledge-based: Maximize the prediction error or uncertainty of a predictive model
- Data-based: Maximise the diversity of observed data
- Competence-based: Maximize the mutual information between states and some latent vector (often referred to as the “skill” or “task” vector).
Previously, several optimization algorithms were used to implement these algorithms. As a result, comparing unsupervised RL algorithms has proved difficult. The team standardizes the optimization technique in their implementations so that the self-supervised objective is the only difference across different baselines.

On domains based on the DeepMind Control Suite, the team has implemented and released code for eight prominent algorithms that support both state and pixel-based observations.

Based on benchmarking existing methodologies, they’ve also highlighted a number of intriguing research directions for the future. Competence-based exploration, for example, underperforms data and knowledge-based exploration as a whole, which is a fascinating area of study.
Paper: https://openreview.net/pdf?id=lwrPkQP_is
Github: https://github.com/rll-research/url_benchmark
Reference: https://bair.berkeley.edu/blog/2021/12/15/unsupervised-rl/
Suggested
Credit: Source link
Comments are closed.