ETH Zurich Team Introduce Exemplar Transformers: A New Efficient Transformer Layer For Real-Time Visual Object Tracking
Visual tracking involves estimating the trajectory of an object in a video series, which is one of the fundamental challenges in computer vision. With deeper networks, more accurate bounding boxes, and new modules, deep neural networks have considerably improved the performance of visual tracking systems. These advancements, however, frequently come at the expense of more costly versions.
While there is a growing demand for real-time visual tracking in applications like autonomous driving, robotics, and human-computer interfaces, efficient deep tracking architectures have gotten surprisingly little attention. This necessitates visual trackers that are both precise and robust while still operating in real-time under the constraints of minimal hardware.
ETH Zurich researchers have developed Exemplar Transformers, a new efficient transformer layer for real-time visual object tracking that is up to 8 times faster than other transformer-based models.
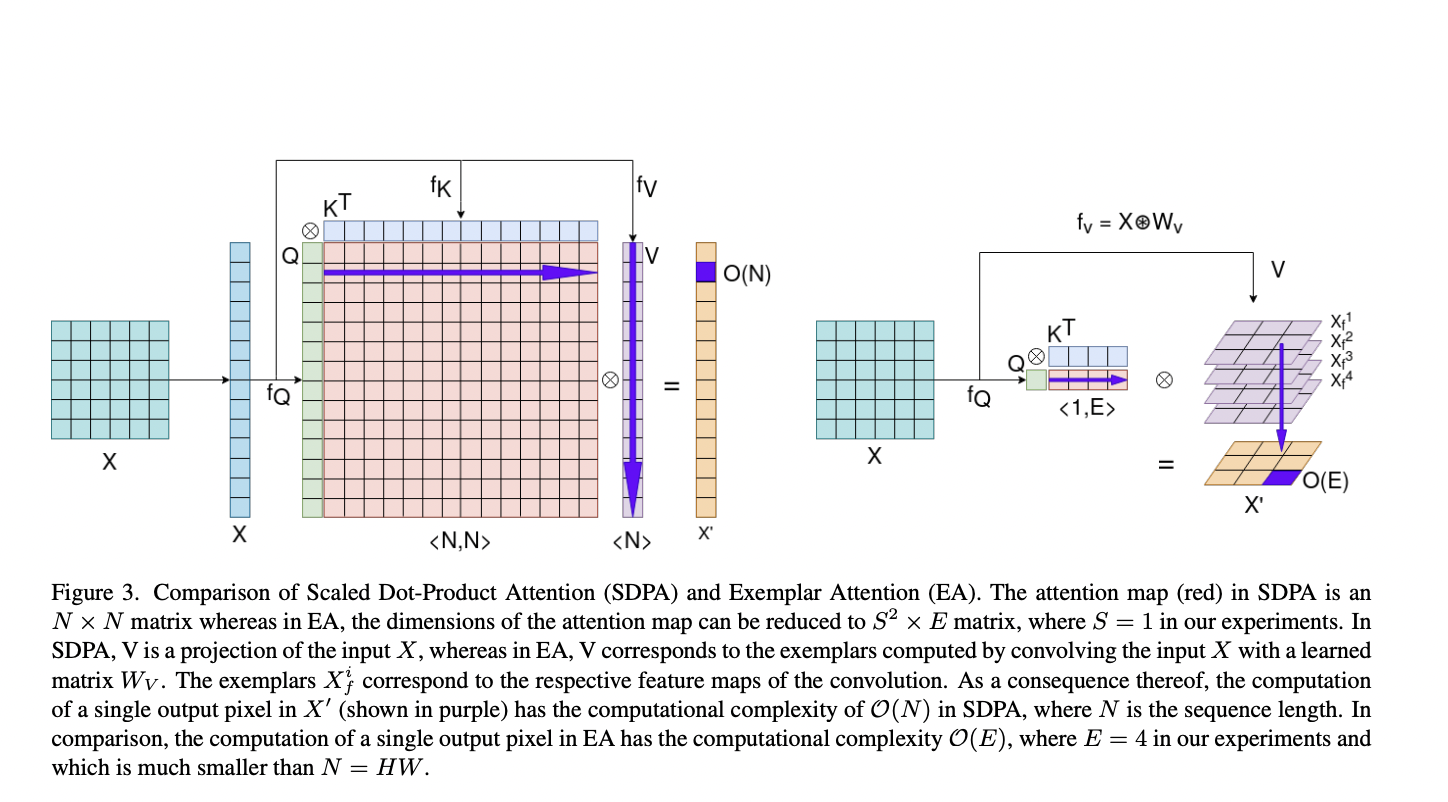
Based on Exemplar Attention, they introduce an efficient transformer layer. The attention module is inspired by the idea of a generalization of the standard “Scaled DotProduct Attention,” a fundamental building element of transformers. While self-attention scales quadratically with image size or input sequence, the researchers re-designed the essential operands to make them more efficient.
Their approach involved the following two hypotheses:
- A limited selection of exemplar values can serve as a shared memory among the dataset’s samples.
- A query representation that is coarser than the input representation is sufficiently descriptive to use the example representation.
Scaled dot-product attention removes spatial biases from the design and gives the similarity function the freedom to learn spatial location dependencies. However, this leads to a computationally costly similarity matrix. In contrast, Exemplar Attention acts on a coarse representation of the input sequence. This sends global information in the form of a Query to the attention layer. The team projects the input onto a set of exemplar representations, resulting in spatial bias. The tiny number of exemplars, together with the large reduction in the Query’s input dimension, results in an efficient transformer layer that can run in real-time on normal CPUs.
The team incorporated their efficient transformer layer in E.T.Track, a Siamese tracking architecture. They used the Exemplar Transformer layer to replace the convolutional layers in the tracker’s head. The Exemplar Transformer layer’s increased expressivity considerably improves the performance of models built on standard convolutional layers without compromising run-time.
The team compared E.T.Tracker against existing state-of-the-art methods on six benchmark datasets: OTB-100, LaSOT, NFS, UAV-123, TrackingNet, and VOT2020. The findings show that the new model outperforms the mobile version of LightTrack by 3.7 percent.
The research reveals that the suggested Exemplar Attention approach can result in significant speedups and cost savings. At the same time, the Exemplar Transformer layers can significantly increase visual tracking models’ resilience. According to researchers, E.T.Track is the first transformer-based tracking architecture capable of functioning in real-time on computationally restricted devices like ordinary CPUs.
Paper: https://arxiv.org/pdf/2112.09686.pdf
Github: https://github.com/visionml/pytracking
Suggested
Credit: Source link
Comments are closed.