Researchers Propose A Novel Parameter Differentiation-Based Method That Can Automatically Determine Which Parameters Should Be Shared And Which Ones Should Be Language-Specific
In recent years, neural machine translation (NMT) has attracted a lot of attention and has had a lot of success. While traditional NMT is capable of translating a single language pair, training a separate model for each language pair is time-consuming, especially given the world’s thousands of languages. As a result, multilingual NMT is designed to handle many language pairs in a single model, lowering the cost of offline training and online deployment significantly. Furthermore, parameter sharing in multilingual neural machine translation promotes positive knowledge transfer between languages and is advantageous for low-resource translation.
Despite the advantages of cooperative training with a completely shared model, the MNMT approach has a model capacity problem. The shared parameters are more likely to preserve broad knowledge while ignoring language-specific knowledge. To improve the model capacity, researchers use heuristic design to create extra language-specific components and build a Multilingual neural machine translation (MNMT) model with a mix of shared and language-specific characteristics, such as the language-specific attention, lightweight language adaptor, or language-specific routing layer.
The National Institute of Pattern Recognition’s research group recently suggested a novel parameter differentiation-based strategy that allows the model to automatically select which parameters should be shared and which should be language-specific during training. Our method is inspired by cellular differentiation, which occurs when a cell transitions from one general cell type to a more specialized type. It allows each parameter shared by multiple tasks to dynamically differentiate into more specialized types.
The model is set up to be totally shared at the start, and it finds shared parameters that should be language-specific on a regular basis. To boost language-specific modeling capability, these parameters are duplicated and redistributed to different tasks. Inter-task gradient similarity is the differentiation criterion, which reflects the consistency of optimization direction across tasks on a given parameter. As a result, only the parameters with conflicting inter-task gradients are chosen for differentiation, while those with more similar inter-task gradients are kept together. In general, without multi-stage training or manually developed language-specific modules, the MNMT model in the technique can steadily improve its parameter sharing configuration.
The study’s primary contributions can be summarised as follows:
• A method is presented for determining which parameters in an MNMT model should be language-specific without the need for manual design, as well as dynamically changing shared parameters into more specialized types.
• The intertask gradient similarity is used as the differentiation criterion, which helps to reduce inter-task interference on common parameters.
• The method’s parameter sharing setup is closely connected with linguistic characteristics such as language families.
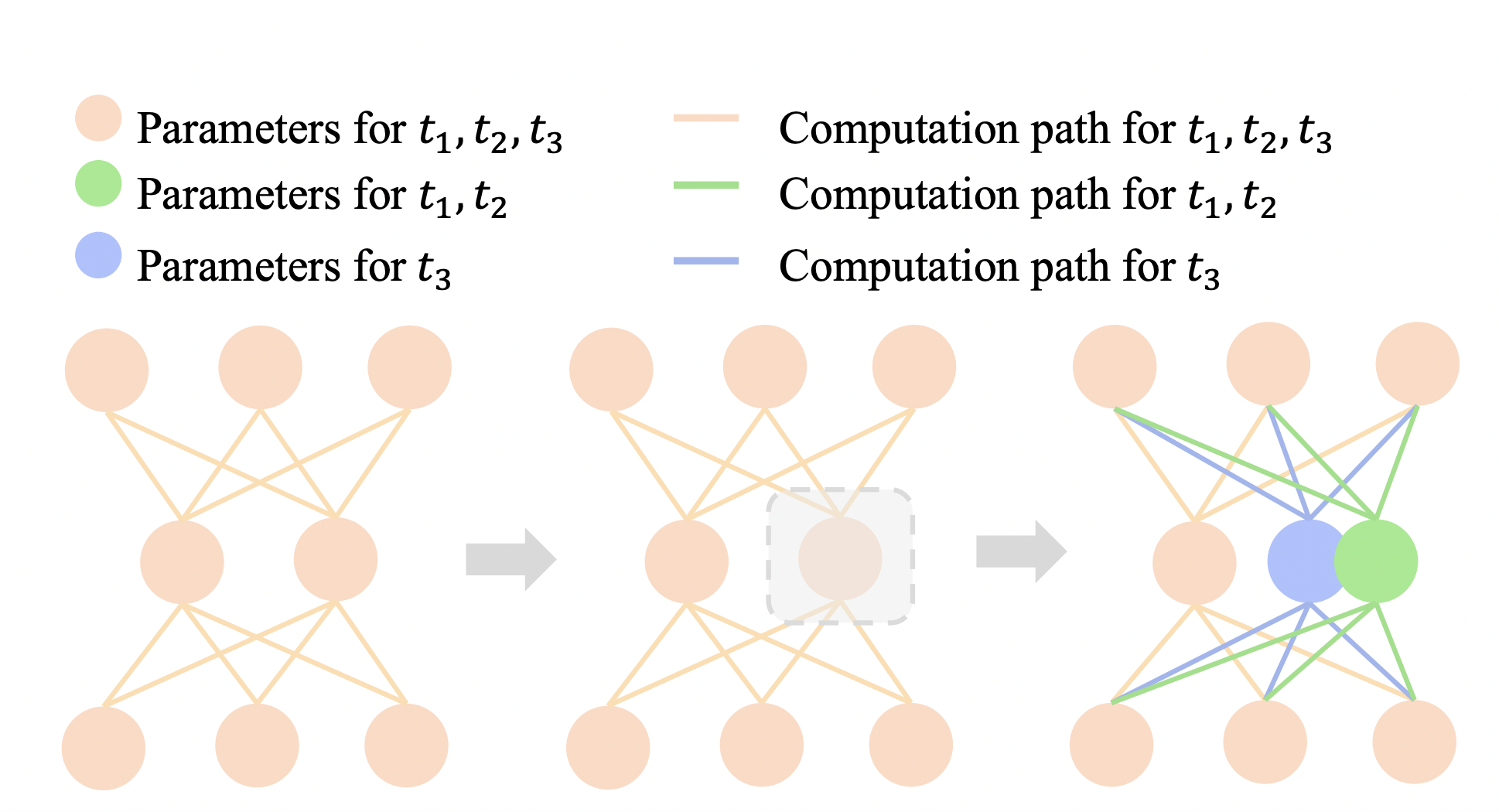
The research’s primary goal is to identify shared parameters in an MNMT model that should be language-specific and dynamically transform them into more specialized types during training. To do this, the team offers a unique parameter differentiation-based MNMT technique, with inter-task gradient similarity as the differentiation criterion. The team proposes parameter differentiation, dynamically converting task-agnostic parameters in an MNMT model into other task-specific ones during training, inspired by biological differentiation.
The paradigm is used to establish the entirely shared MNMT model. The model examines each shared parameter and identifies the parameters that should become more specialized under a given differentiation criterion after several steps of training. The model then replicates those marked parameters and reassigns the replicas to alternative jobs. The model creates new connections for those replicas after duplication and reallocation to create alternative computation graphs. After numerous training steps, the model differentiates and becomes more specialized dynamically.
The definition of a differentiation criterion that aids in the detection of shared parameters that should be differentiated into more specialized types is an essential topic in parameter differentiation. The team bases its differentiation criterion on intertask gradient cosine similarity, with parameters encountering opposing gradients more likely to be language-specific. On held-out validation data, the gradients of each task on each shared parameter are evaluated. The validation data is created as multi-way aligned, i.e., each phrase has translations in all languages, to minimize the gradient variance caused by inconsistent sentence semantics across languages.
On many-to-one and one-to-many translation situations, the public OPUS and WMT multilingual datasets are used, as well as the IWSLT datasets for the many-to-many translation scenario. The original OPUS-100 dataset was used to create the OPUS dataset, which comprises English to 12 languages. The WMT dataset includes data from the WMT’14, WMT’16, and WMT’18 benchmarks with imbalanced data distribution. With data sizes ranging from 0.6M to 39M, five languages were chosen. The many-to-many scenario is evaluated using the IWSLT’17 dataset, which comprises German, English, Italian, Romanian, and Dutch and results in 20 translation directions between the five languages.
The technique regularly outperforms the Bilingual and Multilingual baselines in both one-to-many and many-to-one directions, gaining improvement over the Multilingual baseline of up to +1.40 and +1.55 BLEU on average. The method outperforms existing parameter sharing methods in 20 of the 24 translation directions and improves the average BLEU by a significant margin. The model size is unrelated to the number of languages in the approach, allowing for greater scalability and flexibility. Because several granularities are utilized instead of differentiation on each parameter, the method’s actual sizes range from 1.82 times to 2.14 times, which is close but not quite equal to the predefined 2x.
Conclusion
The authors of this work suggest a unique parameter differentiation-based strategy for determining which parameters should be shared and which should be language-specific. During training, the shared parameters might be dynamically distinguished into more specific categories. Extensive tests on three multilingual machine translation datasets show that our strategy is effective. The method’s parameter sharing configurations are substantially connected with linguistic proximities, according to the assessments. The team hopes to let the model understand when to cease differentiating in the future, as well as investigate various differentiation criteria for multilingual scenarios such as zero-shot translation and progressive multilingual translation.
Paper: https://arxiv.org/pdf/2112.13619v1.pdf
Github: https://github.com/voidmagic/parameter-differentiation
Suggested
Credit: Source link
Comments are closed.