Researchers From Stanford and NVIDIA Introduce A Tri-Plane-Based 3D GAN Framework To Enable High-Resolution Geometry-Aware Image Synthesis

Generative Adversarial Networks (GANs) have been one of the main hypes of recent years. Based on the famous generator-discriminator mechanism, their very simple functioning has driven the research to continuously improve the former architecture. The peak in image generation has been reached by StyleGANs, which can produce astonishingly realistic and high-quality images, able to fool even humans.
While the generation of new samples has achieved excellent results in the 2D domain, 3D GANs are still highly inefficient. If the exact mechanism of 2D GANs is applied in the 3D environment, the computational effort is too high since 3D data is tough to manipulate for current GPUs. For this reason, the research has focused on how to construct geometry-aware GANs that can infer the underline 3D property using solely 2D images. But, in this case, the approximations are usually not 3D consistent.
Together with Stanford University, the NVIDIA team has proposed their Efficient Geometry-aware 3D GANs to solve this problem. This architecture is capable of synthesizing not only high-resolution multi-view-consistent 2D images but also produces high-quality 3D geometry. This has been achieved with two main introductions: the first is a hybrid explicit-implicit 3D representation, called tri-plane, which is both efficient and expressive; the second is an ensemble of a dual-discrimination strategy and pose-based conditioning of the generator, promoting multi-view consistency.
Tri-plane 3D representation
In a 3D scene, if you select a specific point, it can be defined by its position (x,y,z coordinates) and direction (the point of view). 3D representation takes as input these two values and returns the RGB color and its density (if you image a ray that passes through a 3D scene, the density at a certain point is the probability that the ray has stopped there; for example, if the point is inside a solid, the density will be high).
3D representation can be explicit or implicit, for example, Voxel and NeRF representations, respectively. Explicit representations, such as discrete voxel grid, are fast in prediction but are very memory heavy, as you have to keep the explicit representation in memory (i.e., the cube in the figure (b) below). Otherwise, implicit representations represent a scene as a continuous function; thus, they are very memory efficient but have a costly prediction, as you can see from the (relatively) big decoder in figure (a) below.
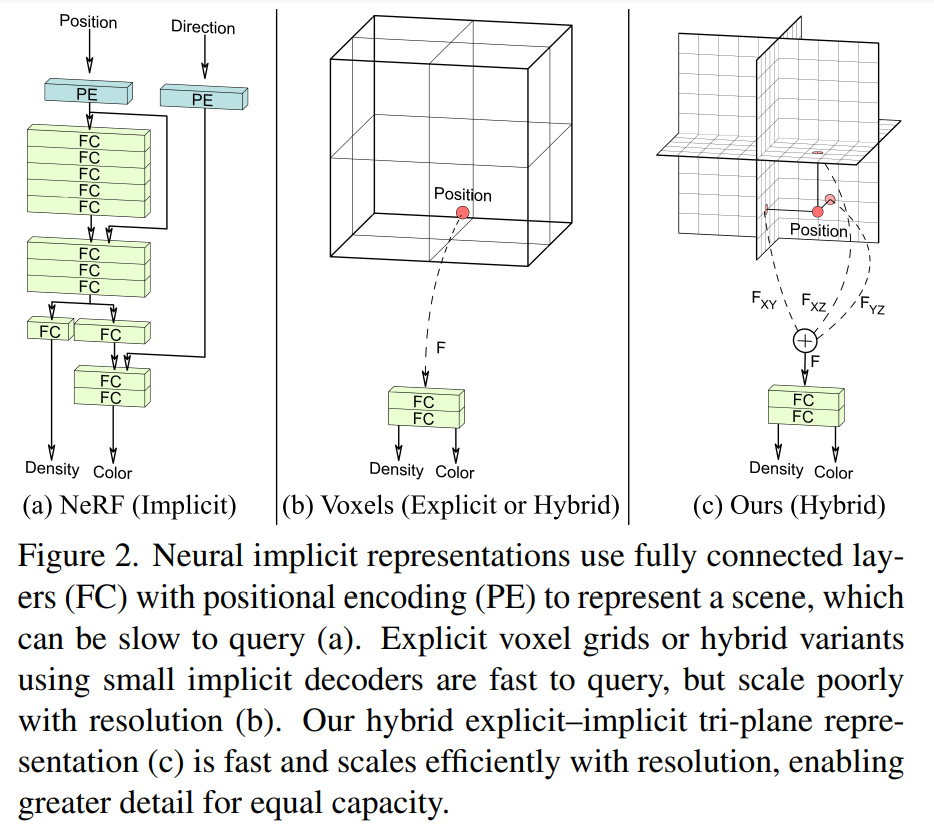
Tri-plane representation takes the pros of the two approaches to defining an implicit-explicit representation. It stores in memory three planes with a resolution of N x N x C (C is not 1, as it can be erroneously inferred from the image above) and not the complete voxel grid. A 3D position is projected into the planes, and the corresponding feature vectors are summed and passed to a small decoder. Triplane representation is both fast in prediction and memory efficient, and its expressiveness has also been demonstrated in comparison with the other two approaches in the figure below.

3D GAN framework
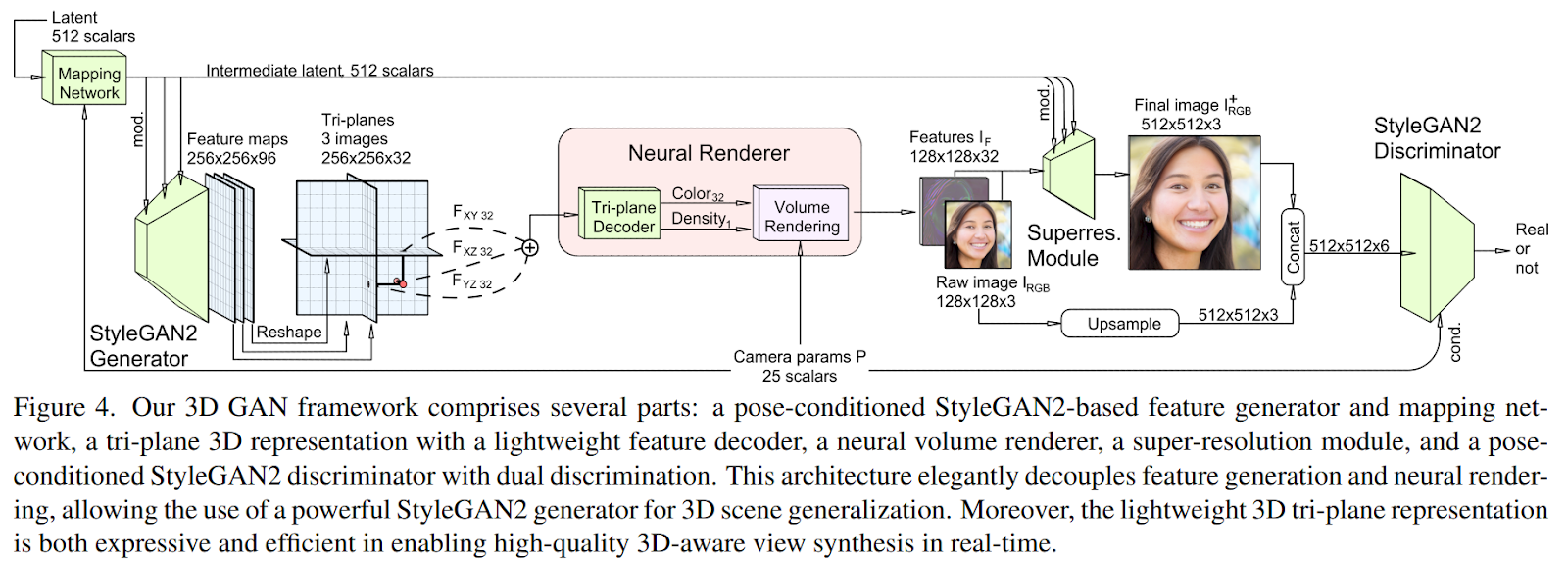
Before presenting the entire framework, it should be noted that although the authors often point out in the paper that the algorithm only works with 2D images, each image is associated with a set of camera intrinsic and extrinsic, which were determined using a pose detector (P in the image above).
Firstly, the random latent code and the just-mentioned camera parameters are processed by a mapping network that returns an intermediate latent code, used to modulate both the StyleGAN2 generator and the subsequent Super Resolution module. The following generator produces a 256 x 256 x 96 image, split channel-wise to form the tri-plane features. The three-axis features are aggregated in the neural renderer, and the lightweight decoder produces a 128 x 128 x 32 image If from a given camera pose.
The whole process is still too slow to render at high resolutions; for this reason, the authors rendered at a relatively low resolution and performed upsampling with a super-res module.
Finally, a discriminator is used to evaluate the renderings but with two modifications compared to the original StyleGAN2 one. First, dual discrimination was used, consisting of the following procedure: If is passed to the super-res module, which outputs a 512 x 512 x 3 image Irgb+. In parallel, the first three channels of If are interpreted as a low-resolution RGB image Irgb, which is bilinearly unsampled to 512 x 512 x 3 and concatenated with Irgb+ to form a six-channel image. This process encourages super-resolved images to be consistent with neural renderings.
Second, the authors conditioned the discriminator with the camera poses from which the generated images are rendered, to help the generator learn correct 3D priors.
Results
The results of this approach are impressive for both 2D and 3D generation. A visual comparison with other existing techniques is shown below.

Interestingly, the authors tested also single-view 3D reconstruction, using pivotal tuning inversion to fit test images and obtain a 3D reconstruction from an RGB image (image below).

As the author pointed out, this approach still lacks fine details (such as individual teeth) but presents a very significant improvement in the field of 3D-aware GANs, and we can’t wait to see what comes next!
Paper: https://arxiv.org/pdf/2112.07945.pdf
Project: https://matthew-a-chan.github.io/EG3D/
Suggested
Credit: Source link
Comments are closed.