Efficient Large-scale Object Counting in Satellite Images with Importance Sampling
Object counts provide insights into socioeconomic and environmental issues: for example, building counts reflect the level of urbanization. How can we estimate the total number of buildings globally? High-resolution satellite images allow us to see buildings, but acquiring all images globally and counting buildings manually within the images would cost 2,532 million USD and 29 million hours 🤯. How many of us can afford this 🧐? In the paper, we propose a machine learning-based sampling approach that drastically reduces the cost for estimating object counts. Our approach saves up to 164 million dollars for counting buildings in the U.S. while being accurate 🤩. It can be easily generalized to counting different objects globally and can be potentially applied to other sustainability and biology applications. Check out our AAAI 2022 paper and code.
The quantities of physical capital, or object counts, provide important insights into human activities and the socio-economic development of a region. For example, the number of buildings reflects the level of urbanization in a region; the number of brick kilns is related to the level of air pollution, and the number of cars correlates with the poverty level of a region.
Traditionally, statistics of physical capital (e.g. buildings, cars, and roads) have been derived from ground-based surveys, which are expensive and time-consuming to conduct. For example, the Demographic and Health Surveys (DHS) collects population-related statistics of about 90 countries at a cost of 1.9 million dollars over a five-year interval [1].
Recently, object detection in high-resolution satellite imagery has emerged as an alternative to ground-based survey data collection in socioeconomic monitoring tasks like counting brick kilns in Bangladesh [2] and counting solar panels in the U.S. [3].

A common detection-based pipeline [2, 4] to collect object count statistics over a large region exhaustively downloads all satellite images covering the target region, counts the objects in each image using a trained detection model, and takes the summation of counts in all the images to produce a total count.
Nevertheless, such an exhaustive approach scales and generalizes poorly due to the following problems:
- Applying detection-based methods to real-world scenarios is often prohibitively expensive because of the high cost of purchasing high-resolution satellite images and a large amount of computation required to apply detection models at scale.
- Training the detection model requires a large number of labeled images in the first place, which could be even more expensive to obtain.
- Pre-trained detection models generalize poorly under domain shift, which prevents us from directly applying a model to different target regions and objects.
Using Sampling for Estimating Object Count
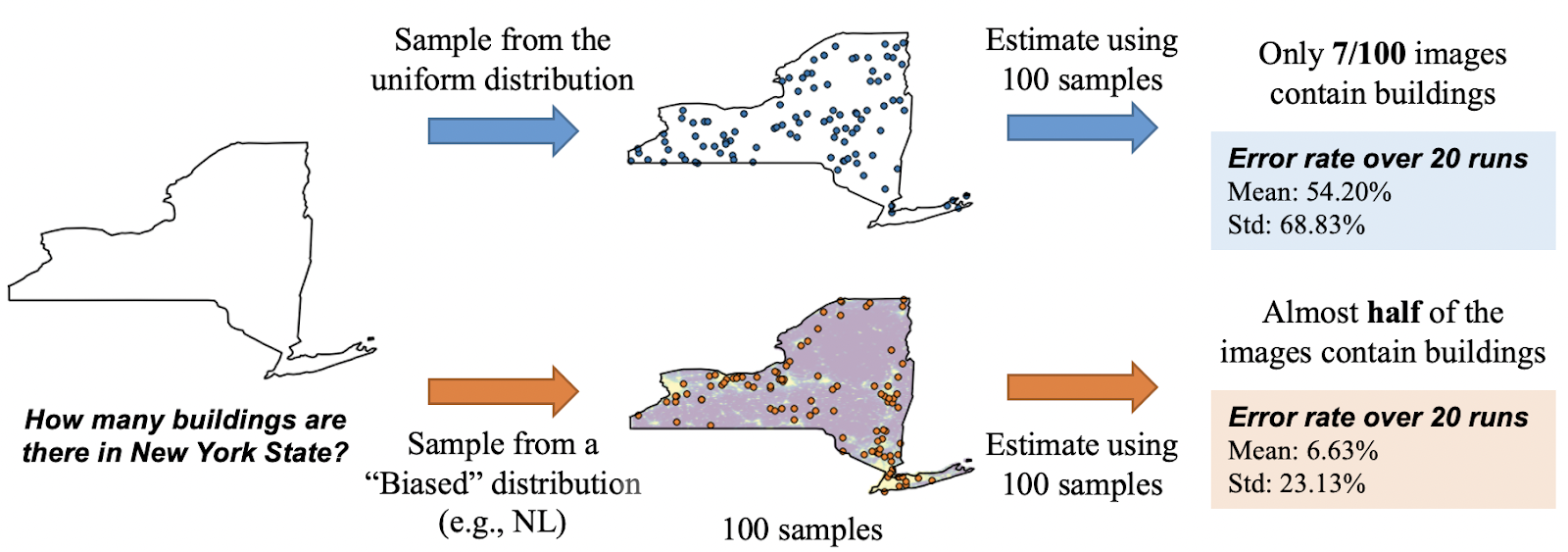
To avoid the high cost required by the exhaustive approaches, we utilize sampling for estimating the total object count over a large geography. However, applying sampling to real-world object counting is challenging, as the objects of interest often have uneven spatial distributions. For example, buildings are concentrated in towns and cities that take up a tiny proportion of the Earth’s surface but have close-to-zero density in regions like deserts and forests.
In this case, if we directly apply uniform sampling, it is likely that most of the samples have zero object counts. As a result, uniform sampling results in high variance and requires a large number of samples in order to perform well (Figure 2).
To address this problem, we adopt importance sampling (IS), which allows us to sample “important” regions – i.e. those that have non-zero object counts – more frequently from a “biased”, or non-uniform, proposal distribution and hence reduces the variance of uniform sampling (Figure 2). Finally, the total count is estimated by reweighting each sample, which ensures that we produce an unbiased estimator.
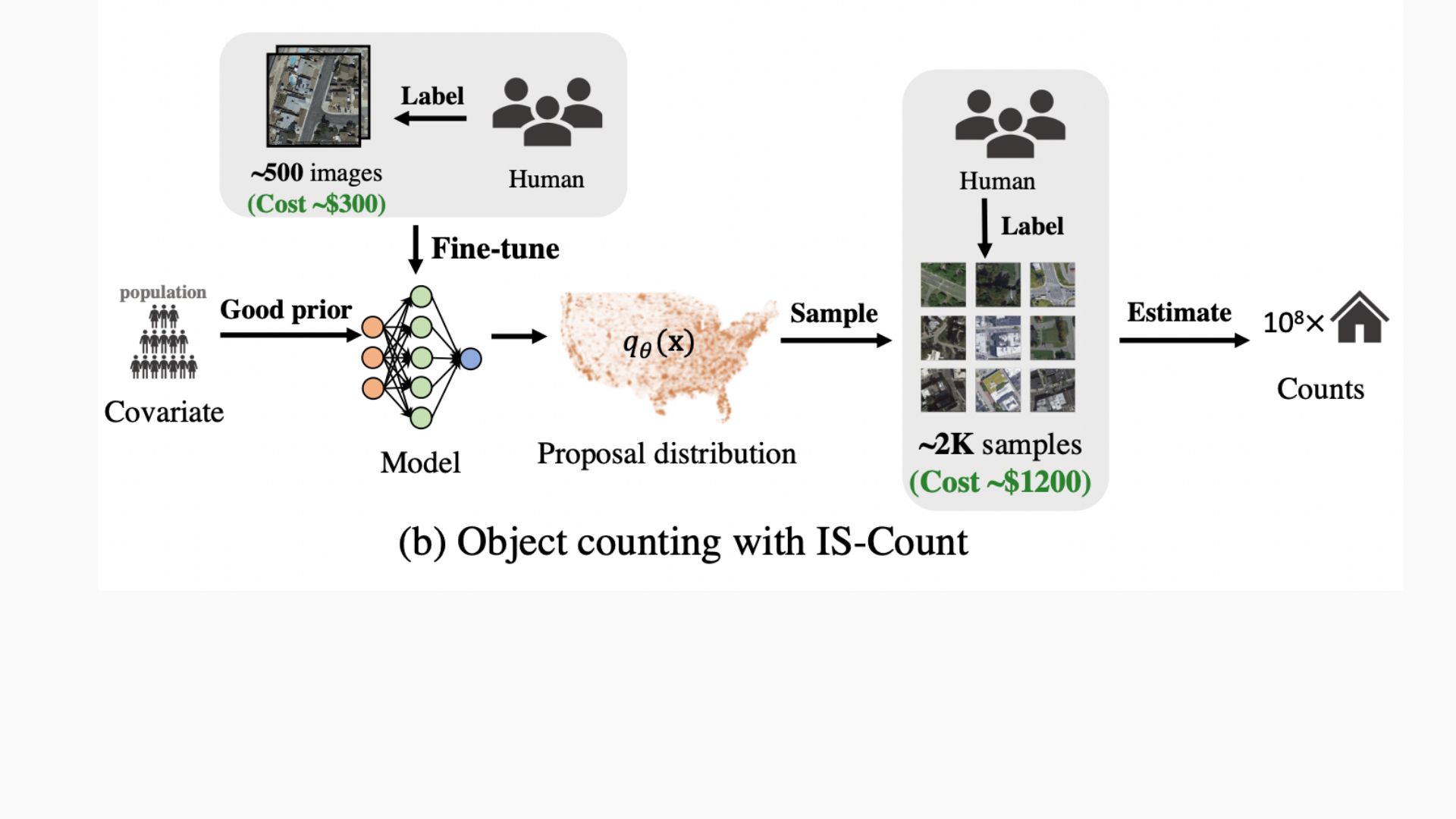
IS-Count: Combining Importance Sampling and Machine Learning
Our method, IS-Count, selects a small number of representative areas by 1) sampling from a learnable proposal distribution and 2) estimating the total object count by reweighting according to importance sampling.
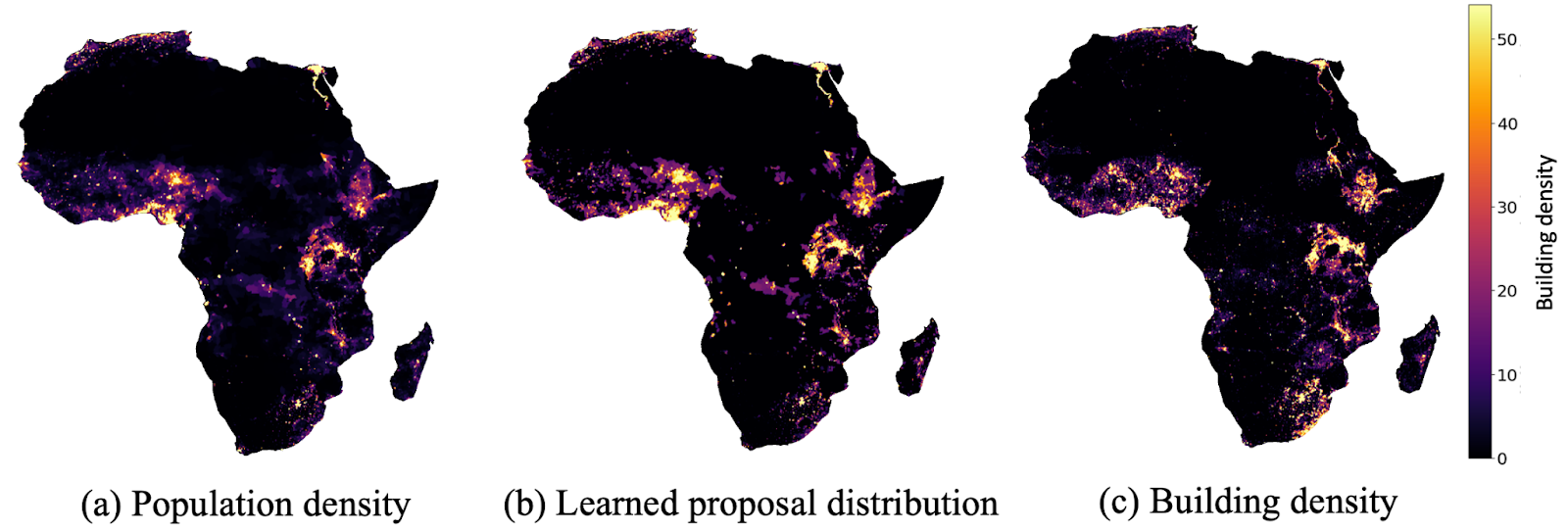
The first step is to construct the proposal distribution from which we will sample representative locations. Optimally, the proposal distribution should be as close to the target object density as possible because this will yield the lowest variance of estimation.
Observing that publicly available socioeconomic indicators like nightlight intensity (NL) and population density are highly correlated with the target object counts, we treat the covariates (i.e. NL, population) as the base for designing the proposal distribution. The intuition is that these covariates provide a good prior knowledge for building a proposal distribution that is close to the target object counts. The proposal distribution is then learned based on the covariates.
After constructing the proposal distribution, we sample a small number of informative areas from it. The high-resolution satellite imagery correlated with these representative samples are downloaded and labeled by human annotators for estimating the total count.
Estimating Building Counts and Beyond
We applied IS-Count to estimate the building count in 43 African countries and 51 U.S. states. Using as few as 0.1% of satellite imagery samples in the chosen regions, we achieved an estimation error rate as low as 1.0%. Click on the video below to see the estimation error our model yields on a particular region (with NL as the covariate).
Besides counting buildings, IS-Count also shows strong performance on estimating the number of cars in Kenya, brick kilns in Bangladesh, and swimming pools in the U.S., while using as few as 0.01% of satellite image samples compared to an exhaustive approach.
Future Applications
Besides the objects we experimented within the paper, IS-Count could be easily adapted to counting other entities. For example, with properly chosen covariates, IS-Count could be adapted to different forms of images (i.e. street imagery) for counting different entities (e.g. people) at a large scale. Extending it even further, IS-Count is applicable to various counting tasks in sustainability and biology – e.g. counting cells. No matter whether you are a machine learning expert or completely new to machine learning, IS-Count comes as an accessible and convenient method for your own counting problems.
Paper: https://arxiv.org/abs/2112.09126
Github: https://github.com/sustainlab-group/IS-Count
Research team members involved with this blog article: Enci Liu, Chenlin Meng, Willie Neiswanger, Jiaming Song
Reference
[1] Demographic and Health Survey – DHS 2020 https://www.usaid.gov/angola/fact-sheet/linkages
[2] Lee, J.; Brooks, N. R.; Tajwar, F.; Burke, M.; Ermon, S.; Lobell, D. B.; Biswas, D.; and Luby, S. P. 2021. Scalable deep learning to identify brick kilns and aid regulatory capacity. Proceedings of the National Academy of Sciences, 118(17).
[3] Yu, J.; Wang, Z.; Majumdar, A.; and Rajagopal, R. 2018. DeepSolar: A machine learning framework to efficiently construct a solar deployment database in the United States. Joule, 2(12): 2605–2617.
[4] Yi, Z. N.; Frederick, H.; Mendoza, R. L.; Avery, R.; and Goodman, L. 2021. AI Mapping Risks to Wildlife in Tanzania — Development Seed.
Suggested
Credit: Source link
Comments are closed.