Intel AI Team Proposes A Novel Machine Learning (ML) Technique, ‘Multiagent Evolutionary Reinforcement Learning (MERL)’ For Teaching Robots Teamwork

Reinforcement learning is an interesting area of machine learning (ML) that has advanced rapidly in recent years. AlphaGo is one such RL-based computer program that has defeated a professional human Go player, a breakthrough that experts feel was a decade ahead of its time.
Reinforcement learning differs from supervised learning because it does not need the labelled input/output pairings for training or the explicit correction of sub-optimal actions. Instead, it investigates how intelligent agents should behave in a particular situation to maximize the concept of cumulative reward.
This is a huge plus when working with real-world applications that don’t come with a tonne of highly curated observations. Furthermore, when confronted with a new circumstance, RL agents can acquire methods that allow them to behave even in an unclear and changing environment, relying on their best estimates at the proper action.
Despite this advantage, many believe that it is inefficient because it is based on a trial-and-error process. However, researchers at Intel’s AI Lab has developed effective approaches for using RL for practical breakthroughs. They’re working on RL agents that can swiftly figure out challenging jobs and work in groups, placing the group’s general aim ahead of their own personal objectives.
In RL, the tension between exploiting a current policy and exploring alternatives is crucial. RL agents have no way of knowing whether it is optimal at any particular time. As a result, it must choose between continuing to choose actions based on its present policy and deviating from it to explore new alternatives. It will never improve if it selects the former. The exploration rate is frequently set high at the start of training and gradually reduced as the agent gets expertise.
Agents in Low-Reward Situations
When an agent is functioning in a low-reward situation, the challenges become considerably larger. In this circumstance, the environment only offers a feedback signal, perhaps only at the end of a protracted multi-step process. As a result, the majority of the agent’s actions result in no useful feedback.
Many researchers have used the Mujoco Humanoid benchmark created by OpenAI to assess RL bots’ performance in such difficult conditions. Researchers must teach a computer model of a 3D humanoid figure to walk for a set amount of time without falling in this experiment. While walking appears to be a simple activity, it is pretty difficult for an RL system to master.
Intel’s AI team proposed a novel solution called CERL: Collaborative Evolutionary Reinforcement Learning to solve this problem. They break down this task into two components: small problems for which the system can receive rapid feedback and larger optimization problems that must be handled over a longer period.
For the Mujoco Humanoid challenge, they had many learners working on smaller problems, including not falling over, raising a foot, among others. As they attempted to meet these tiny targets, the learners received rapid feedback. Each learner thus became an expert in their particular skill area, talents that may help them achieve the bigger goal of prolonged walking, even if they had no chance of achieving it on their own.
What is unique about their design is that it allows all learners to contribute to and draw from a single buffer at the same time. Each learner had access to everyone else’s experiences, which aided its own exploration and made it significantly more efficient at its own task.
The second group of agents, dubbed actors, was tasked with combining all of the little movements in order to achieve the broader goal of prolonged walking. Since these agents were rarely close enough to register a reward, the team used a genetic algorithm, a technique that simulates biological evolution through natural selection. Genetic algorithms start with possible solutions to a problem and utilize a fitness function to develop the best answer over time.
They created a set of actors for each “generation,” each with a unique method for completing the walking job. They then graded them according to their performance, keeping the best and discarding the others. The following generation of actors was the survivors’ “offspring,” inheriting their policies.
Their hybrid system quickly found an optimal policy that allowed the Mujoco Humanoid to go for a walk, outperforming other algorithms at the time.
The Multi-Agent Problem
While RL is difficult enough due to the scarcity of rewards, it becomes significantly more complicated when a job requires numerous agents to work together to attain a common goal. They chose the benchmark for simulated Mars rovers, in which two rovers must work together to identify many objects in the lowest amount of time.
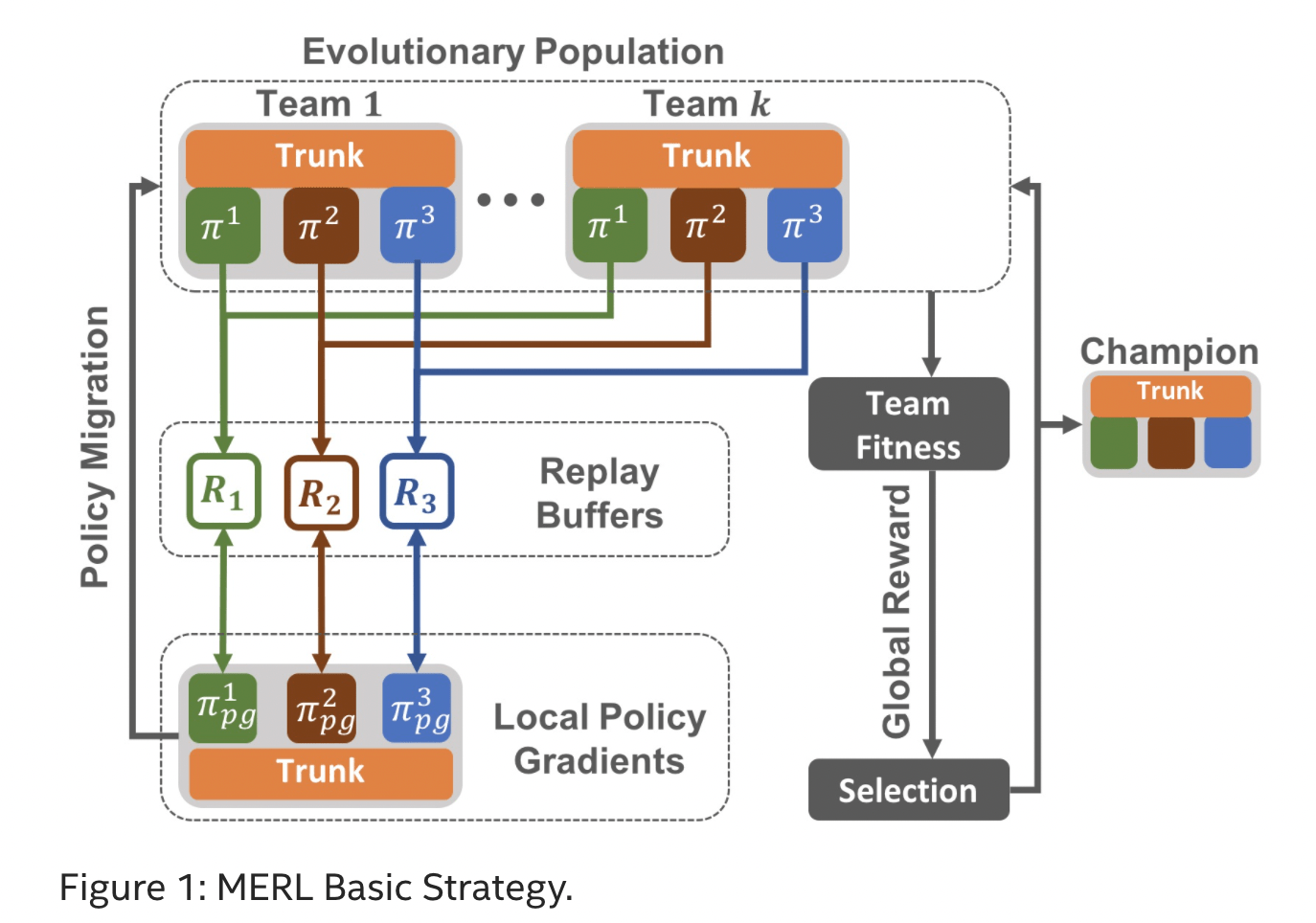
To tackle this difficult multi-agent task, the researchers extended their CERL framework and introduced Multiagent Evolutionary Reinforcement Learning (MERL).
They used evolutionary search again this time. They made multiple duplicates of a whole rover team this time while working with teams. All of the Rover 1s and all of the Rover 2s and so on shared a single replay buffer. The replay buffers were purposefully split by rovers to allow each to focus on its own local learning.

The rovers were required to work together because each target was only counted once enough rovers had reached it. Locally optimized policies were inserted into the evolutionary search, just as they were in CERL, so that the best policies from the Rover 1s, Rover 2s, and so on could be tried out. Evolution simply had to cope with the overall strategy of the team.
The team compared MERL’s performance to that of the MADDPG algorithm, another state-of-the-art system for multi-agent RL. They notice that their virtual robots were first tested on a smaller rover issue, in which only one rover must reach a target. It is found that MERL hit more targets than MADDPG, as well as some unusual team behaviour.
MADDPG entirely failed when three rovers had to reach a goal at the same time, and MERL’s emergent team formation was even more visible, a tendency they noticed as the needed number of rovers increased. Intel’s research explored various multi-agent benchmarks, and the two-part optimization of MERL significantly beat existing state-of-the-art techniques in each case.
The team is also looking into how communication might assist multi-agent systems in performing better. They’re specifically looking into whether agents on a team communicating with one another can form a kind of language.
They’re also exploring ways to provide a common safety standard for diverse RL algorithms, as well as a framework for training RL agents to operate securely in any application. Because an abstracted concept of safety is difficult to establish, and a task-specific definition of safety is difficult to scale across activities, this is easier said than done.
Today’s AI is good at things like object and speech recognition, but it’s not good at performing actions. Robots, self-driving automobiles, and other autonomous systems will benefit from RL training since it will teach them how to operate in a changing and unpredictable environment.
They’re employing RL paired with search algorithms to teach robots how to construct successful trajectories with minimum interaction with the real world in one ongoing test of our theories. This method could allow robots to experiment with new actions without risking harming themselves.
Finally, they are using the same methodology to improve many areas of software and hardware systems. Their recent study shows that an RL agent can learn how to manage memory on a hardware accelerator efficiently. By efficiently allocating chunks of data to various memory components, their technique, Evolutionary Graph RL, was able to virtually quadruple the speed of execution on hardware as compared to the native compiler. This achievement and other recent study findings demonstrate that RL is progressing from solving games to solving real-world problems.
MERL Research: https://www.intel.com/content/www/us/en/artificial-intelligence/posts/introducing-merl.html
CERL Research: https://arxiv.org/abs/1905.00976
Source: https://spectrum.ieee.org/reinforcement-learning/particle-17
Suggested
Credit: Source link
Comments are closed.