A Detailed Understanding of Convolutional Neural Networks
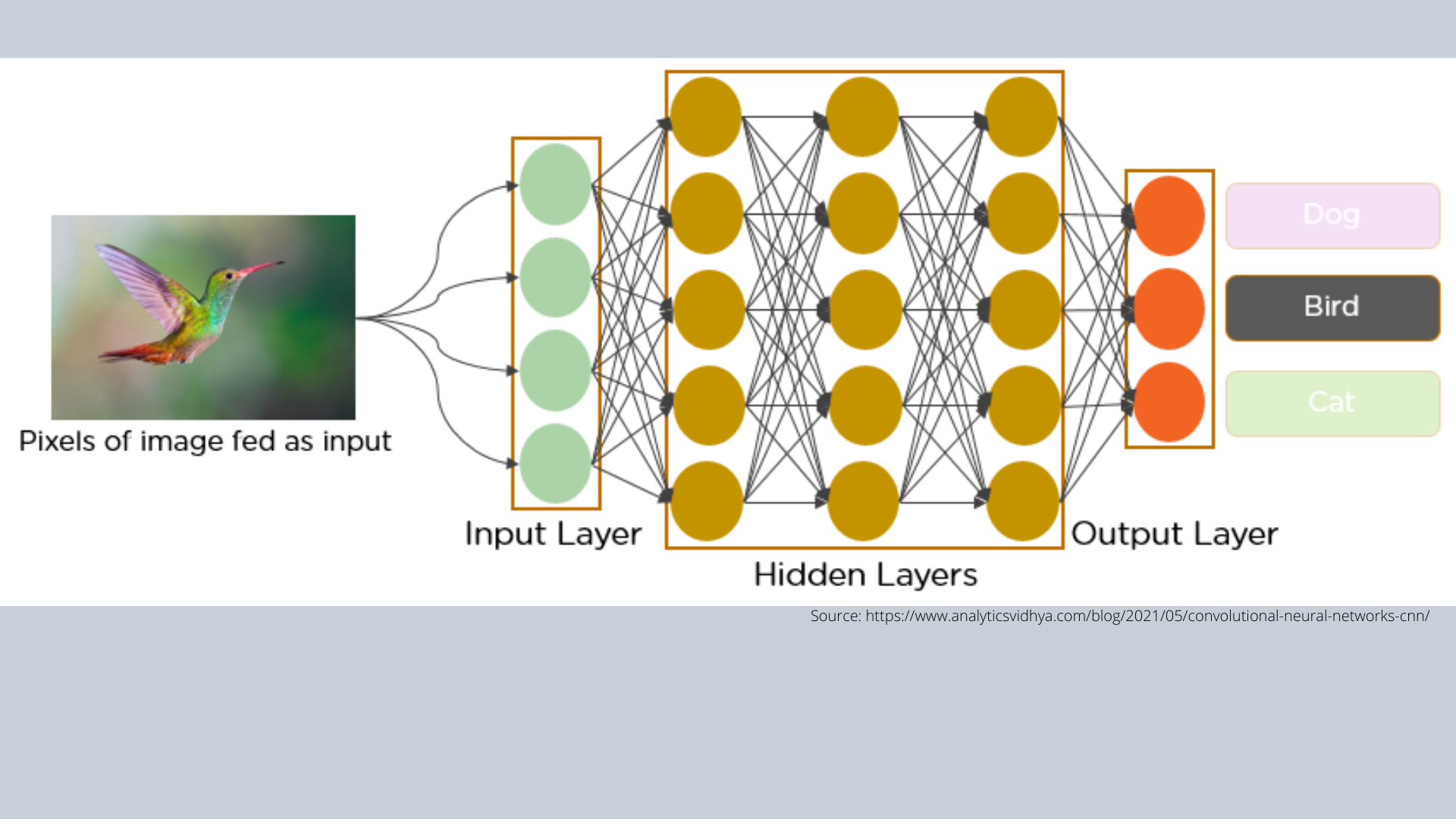
Deep learning techniques are based on neural networks, which are a subset of machine learning. They’re made up of node levels, each of which has an input layer, one or more hidden layers, and an output layer. Each node is connected to the others and has a weight and threshold assigned to it. If a node’s output exceeds a particular threshold value, the node is activated, and data is sent to the next tier of the network. Otherwise, no data is sent on to the network’s next tier.
A Convolutional Neural Network (ConvNet/CNN) is a Deep Learning system that can take an image as input, assign learnable weights and biases to various objects in the image, and differentiate between them. Compared to other methods, the amount of pre-processing required by a ConvNet is significantly less. While basic approaches require hand-engineering of filters, ConvNets can learn these filters/characteristics with enough training.

Convolutional neural networks use principles from linear algebra, notably matrix multiplication, to discover patterns inside an image, making them more scalable for image classification and object recognition tasks. The architecture of a ConvNet is inspired by the organization of the Visual Cortex and is akin to the connectivity pattern of Neurons in the Human Brain.
The higher performance of convolutional neural networks with picture, speech, or audio signal inputs makes them stand out from conventional neural networks. They are divided into three sorts of layers:
- Convolutional layer
- Pooling layer
- Fully-connected (FC) layer
A convolutional network’s first layer is the convolutional layer. While further layers can be added after convolutional layers, the fully-connected layer is the final layer. The CNN becomes more complex with each layer, detecting larger areas of the image. Initial layers concentrate on essential elements like borders and colors. As the visual data traverses through the CNN layers, it begins to differentiate larger elements of the item, eventually identifying the target object.
The convolutional layer is an essential component of a CNN as it is where most of the computation takes place. It requires a filter, input data, and a feature map, among other things. Let’s pretend the input is a color image, which is made up of a 3D matrix of pixels. This indicates that the input will have three dimensions, which correspond to RGB in an image: height, width, and depth. A feature detector, also known as a filter, traverses across the image’s receptive fields, checking for the presence of the feature. Convolution is the term for this procedure.
The feature detector is a two-dimensional (2-D) weighted array that represents a portion of the image. The filter size is usually a 3×3 matrix, which affects the size of the receptive field. Consequently, the filter is applied to a portion of the image, and a dot product between the input pixels and the filter is computed. The dot product is passed into an output array after that. The filter then shifts by a stride, and the procedure is repeated until the kernel has swept across the entire image. A feature map or an activation map is the ultimate output of a series of dot products from the input and the filter.
The feature detector’s weights stay fixed as it advances over the image, a technique known as parameter sharing. Backpropagation and gradient descent are used to change some parameters, such as weight values, during training. However, there are a few hyperparameters that determine the output volume size that must be specified before the neural network can be trained.
The hyperparameters are as follows:
- The number of filters: It has an impact on the output’s depth. Three distinct filters, for example, would result in three different feature maps, resulting in a depth of three.
- Stride: It refers to the distance, or the number of pixels, that the kernel travels across the input matrix. Although stride values of two or more are seldom used, a bigger stride results in a lesser output.
- Zero-padding: When the filters don’t fit the input image, it’s frequently utilized. All parameters outside of the input matrix are set to zero, resulting in a larger or equal-sized output.
Downsampling, also known as pooling layers, is a dimensionality reduction technique that reduces the number of factors in the input. The pooling process sweeps a filter across the entire input, similar to the convolutional layer; however, this filter does not have any weights. Instead, the kernel uses an aggregation function to populate the output array from the values in the receptive field.
Pooling can be divided into two categories:
- Max pooling: The filter selects the pixel with the largest value to pass to the output array as it advances across. In comparison to average pooling, this technique is employed more frequently.
- Average pooling: The average value inside the receptive field is calculated as the filter passes over the input and is sent to the output array.
While the pooling layer loses a lot of information, it does provide CNN with a number of advantages. They aid in the reduction of complexity, increased efficiency, and the prevention of overfitting.

Using a Fully-Connected layer to learn non-linear combinations of high-level features as represented by the convolutional layer’s output is a cheap technique to learn non-linear combinations of high-level features. In such an area, the Fully-Connected layer is learning a possibly non-linear function.
In partially linked layers, the pixel values of the input image are not directly connected to the output layer. Each node in the output layer, on the other hand, connects directly to a node in the previous layer in the fully-connected layer.
The fully connected layer performs categorization using the features gathered by the preceding layers and their various filters. While convolutional and pooling layers typically utilize ReLu functions to categorize inputs, FC layers typically use a softmax activation function to provide a probability from 0 to 1.
CNN architectures come in a variety of shapes and sizes, and they’ve all played a role in the development of AI systems.
Some of the most well-known structures are:
Conclusion
Image identification and computer vision problems are aided by convolutional neural networks. Computer vision is a paradigm that allows computers and systems to extract useful information from digital photos, videos, and other visual inputs and then take action based on that knowledge. It differs from picture recognition jobs in that it can make recommendations. Today, some typical applications of computer vision may be found in:
- Marketing: Social networking sites make it easier to tag friends in photo albums by suggesting who might be in a photo that has been put on a profile.
- Healthcare: Radiology technology has included computer vision, allowing clinicians to better recognize malignant tumors in healthy anatomy.
Automotive: While the era of self-driving cars has yet to arrive, the underlying technology has begun to make its way into autos, enhancing driver and passenger safety with features such as lane line detection.
References:
- https://www.ibm.com/cloud/learn/convolutional-neural-networks
- https://towardsdatascience.com/a-comprehensive-guide-to-convolutional-neural-networks-the-eli5-way-3bd2b1164a53
- https://machinelearningmastery.com/convolutional-layers-for-deep-learning-neural-networks/
- https://insightsimaging.springeropen.com/articles/10.1007/s13244-018-0639-9
- https://www.analyticsvidhya.com/blog/2021/05/convolutional-neural-networks-cnn/
Suggested

Credit: Source link
Comments are closed.