Introduction To Federated Learning: Enabling The Scaling Of Machine Learning Across Decentralized Data Whilst Preserving Data Privacy

Large volumes of data are required for training machine learning models. The trained model is run on a cloud server that users can access through various applications such as web search, translation, text production, and picture processing, which is the standard procedure for establishing machine learning applications.
The application must transfer the user’s data to the server where the machine learning model is stored every time it wishes to use it, creating privacy, security, and processing issues.
Fortunately, developments in edge AI have allowed sensitive user data to be avoided from being sent to application servers. This current area of study, also known as TinyML, aims to construct machine learning models that fit smartphones and other consumer devices, making on-device inference possible. Even if the device is not connected to the internet, these applications can continue functioning. The on-device inference is more energy-efficient in many applications than transferring data to the cloud.
However, the data is still required to train the models installed on customers’ devices. When the entity generating the models already owns the data (e.g., a bank owns its transactions) or the data is public information, this isn’t a problem (e.g., Wikipedia or news articles). But, acquiring training data for machine learning models that leverage confidential user information such as emails, chat logs, or personal images poses numerous obstacles.
Federated Learning
Federated Learning (FL) allows mobile phones to develop a shared prediction model cooperatively while retaining all of the training data on the device, effectively divorcing machine learning from the requirement to store data in the cloud. Bringing model training to the device extends beyond using local models that make predictions on mobile devices.
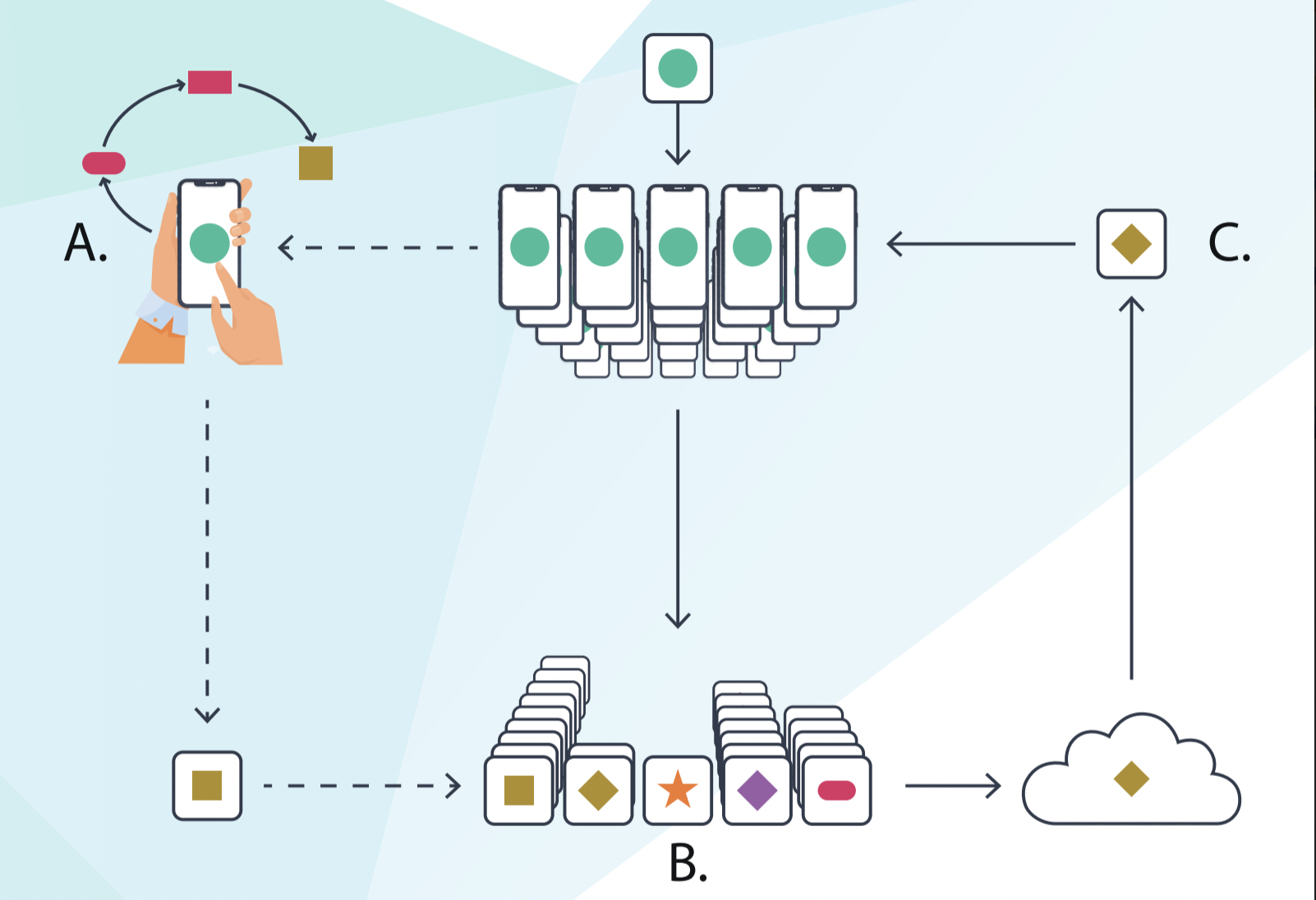
The foundation for federated learning is a machine learning model in the cloud server. This model has either been trained on a publicly available dataset or has not been trained at all.
Several user devices offer to train the model to the next level. User data relevant to the model’s application is stored on these devices, such as chat logs and keystrokes. These devices download the base model while connected to a power outlet and on a wi-fi network (training is a compute-intensive operation that will drain the device’s battery if done at an inopportune time). They then use the device’s local data to train the model.
After training, the trained model is sent back to the server. The training data is no longer required for inference once the models have been trained to encapsulate the statistical patterns of the data in numerical parameters. As a result, no raw user data is included when the device sends the trained model back to the server. The server updates the basic model with the aggregate parameter values of user-trained models after receiving data from user devices.
The federated learning cycle is repeated numerous times before the model achieves the developers’ desired degree of accuracy. When the final model is complete, it can be shared for providing the on-device interface.
Federated Learning enables smarter models, lower latency, and lower energy use while maintaining privacy. In addition to giving an update to the shared model, the enhanced model on the phone can be used right away, powering experiences tailored to the way users use their phones.
This way, federated learning could revolutionize the way AI models are trained in almost all sectors such as healthcare, automobiles, IoT, and FinTech, to name a few.
Differential Privacy
Many privacy preservation strategies allow large data analysis in the form of statistical estimation, statistical learning, data mining, and other methods while maintaining the privacy of individual participants. Differential Privacy is one such contemporary cybersecurity solution that protects personal data significantly.
Differential privacy is a method that allows researchers and database analysts to extract meaningful information from databases containing people’s personal information without revealing personal identification information about them.
This method makes data anonymous by purposefully inserting noise into the dataset. This can be accomplished by inserting a minimal amount of distraction into the data provided by the database. For instance, a differential privacy method inserts random data into an original data set at the collection stage, masking individual data points before further anonymizing on a server. The introduced distraction is large enough to safeguard privacy while still being constrained enough to ensure that the information provided to analysts is still meaningful.
Because no data point can be linked to a person with 100% certainty, this approach helps to prevent reverse engineering of specific data points from identifying people.
Differential privacy can be used in a variety of settings, including recommendation systems and social networks, as well as location-based applications. It works best on big collections of data, but it’s challenging to scale unless other techniques like federated learning are used. By assessing the privacy loss in the communication among the elements of federated learning, differential privacy can improve data privacy protection.
Federated Learning with Differential Privacy is a means to enabling the scaling of Machine Learning across decentralized data whilst preserving data privacy. This is essential in areas where data is sensitive and privacy is crucial. Some examples include healthcare, financial services, and the IoT as it scales around our homes and cities.
Federated Learning In Healthcare
The healthcare industry has grown increasingly regulated with the 1996 implementation of HIPAA (Health Insurance Portability and Accountability Act). Organizations have found it extremely challenging to implement new technologies due to the scale and complexity of healthcare regulations. As a result, the healthcare industry’s shortage of resources is evident.
FL has the potential to bring AI to the point of care, allowing vast volumes of heterogeneous data from several organizations to be integrated into the model building while adhering to local clinical data regulations.
Larger hospital networks would be better able to collaborate and profit from secure, cross-institutional data access. In addition, smaller community and rural hospitals would benefit from expert-level AI algorithms.
Clinicians would get access to more strong AI algorithms based on data from larger demography of patients for a certain clinical area or from uncommon situations that they would not have encountered locally. They’d also be able to contribute to the algorithm’s ongoing training anytime they disagreed with the results.
Thanks to a secure way to learn from more diverse algorithms, healthcare firms could quickly bring cutting-edge inventions to the market. Meanwhile, rather than relying on the restricted supply of free datasets, research institutes would be able to focus their efforts on actual clinical requirements based on a wide range of real-world data.
Federated Learning In FinTech
Whether it’s mobile banking, payment apps, or Fintech in general, data security has become a critical concern in the Internet world. Businesses that rely on FinTech confront a number of challenges. These concerns include obtaining clearance and lawful consent, data preservation, and the time and expense of gathering and transporting data across networks.
FL is a distributed and encrypted machine learning method that enables cooperative machine learning training on decentralized data without the need for data transmission between participants. It provides solutions for FinTech, for instance, by looking for data breaches and ATO (Account Takeover) Fraud. It can also analyze credit scores and comprehend a user’s digital footprint to prevent fraudulent actions KYC without having to send data to the cloud.
Therefore, FL makes it possible for Fintech to mitigate risks. It develops fresh and inventive techniques for its customers and enterprises and establishes better trust between the two parties.
Federated Learning For Autonomous Vehicles
Furthermore, with real-time data and predictions, federated learning can give a better and safer self-driving car experience. Autonomous vehicles require real-time traffic data and continuous training for better real-time decision making. All of these goals can be met with federated learning, which allows the models to improve over time with input from other vehicles.
Federated Learning necessitates the adoption of new tools and a new way of thinking by machine learning practitioners: model building, training, and evaluation without direct access to or labelling raw data, with communication costs as a limiting factor. For scalability, data protection, and a variety of other reasons, companies like Google, NVIDIA, and other research groups are experimenting with federated learning. The following articles present major highlights of recent advances in machine learning and artificial intelligence when applied with federated learning.
References:
Suggested
Credit: Source link
Comments are closed.