Researchers Introduce ‘SimpleBits’: An Information-Reduction Strategy That Learns To Synthesize Simplified Inputs For Neural Network Understanding

The practice of identifying and labeling groups of pixels or vectors inside an image based on specific rules is known as image classification. One or more spectral or textural properties can be used to create the classification law.
Scientists believe that a deeper knowledge of how deep networks learn information can lead to new scientific discoveries, help us better comprehend the distinctions between human and model behavior, and serve as valuable auditing tools. According to studies, it is essential to understand how neural network-based image classifiers would react to increasingly simple inputs. For this, a clear measure of input simplicity, an optimization goal that correlates with simplification, and a framework to incorporate such a goal into training and inference are required.
Using heuristics-based ablation techniques to mask or eliminate information to generate simpler versions of input, then examining the network’s predictions based on these smaller inputs, is a popular strategy for uncovering correlations between information and learning.
Instead of depending on domain expertise about what information is vital for the network, synthesizing smaller inputs that retrain prediction relevant information could obtain intuition into model behavior without relying on heuristics. To do so, it is essential to first define the precise meaning of “simplify an input,” as well as useful metrics for input simplification and task-relevant information retention.
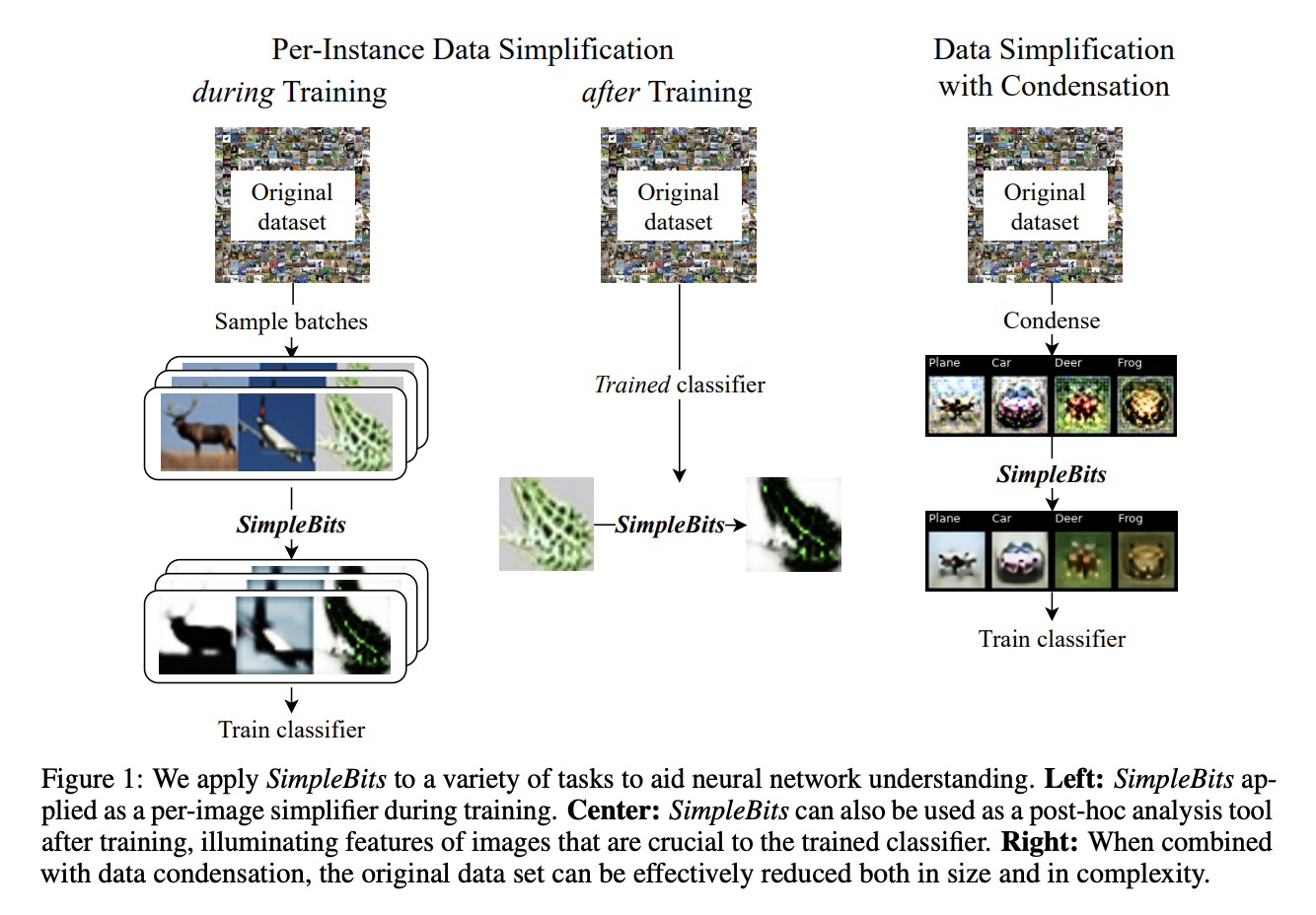
A team of researchers at University Medical Center Freiburg, ML Collective, and Google Brain introduce SimpleBits. This information-reduction strategy learns to synthesize simplified inputs that include less information but is relevant for the job.
The team leverages a result first described as a difficulty for density-based anomaly detection to quantify simplicity. Previous studies show that generative picture models assign greater probability densities and thus lower bits to visually simpler inputs. To simplify inputs, they reduce the encoding bit size given by a generative network trained on a broad image distribution. Simultaneously, they ensure that the simplified inputs retain task-relevant information.
SimpleBits can be used in:
- The per-instance setting, where each image is processed to a simplified version of itself while the size of the training set remains unchanged.
- Condensation setting, where the dataset is compressed to just a few samples per class while the condensed samples are also simplified.
SimpleBits can be used to study the trade-off between information content and task performance during training. After training, it can also be used as an analysis tool to figure out what information a trained model needs to make decisions.
The researchers investigated SimpleBits’ impact on network behavior in a range of settings, including traditional training, dataset condensation, and post-hoc explanations. The researchers observe that their approach provides the following advantages in these settings:
- Per-instance simplification during training: For tasks with injected distractors, SimpleBits successfully removes extraneous data. It highlights plausible task-relevant information in natural image datasets (shape, color, texture). Different datasets define the trade-off between simplifying inputs and task level performance as simplification increases and accuracy decreases.
- Dataset simplification with condensation: They test SimpleBits in a condensation mode, which reduces the training data to a smaller number of simulated images. SimpleBits reduces the encoding size of these photos by a factor of ten without sacrificing task performance. According to findings, it can detect known radiologic features for pleural effusion and gender on a chest radiograph dataset.
- Post-training auditing: They investigate the usage of SimpleBits as an interpretability tool for auditing procedures for a trained model. Their findings suggest that SimpleBits guided audits are capable of providing intuition into model behavior on individual examples, including identifying aspects that may contribute to misclassifications.
The researchers hope that their approach and findings will help in determining what information a deep network classifier needs to master its task and in the more general study of neural network behavior.
Paper: https://arxiv.org/pdf/2201.05610v1.pdf
Suggested
Credit: Source link
Comments are closed.