LinkedIn Introduces DARWIN: A Unified “One-Stop” Data Science and Artificial Intelligence Platform That Would Centralize And Serve The Various Needs Of Data Scientists And AI Engineers

LinkedIn is the world’s largest professional network, producing enormous amounts of high-quality data. Data scientists and AI developers have been using various tools to engage with data via multiple query and storage engines for EDA (exploratory data analysis) and visualization. This created a need for a unified “one-stop” data science platform to consolidate and service the varied demands.
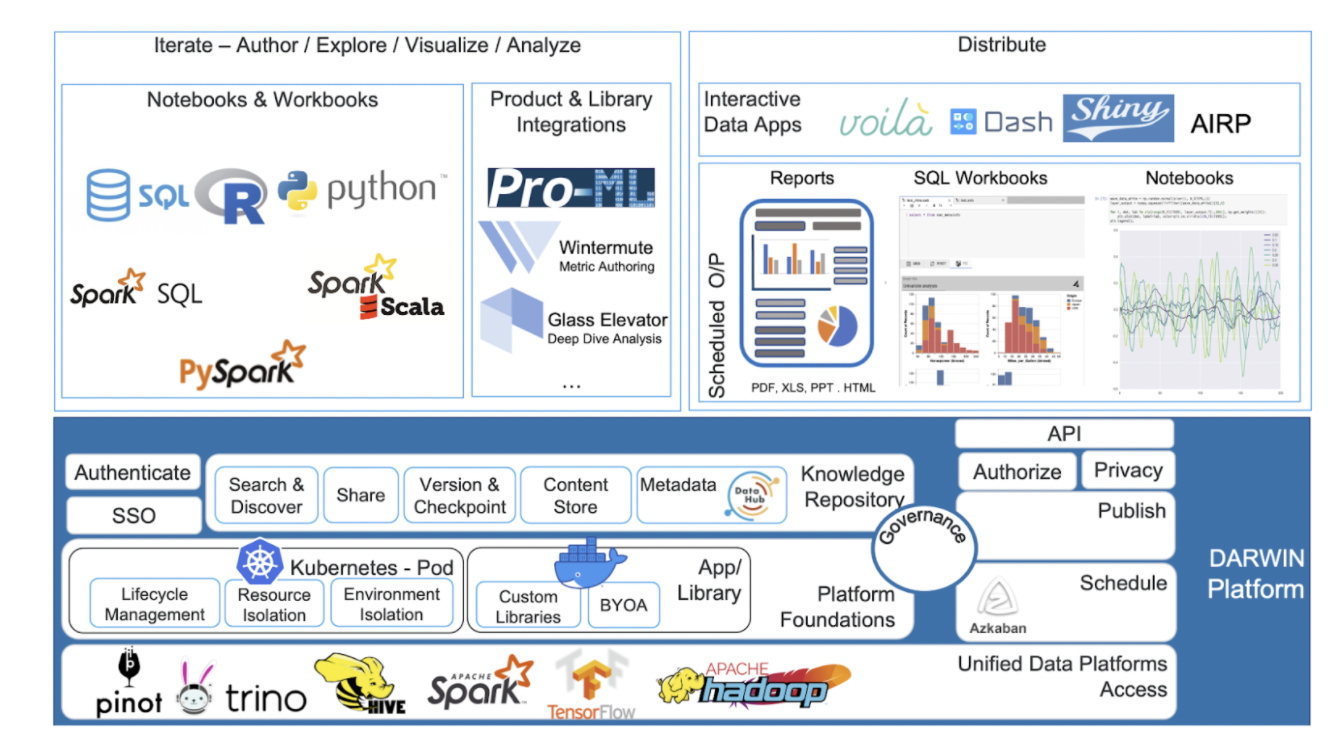
Hence, DARWIN Workbench came into play. DARWIN targeted use-cases similar to those addressed by other prominent data science platforms in the industry. While it uses the Jupyter ecosystem, it goes beyond Jupyter notebooks to meet the full range of data scientists and AI engineers’ needs at LinkedIn.

Before DARWIN, context switching between different tools was required, and cooperation was difficult to achieve, resulting in hampered productivity. Another pre-DARWIN issue was tool fragmentation due to past usage and personal preferences, resulting in information fragmentation, the inability to quickly identify prior work, and the difficulty of sharing results with partners. Furthermore, complying with LinkedIn’s privacy and security regulations for each tool, mainly when utilized locally, resulted in an ever-increasing overhead.
DARWIN was created to meet the demands of all LinkedIn data producers and users, not just data scientists with various skillsets and AI engineers. Establishing the many personas, DARWIN needed to serve and solve their use cases was critical. Expert data scientists and AI engineers, business analysts, metrics developers who generate and publish metrics using LinkedIn’s Unified Metrics Platform (UMP), and data developers.
Data visualization and evaluation are frequently carried out using Jupyter notebooks. Different machine learning libraries, such as GDMix, XGBoost, and TensorFlow, are also used by AI experts to train and evaluate different ML algorithms. Solutions like Tableau and other internal tools were utilized to visualize data and give insights to diverse user personas ranging from engineers to salespeople.

For DARWIN to be seen as a platform that partner teams could use and expand upon, the following requirements were the most essential:
- DARWIN should be a hosted platform for exploratory data analysis, operating as a single window for all data engines and addressing exploratory data analysis demands such as data analysis, data visualization, and model creation.
- Engineers share their work acting as a knowledge repository and enabling cooperation.
- To establish a data library and discover other people’s work, datasets, and insights regarding datasets and articles.
- To allow users to tag and version their artifacts and aggregate them using tags.
DARWIN also includes code support like an IDE, with support for several languages and committing code directly to the project repositories. With LinkedIn’s ethos of providing trusted solutions, DARWIN gives secure and compliant access to the hosted platform.

DARWIN takes advantage of the ecosystem’s other tools. It integrates them so that different user personas could have a unified experience constructing ML pipelines, metric authoring, and data catalogs all in one place. The goal was to transition users away from standalone tools installed on their personal computers while ensuring that this new solution was horizontally scalable and provided a similar experience and resource and environment isolation.
DARWIN can handle a variety of contexts with different libraries, several programming languages, integration with a variety of query engines and data sources, custom extensions, and kernels. It allows users to bring their own app (BYOA) and have it onboarded with DARWIN.
The concept of DARWIN resources was also developed, which helped simply evolve DARWIN into a knowledge repository by separating metadata from storage. DARWIN is also a unified gateway to diverse data platforms because it has access to various data sources and computation engines.
DARWIN: One-stop shop for data platforms
DARWIN supports several engines for querying LinkedIn datasets. Spark can be used with Python, R, Scala, or Spark SQL. Access to Trino and MySQL is also possible. Pinot will be available shortly. DARWIN also gives users direct access to HDFS data, valid when using platforms like Tensorflow. While these are the platforms it currently supports, the goal is to access data throughout LinkedIn, regardless of where it is kept.
The underpinnings of the DARWIN platform
Kubernetes provides scale and isolation. DARWIN needed to be scalable to accommodate the growing number of users who harness the power of data. Kubernetes assisted in achieving both, and its support for long-running services, as well as security measures, made it a no-brainer.
Docker images provide extensibility.
Docker was chosen to democratize the DARWIN platform by allowing other users and teams to extend and innovate on top of it. Docker’s ability to isolate environments enables users to bundle multiple libraries and apps. As a result, it was an excellent fit for DARWIN as a “Bring Your Own Application” (BYOA) environment.
Users can utilize the Jupyter Notebook interface to access Greykite. This end-to-end forecasting library includes input data visualization, model parameterization, and forecast visualization/interpretation.
With pluggable authentication, JupyterHub is highly flexible and can serve many settings. JupyterHub also has a Kubernetes spawner that allows users to launch their own user servers on Kubernetes, giving them their own isolated environment. JupyterHub’s versatility allows to connect it with the LinkedIn authentication stack and ensures that it can support a wide range of apps in the DARWIN ecosystem. JupyterHub also controls the user server lifespan, with the option to cull user servers based on inactivity and explicit logout, achieving some of the main features desired.
Fine-grained access control is used to control access to DARWIN resources, preventing any unwanted access.
In DARWIN, any top-level knowledge artifact users work on, seek to collaborate on, or store is modeled as a resource. Notebooks, SQL workbooks, outputs, articles, projects that contain these artifacts, and any additional artifacts we offer in the future are all examples of resources, each of which is a different resource type.
Resources can also be linked to one another, with the ability to construct a hierarchy that allows to pass down activities that may apply to secondary resources when a top-level resource is activated.
Platform service interacts with storage service to manage DARWIN resource metadata. It serves as the entry point for DARWIN, providing support for authentication and authorization, overseeing the launch of user containers via JupyterHub, and mapping resources to file blobs for storing actual content.
The backing content for a DARWIN resource is abstracted away as file blobs and stored in a persistent backend store. A particular storage service allows evolving the storage layer and backend storage options.
A client-side DARWIN storage library, integrated into any app’s content management, manages the user content moved from the user container to the storage service. This is accomplished in Jupyter notebooks by feeding it into a bespoke implementation of the Notebook Contents API.
In a business situation, collaboration is critical. DARWIN facilitates cooperation between engineers and data scientists by utilizing two main aspects described below.
DARWIN allows sharing resources with others in the spirit of knowledge distribution. Sharing resources will enable developers to learn from and reuse each other’s code.
DARWIN also allows users to search and discover metadata about DARWIN’s resources, with users being able to search resources based on numerous criteria. All of this is made possible by DataHub, which also has the added benefit of permitting the discovery of DARWIN resources currently in development. Unless the resource owner shares explicitly it with results, the resource surfaced has only a “code” view by default.
The DARWIN frontend also allows you to browse resources and execute CRUD actions on them, as well as switch between execution contexts. Code completion, doc help, and function signatures are some of the most significant elements in an IDE, and Intellisense stands for them.
DARWIN’s similar experience allows developers to combine code creation and testing with data in one place.
SQL workbooks have a SQL editor and the ability to conduct spreadsheet operations such as searching, filtering, sorting, pivoting, and so on.
The ultimate goal is to include built-in visualizations for the data searched and produce reports and a catalog view with dataset profiles. These new capabilities would make it easier for business analysts and citizen data scientists who don’t do complex analysis (constructing models, querying data, or looking at visualizations and dataset profiles) to swiftly examine and understand data.
For data scientists, executing repeatable analysis with new data created regularly is a vital step towards productionizing. DARWIN’s ability to schedule notebooks and workbooks met a critical demand for consumers.
DARWIN’s scheduling uses Azkaban to declare parameters that may subsequently be used in code.
DARWIN adds support for Frame, an internal feature management tool used for ML applications, and Tensorflow to meet the needs of experienced data scientists and AI engineers.
DARWIN has also linked with internal LinkedIn technologies to enable capabilities such as error and validation, developing metric templates, testing, reviewing, and code uploads, all in one location, to meet the needs of metrics developers. Greykite, forecasting, anomaly detection, and root cause analysis framework can now employ DARWIN thanks to the modification feature.
What comes next?
DARWIN is still evolving, intending to become LinkedIn’s default and one-stop platform for data scientists, AI engineers, and data analysts.
There is the concept of projects in DARWIN, which will serve as user namespaces. While projects are currently public, DARWIN will soon allow users to manage, and version controls their projects using Git. These workspaces will be backed up by network-attached storage (NAS), deployed as a volume.
The long-term goal for DARWIN is to actualize all of the use cases that support the development lifecycles of multiple user personas and get to a point where DARWIN can either keep the functionality of surrounding tools or integrate with external apps and frameworks.
Reference: https://engineering.linkedin.com/blog/2022/darwin–data-science-and-artificial-intelligence-workbench-at-li
Suggested
Credit: Source link
Comments are closed.