Researchers at the Taiwan Semiconductor Manufacturing Company Propose a four-Megabit nvCIM Macro for Edge AI Devices

Edge AI devices perform tasks by combining artificial intelligence (AI) and edge computing approaches. The advantages of edge AI include speed and the ability to detect concerns by integrating smart devices and functionality to deploy AI at the edge for insights. Because of their versatility, intelligent devices may be used in various industries. They’re quickly becoming an essential part of the Internet of Things (IoT) ecosystem. Smart speakers, smartphones, robotics, self-driving cars, drones, and data-processing surveillance cameras are among these products.
Non-volatile computing-in-memory (nvCIM) architectures are a new computing system that reduces data migration between processors and memory components. This technique can drastically lower the latency and energy consumption of complicated AI computations. Most of these technologies have low energy efficiency, inference accuracies, and battery life.
Researchers at Taiwan Semiconductor Manufacturing Company (TSMC) have created a new four-megabit (4Mb) nvCIM technique to help edge AI devices operate better overall. Memory cells and peripheral circuitry are combined in their suggested architecture based on complementary metal-oxide-semiconductor (CMOS) technology.
NvCIM’s primary purpose is to let battery-powered AI edge devices overcome the memory-wall bottleneck by providing analog operations for vector-matrix multiplication. NvCIM architectures can significantly reduce the amount of data transferred between processors and memories in AI smart objects while the gadgets undertake inference and power-on procedures on-chip. During the inference stage of the neural network, matrix multiplication is the most crucial computing activity.
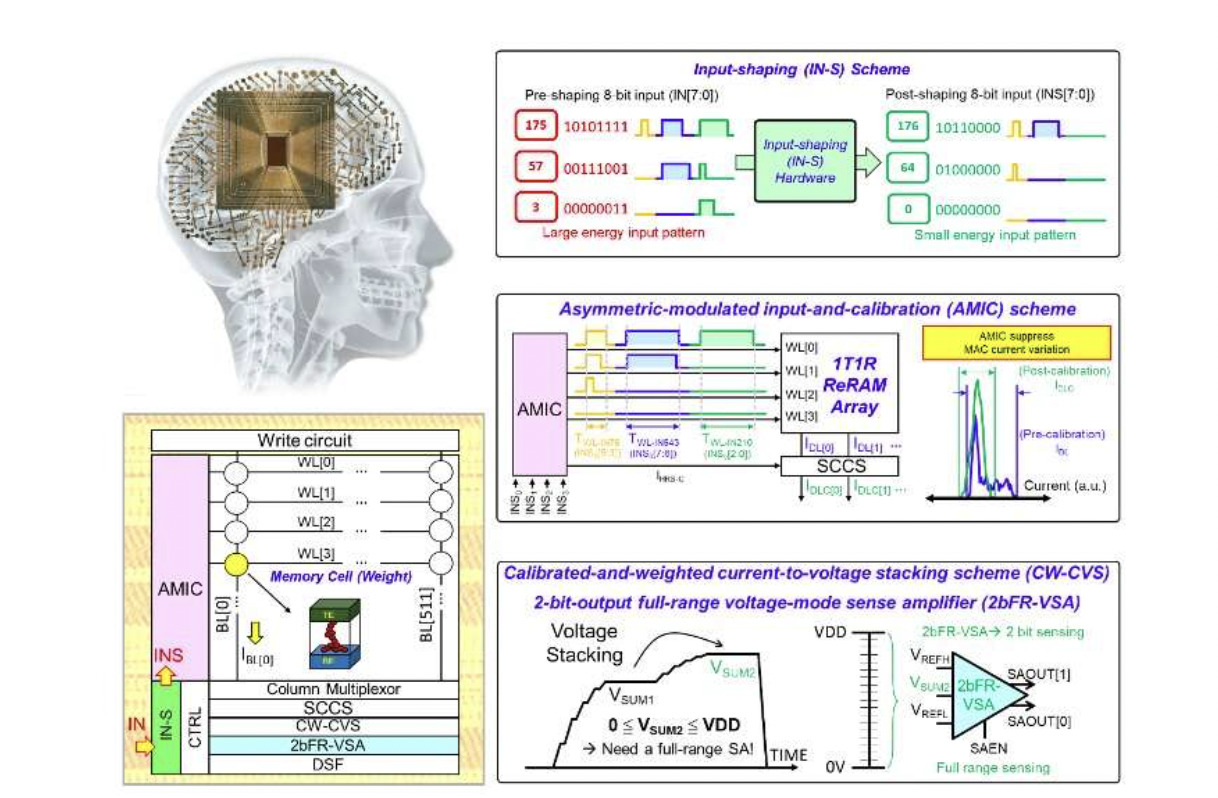
In addition, the researchers used software-hardware co-design methodologies to create a hardware-based input-shaping circuit. They believe that they can increase energy efficiency by doing so while maintaining system-level inference accuracy. However, the demand to minimize computing latency and increase readout accuracy is growing. The objective is to create an asymmetrically modulated input-and-calibration (AMIC) method for this purpose.
Across a wide range of application scenarios, the framework can fix complicated computing tasks. The researchers used a calibrated and weighted current-to-voltage stacking circuit with a 2-bit output and full-range voltage-mode sense amplifier to reduce the computing latency of their device. This circuit also ensures a high readout yield for the most significant bits (MSBs), lowering the overall readout energy of the architecture.
Drawing a comparison to other nvCIM models:
- Higher precision
- Higher computing throughput
- Larger memory capacity
- Lower computing latency
It’s one thing to solve recurring issues. Still, the architecture built also can improve the performance and energy efficiency of various edge AI devices, ranging from smart phones to more advanced robotic systems. It can support basic vector-matrix multiplications (VMMs) performed by many neural network models, such as convolutional neural networks (CNNs) for image classification or deep neural networks (DNNs), among other things (DNNs).
What can we expect in the future?
- Circuit level optimization
- nvCIM Architecture novelty
- Specification improvement
- nvCIM Macro performance
Apart from that, software-hardware co-design will be a primary priority. The researchers want to create nvCIM-friendly neural network methods to improve the performance of the nvCIM macro even more. It doesn’t stop there; the researchers will have reached a pinnacle if they can incorporate the nvCIM macro and other required digital circuits into a chip-level system design for next-generation AI chips.
Paper: https://www.nature.com/articles/s41928-021-00676-9
Reference: https://techxplore.com/news/2022-01-four-megabit-nvcim-macro-edge-ai.html
Suggested

Credit: Source link
Comments are closed.