AstraZeneca Researchers Explain the Concept and Applications of the Shapley Value in Machine Learning
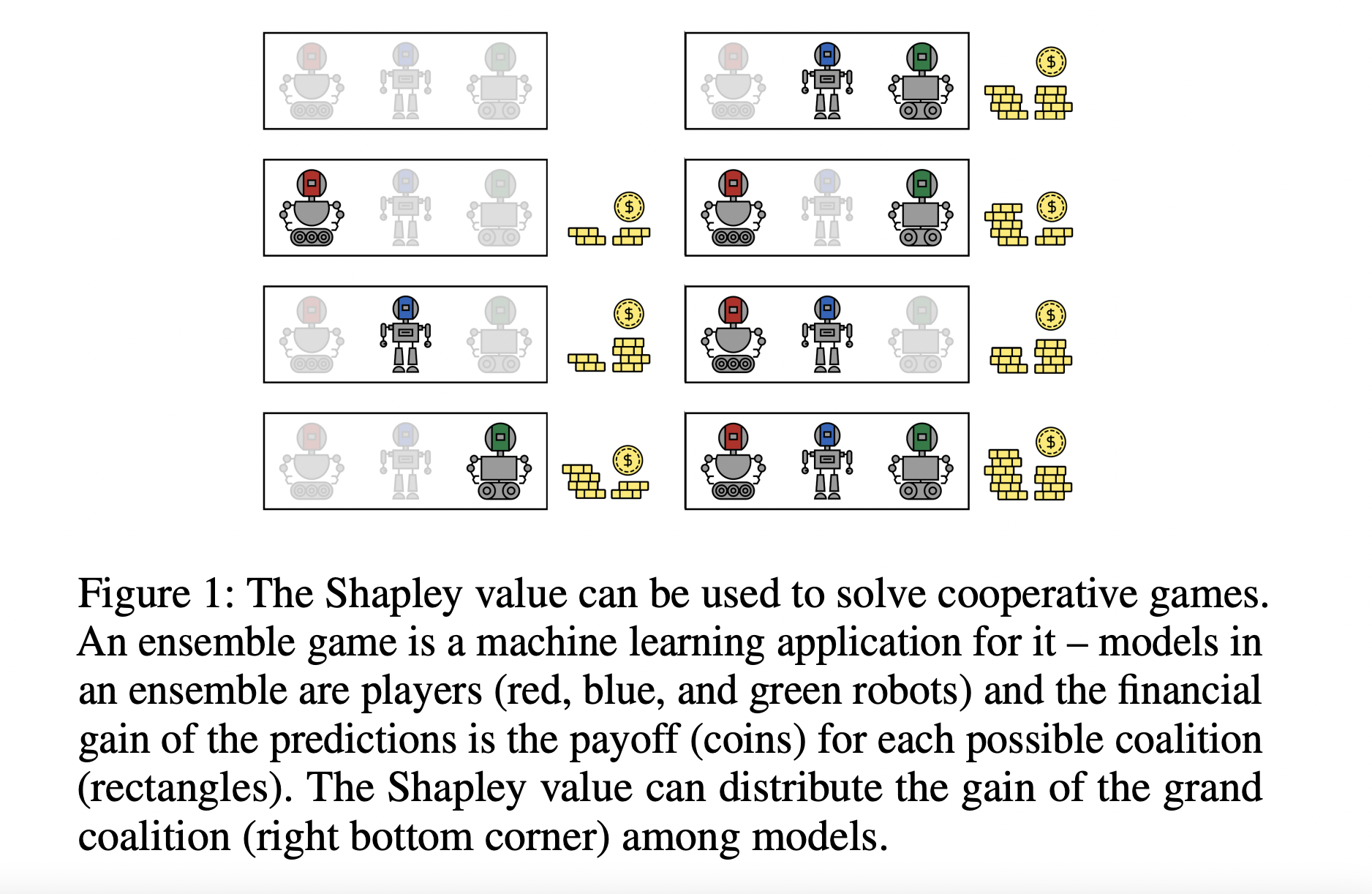

In many practical areas of machine learning, such as explainability, feature selection, data valuation, ensemble pruning, and federated learning, measuring relevance and attribution of various gains is a crucial topic.
For example, one may wonder: How important is a certain feature in a machine learning model’s decisions? What is the value of a single data point? Which models in an ensemble are the most valuable? Specific ways have been used to solve these concerns in various sectors.
Surprisingly, as a solution to a transferable utility (TU) cooperative game, there is also a generic and unified approach to these concerns. TU game solution concepts, in contrast to other techniques, are theoretically motivated by axiomatic properties. The Shapley value is the most well-known example of this type of solution, which is defined by various desiderata such as fairness, symmetry, and efficiency.
A cooperative game in the TU context consists of a player set and a scalar-valued characteristic function that defines coalition value (subsets of players). The Shapley value provides a rigorous and accessible way to allocate the team’s aggregate value (e.g., income, profit, or cost) between players in such a game.
Two components must be developed before this approach can be used for machine learning: the player set and the characteristic function. Players can be represented in a machine learning scenario by a set of input features, reinforcement learning agents, data points, ensemble models, or data silos. The characteristic function can then be used to explain model goodness of fit, reinforcement learning rewards, financial gain on instance level predictions, and out-of-sample model performance.
The Shapley value, a solution idea that helps apportion rewards in cooperative games to individual participants, is introduced in a new study co-published by academics from Astra Zeneca, University of Edinburgh, Toulouse School of Economics, and Central European University. They go over its characteristics and why they’re significant in machine learning. The team discusses feature selection, data valuation, explainability, reinforcement learning, and model valuation as uses of the Shapley value in machine learning. Finally, they analyze the Shapley value’s limitations and suggest future options.
The researchers outline the Shapley value’s solution concept qualities and underline their importance and meaning in a feature selection game. In this game, players are input features, coalitions are subsets of features, and the payout is scalar-valued goodness of fit for a machine learning model utilizing these input features. This goodness of fit is the sum of the relevance measures assigned to individual aspects by an efficient solution concept. This enables the contribution of specific features to the overall performance of the trained model to be quantified.
When two traits have the same marginal contribution to the goodness of fit when added to any feasible coalition, the symmetry property implies that their relevance is the same. This trait is essentially fair handling of the input information, as it assigns the same priority value to equal features. In the feature selection game, the Shapley values of input features generated on the pooled dataset would be the same as summing the Shapley values determined on the two datasets separately.
The training set data points are participants in the data valuation game, and the payment is determined by the model’s goodness of fit on the test data. In a data valuation game, calculating the Shapley value of players determines how much data points contribute to the model’s performance. The Shapley value isn’t the only way to evaluate data; prior studies employed functions, leave-one-out testing, and core sets. However, when the data valuation process imposes fairness requirements, these methods fall short.
By portraying the data owners as players who collaborate to train a high-quality machine learning model, a federated learning scenario can be viewed as a cooperative game. Monte Carlo sampling is used in the described system to approximate the Shapley value of data flowing from data silos in linear time. Given the potentially overlapping nature of the datasets, using configuration games as a future step could be fascinating.
The Shapley value is used in explainable machine learning to measure the contributions of input features to a machine learning model’s output at the instance level. The purpose is to decompose the model prediction and assign Shapley values to distinct aspects of the instance given a certain data point. There are model-agnostic universal solutions to this problem, as well as designs tailored for deep learning, classification trees, and graphical models.
The only criterion for a cooperative game for universal explainability is that the model may generate a scalar-valued output, such as the likelihood of a class label being assigned to an instance. Because the efficiency principle holds, calculating the Shapley value in a game like this allows for a complete deconstruction of the prediction. Missing input feature values are imputed using a reference value such as the mean derived from several occurrences, and Shapley values of feature values are explanatory attributions to the input features.
Limitations
The Shapley value has a large impact on machine learning, but it has limitations, and some extensions of the Shapley value could have significant machine learning applications. In a TU game, calculating the Shapley value for each player naively requires factorial time. The exact calculation of the Shapley value is not tractable in large-scale data valuation, explainability, and feature selection contexts.
The Shapley values are, by definition, the average marginal contributions of players to the grand coalition payoff derived from all permutations. Non-game theory experts will find this type of theoretical interpretation unintuitive and useless. This makes it difficult to translate the meaning of Shapley values received in a variety of application areas to actions.
Conclusion
The team addressed the Shapley value, looked at its axiomatic characterizations, and looked at the most common Shapley value approximation methodologies in the study. They described and examined its applications in machine learning, as well as concerns with the Shapley value and prospective new machine learning application and research fields.
Paper: https://arxiv.org/pdf/2202.05594v1.pdf
Related Github: https://github.com/benedekrozemberczki/shapley
Suggested

Credit: Source link
Comments are closed.