Recognizing Chemical Formulas from Research Papers Using a Transformer-Based Artificial Neural Network

In the last few years, deep learning has been playing an integral role in various scientific and technology areas. This development promotes AI-based tools that can help us with information retrieval. Modern deep learning technologies, which typically demand enormous volumes of qualitative data for neural network training, will also transform chemistry.
The good news is that chemical data holds up well over time. Even though a molecule was first synthesized more than a century ago, information regarding its structure, characteristics, and synthesis methods is still helpful today. Even in this age of universal digitalization, an organic chemist may turn to a thesis from a library collection for information about a poorly studied molecule published as far back as the early twentieth century.
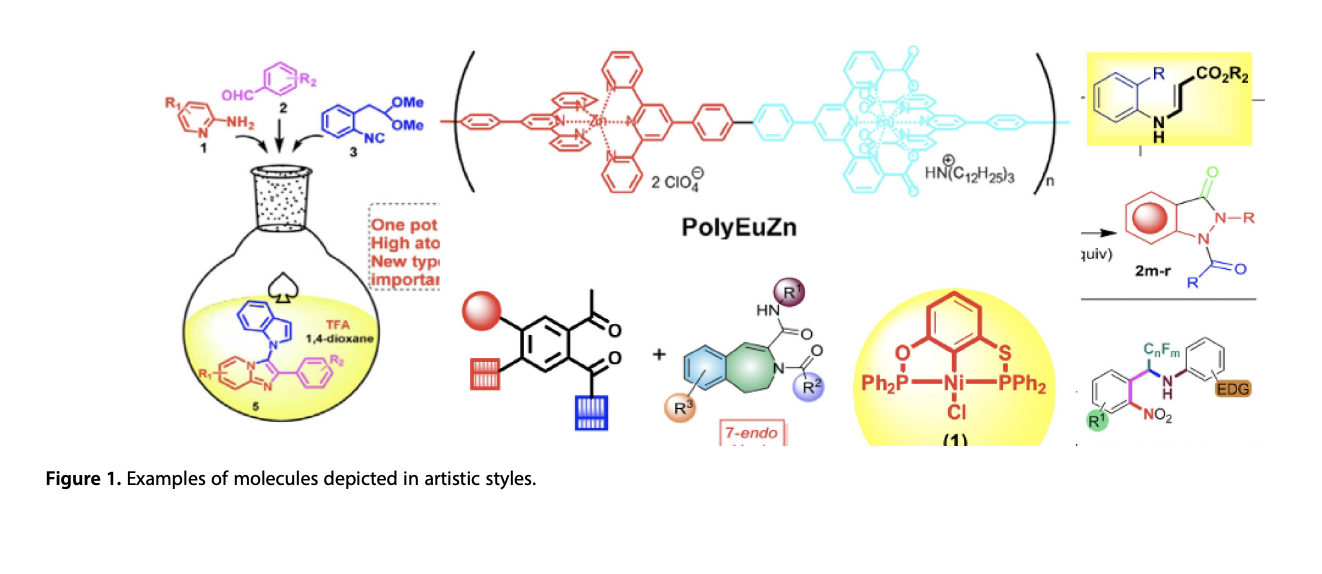
There is no available universally agreed method of presenting chemical formulas. Chemists employ a variety of shorthand notation strategies to represent common chemical groupings. “tBu,” “t-Bu,” and “tert-Bu” are all viable substitutes for the tert-butyl group. To make matters worse, chemists frequently employ a single template with many “placeholders” (R1, R2, etc.) to refer to a large number of identical compounds. Still, those placeholder symbols could be described anywhere: in the figure itself, the article’s running text or supplements. The drawing styles fluctuate from journal to journal and evolve, scientists’ personal preferences shift, and norms change. As a result, even a seasoned scientist can become perplexed when solving a “puzzle” discovered in a magazine article. The problem appears intractable to a computer algorithm.
Using artificial intelligence, researchers from Syntelly—a startup that originated at Skoltech and Sirius University have developed a neural network-based solution for automated recognition of chemical formulas on research paper scans.
The researchers had already tackled similar challenges with Transformer, a neural network first developed by Google for machine translation, as they approached it. The researchers employed this sophisticated tool to convert the image of a molecule or a molecular template to its written representation rather than translating words between languages. With this Transformer-based architecture, named ‘Image2SMILES’, image recognition could be notably improved for recognizing chemical structures.
The neural network could learn practically anything, much to the researchers’ astonishment, as long as the relevant depiction style was represented in the training data. On the other hand, Transformer needs tens of millions of instances to train on, and manually collecting that many chemical formulas from research publications is complex. Instead, the scientists used a different method and developed a data generator that generates molecular template instances by merging randomly picked molecule fragments and portrayal styles.
The research team thinks their method will be a significant step toward developing an artificial intelligence system. This system will be capable of “reading” and “comprehending” research papers to the same level as a highly-skilled chemist.
Paper: https://chemistry-europe.onlinelibrary.wiley.com/doi/pdfdirect/10.1002/cmtd.202100069
Reference: https://techxplore.com/news/2022-02-neural-network-chemical-formulas-papers.html
Suggested

Credit: Source link
Comments are closed.