IBM Researchers Built a Machine Learning Model That can Help Harness the Power of Enzymes for Greener Chemistry

The development of ecologically acceptable biochemical substitutes for industrial processes might be accelerated thanks to nature’s molecular machinery.
Enzymes are the master accelerators of nearly every activity in the human body, helping with everything from digestion to the breakdown of hazardous chemicals and even DNA replication. Enzymes’ relevance extends beyond biology; they’re also utilized to make industrial chemical processes more environmentally friendly by reducing energy consumption and the number of harmful solvents needed in their production. The enzyme Xylanase treatment in paper manufacture, for example, has been demonstrated to reduce chlorine usage by 15% and toxic adsorbable organic halides (a chlorine byproduct) by 25% when producing white paper for printing or use in notebooks.
Protease enzymes help make cookies crumbly by decomposing gluten in wheat flour, while xylanase helps minimize the quantity of chlorine-based bleach used in baking. However, because selecting the proper enzymes is challenging, there aren’t many commercial applications where enzymes are used extensively. It sometimes necessitates a considerable lot of domain-specific information that no one chemist, or team of chemists, could ever possess. According to AI, the function of enzymes is linked to the necessity for industrial chemicals.
The world really needs to make the items we use more sustainable.
Enzymes, the small molecular machinery that speeds up chemical reactions that keep practically all living creatures alive — as well as accelerate many manufacturing processes — may hold the key to making ordinary compounds. However, the difficulty in selecting the proper enzyme for the right chemical reaction prevents their broad commercial application.
To overcome this challenge, IBM researchers built a machine learning model that can assist scientists in predicting which enzymes would be acceptable substitutes for a specific process. By leveraging the biological catalysts that have been honed by our nature’s 3.5 billion year-long evolutionary processes, we may be able to get closer to more sustainable and safer methods.
The new bio catalyzed synthesis planning data-driven AI model comes in. The model is trained using publicly accessible USPTO data on enzymatic biocatalysis. In theory, it eliminates the requirement for a human biocatalysis specialist to identify the appropriate enzyme and substrate to create a particular chemical. The approach bridges a knowledge gap that frequently inhibits more sustainable bio catalyzed reactions from being employed in the industry.
The lack of accessible data to train the model significantly impacts the accuracy of several subcategories of enzymes. Users with access to private information on those specific subclasses of enzyme processes, on the other hand, may reduce this by fine-tuning the model and increasing its predictive ability.
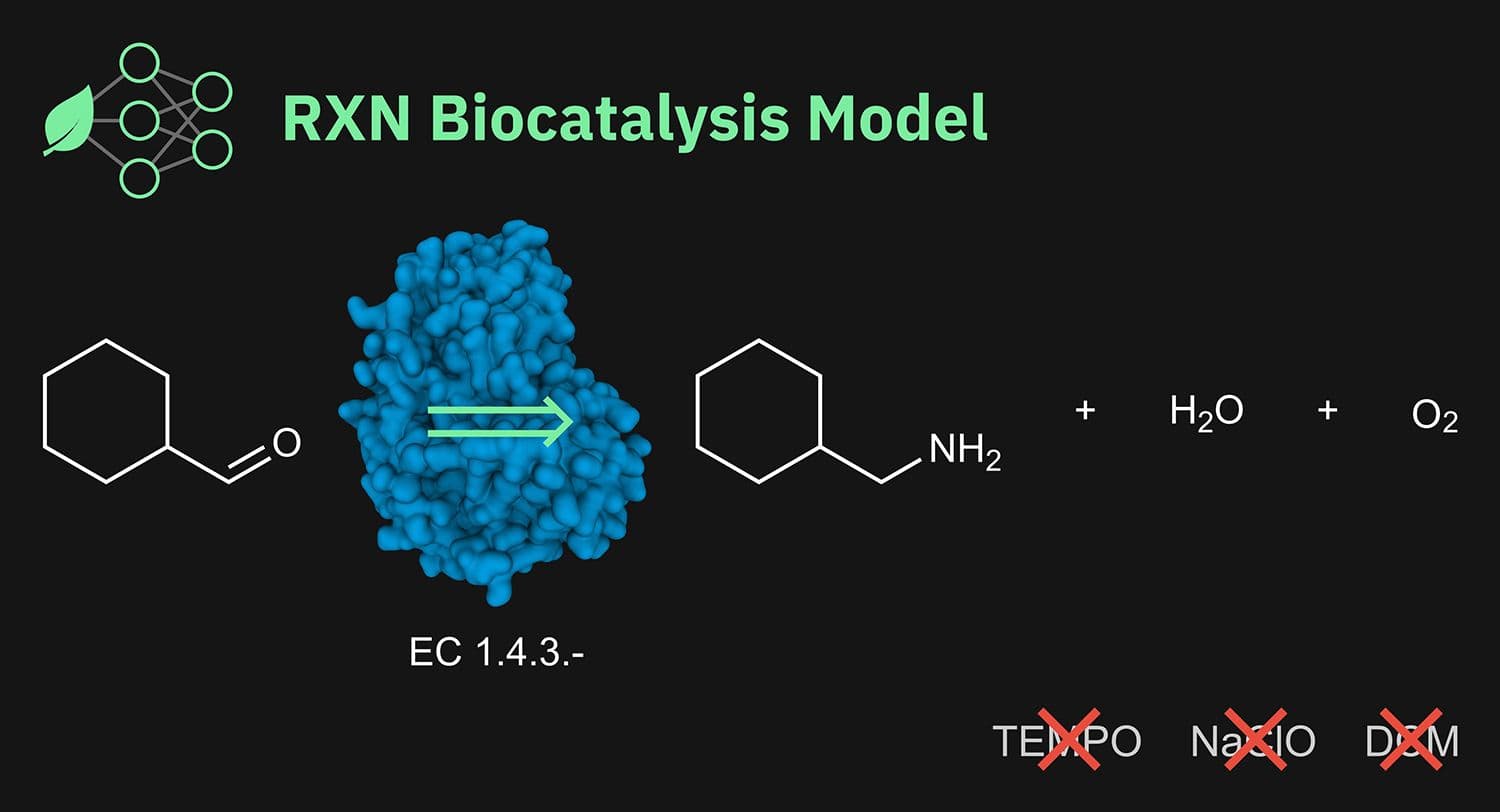
The graphic depicts a retrosynthesis reaction — product on the left, substrates on the right — with the EC number used to identify enzymes and the enzyme’s fundamental structure (blue) in the backdrop.
The extra chemicals employed in the non-bio catalyzed form of the process are shown on the bottom right.
We employed multitask transfer learning to create and train our model, which involves learning from a tightly concentrated database of bio catalyzed events and a broader database including various other chemical processes.
This database helps the model to learn more generic chemical traits.
The model may then use this information to learn from a more limited group of bio catalyzed processes.
Consider how a person learning to play an instrument, such as the guitar, might benefit them if they later attempt to discover a related tool, such as the bass.
Multitasking is like studying both the guitar and the bass simultaneously.
And in the context of chemistry, it means that, rather than training the model sequentially, we introduced it concurrently on the general and particular data sets of enzyme processes.
Compared to a method in which the training was done in two phases, the simultaneous training improved model performance.
Despite the lack of data for training, our model could forecast with a high degree of accuracy. In some cases, it even rectified inaccuracies detected in our ground truth — the component of the dataset used to test the model — where the products of specific reactions were incorrectly calculated.
RoboRXN can now do many tasks while searching for the ideal green enzyme.
IBM’s efforts to help develop what’s next in science and engineering are focused on accelerating the discovery of innovative materials.
It’s the kind of thing we’re working on with RoboRXN, an AI-powered, data-driven, cloud-based platform for chemical synthesis automation.
RoboRXN’s capabilities are being expanded with a new tool to enable the usage of enzymes for more ecologically friendly chemistry, thanks to our new machine learning model.
Anyone may use the trained model and the code because they are publicly available. Chemists will use them in their research initiatives, something we are excited about. The enzyme-hunting code is available on GitHub, or you can start a project with a trained one here.
Github: https://github.com/rxn4chemistry/biocatalysis-model
Project: https://rxn.res.ibm.com/
Paper: https://www.nature.com/articles/s41467-022-28536-w.pdf
Reference: https://research.ibm.com/blog/ml-for-enzyme-powered-green-chemistry
Suggested
Credit: Source link
Comments are closed.