Google AI Introduces Full-Attention Cross-Modal Transformer (FACT) Model And A New 3D Dance Dataset AIST++

Dance has always been a significant part of human culture, rituals, and celebrations, as well as a means of self-expression. Today, there exists many forms of dance, from ballroom to disco. Dancing, however, is an art form that needs practice. Professional training is typically required to create expressive choreography for a dancer with a repertory of dance movements. Although this process is difficult for people, it is considerably more difficult for an ML model as the task involves producing a continuous motion with high cinematic complexity and the non-linear relationship between the movements and the accompanying music.
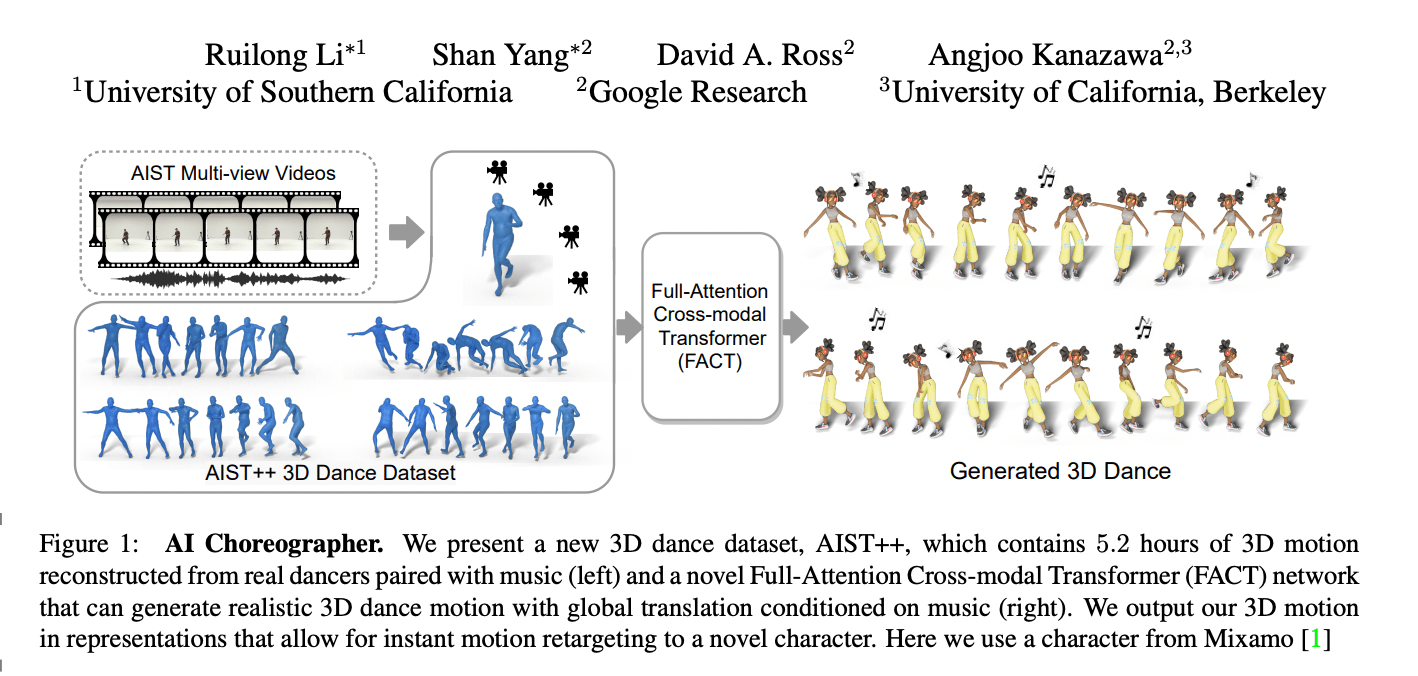
A new Google study introduces the full-attention cross-modal Transformer (FACT) model, which can mimic and understand dance motions and even improve a person’s ability to choreograph dance. In addition to this, the team released AIST++, a large-scale, multi-modal 3D dance motion dataset. This dataset contains 5.2 hours of 3D dance motion in 1408 sequences spanning ten dance genres, each with multi-view videos and known camera poses. Their findings suggest that the FACT model outperforms current state-of-the-art methods in extensive user studies on AIST++.
To create a 3D motion dataset, the researchers used the existing AIST Dance Database, a collection of dance films with musical accompaniment but no 3D information. There are ten dance styles in AIST: Old School (Break, Pop, Lock, and Waack) and New School (Break, Pop, Lock, and Waack) (Middle Hip-Hop, LA-style Hip-Hop, House, Krump, Street Jazz, and Ballet Jazz). These cameras are not calibrated, even though it provides multi-view videos of dancers.
They were able to reconstruct the camera calibration parameters and 3D human motion using parameters from the widely used SMPL 3D model. AIST++, the resulting database, is a large-scale, 3D human dancing motion dataset featuring a wide range of 3D motion matched with music.
All ten dance styles are evenly represented in the motions, covering a wide range of music tempos in beats per minute (BPM). There are 85 percent basic motions and 15 percent advanced movements in each dance genre (longer choreographies freely designed by the dancers). The AIST++ dataset also includes multi-view synchronized picture data, which can be used in various study areas, including 2D/3D, pose estimation.
The model must learn the one-to-many mapping between audio and motion, which poses a unique problem in cross-modal sequence-to-sequence synthesis. They use AIST++ to create non-overlapping train and test subsets, ensuring that no choreography or music is shared between them.
The FACT Model
The team used this dataset to train the FACT model to produce 3D dancing from music. Using independent motion and audio transformers, the model first encodes seed motion and audio inputs. The embeddings are then concatenated and delivered to a cross-modal transformer, learning how the two modalities correspond and generating N future motion sequences. These sequences are then utilized to self-supervise the model’s training. End-to-end, all three transformers are learned together. They use this model in an autoregressive framework at test time, with the anticipated motion as the input to the next generation phase. As a result, the FACT model can generate frame-by-frame long-range dance motion.

FACT includes the following three crucial design decisions for creating realistic 3D dance motion from music.
- Since internal tokens have access to all inputs, all transformers utilize a full-attention mask, which can be more expressive than traditional causal models.
- Instead of only predicting the next motion, they trained the model to anticipate N futures beyond the present input. This helps avoid the model from motion stalling or diverging after a few generation steps by encouraging the network to pay greater attention to the temporal context.
- Furthermore, they use a deep 12-layer cross-modal transformer module to fuse the two embeddings (motion and audio) early in the training process, which is critical for training a model that listens to the input music.
The researchers evaluate the model’s performance based on three metrics: motion quality, generation diversity, and motion-music correlation.
- Motion Quality: To determine motion quality, they calculated Frechet Inception Distance (FID), the distance between the AIST++ test set’s genuine dancing motion sequences, and 40 model-generated motion sequences, each with 1200 frames (20 secs). The geometric and kinetic properties of the FID are denoted as FIDg and FIDk, respectively.
- Generation Diversity: They compute the average Euclidean distance in the feature space across 40 created movements on the AIST++ test set. They examine the model’s capacity to generate various dance motions by comparing geometric feature space (Distg) and kinetic feature space (Distk).
- Motion-Music Correlation: They propose a new metric, called Beat Alignment Score, to assess the association between input music (music beats) and output 3D motion (kinematic beats) because no well-designed metric exists (BeatAlign).

They compare the performance of FACT on each of these metrics to that of other state-of-the-art methods. The results demonstrate that the 3D dance generated using the FACT model is more realistic and better connected with input music than previous methods such as DanceNet and Li et al.
Paper: https://arxiv.org/abs/2101.08779
Project: https://google.github.io/aichoreographer/
GitHub: https://github.com/google-research/mint
Dataset: https://google.github.io/aistplusplus_dataset/
Model: https://github.com/google-research/mint
Source: https://ai.googleblog.com/2021/09/music-conditioned-3d-dance-generation.html
Suggested
Credit: Source link
Comments are closed.