Meta AI Introduces ‘No Language Left Behind’ Project: An AI Model To Support Machine Translation For Low-Resource Languages
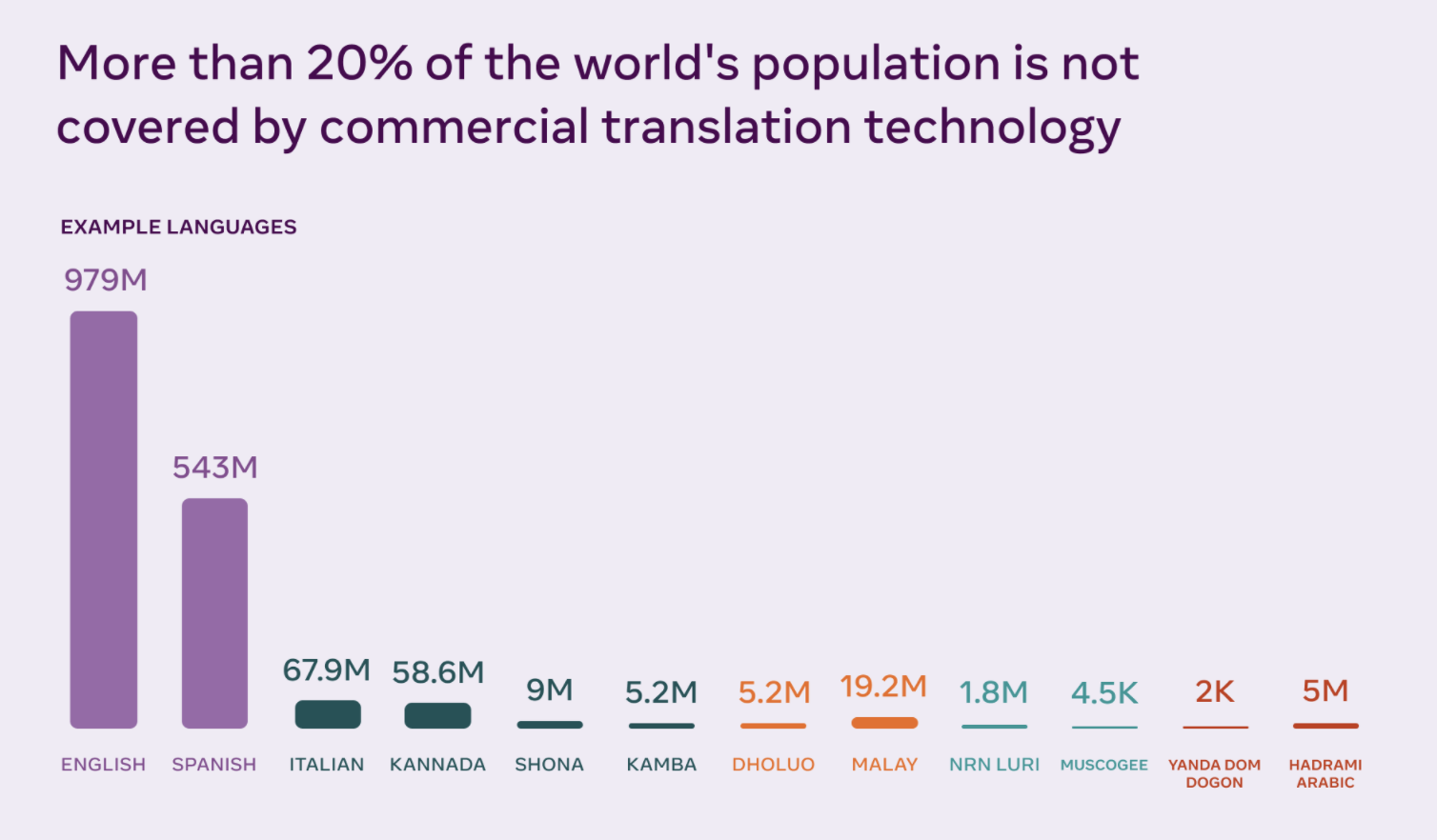

With the advancement in AI, machine translation systems are quickly improving. They still rely significantly on learning from vast volumes of textual data. This is one of the reasons why they don’t perform well for low-resource languages, such as those without training material or those without a standardized writing system.
Data scarcity is one of the most significant roadblocks to expanding translation systems to other languages. Expanding to more languages necessitates locating and utilizing training examples from languages with a limited online presence. As a result, MT systems capable of producing high-quality translations have been developed only for the web’s most popular languages.
Most MT systems today are bilingual. According to researchers, scaling this approach to dozens of language pairs, let alone all of the languages spoken worldwide, is extremely difficult.
A team of researchers at Meta AI is working on developing language and machine translation capabilities that will cover most of the world’s languages. Their work includes two projects: No Language Left Behind, a new AI model that can be trained to learn languages with fewer examples allowing expert-quality translations in hundreds of languages, from Asturian to Luganda to Urdu. The second project is Universal Speech Translator, which includes unique methods for translating from one language’s speech to another in real-time. This will enable models to support languages that do not have a regular writing system.
To enable automatic data set development of low-resource languages, the team presents LASER, an open-source toolkit that presently includes over 125 languages written in 28 different scripts. LASER combines multiple language sentences into a single multilingual representation. The researchers then use a large-scale multilingual similarity search to locate statements with similar representations or sentences that are likely to have the same meaning in various languages.
To overcome the problem of data scarcity, the team developed a unique teacher-student training paradigm that allows LASER to function at a large scale across multiple languages. This training method lets LASER focus on specific language subgroups and learn from considerably smaller data sets.
LASER has also been developed to work with speech, allowing users to extract translations between one language’s speech and another’s text. It even allows direct speech-to-speech translations by combining speech and text representations in the same multilingual environment.
The present speech translation benchmark includes data for only a few languages. Therefore, the team designed CoVoST 2 to encompass 22 languages and 36 language directions with varying resource conditions. VoxPopuli is a large-scale multilingual speech corpus for representation learning, semi-supervised learning, and interpretation. It comprises 400,000 hours of speech in 23 languages. VoxPopuli was utilized to create the world’s largest open and universal pretrained model for 128 languages and speaking tasks. On the CoVoST 2 data set, this model improved the previous SOTA for speech-to-text translation from 21 languages into English.
The team has focused on designing models that train efficiently despite enormous capacity, focusing on sparsely gated mixture-of-expert models to increase the overall performance of MT models. They could balance high-resource and low-resource translation performance by expanding model size and developing an autonomous routing function so that various tokens employ different expert capacities.
They designed the first multilingual text translation system that is not English-centric to scale text-based MT to 101 languages. Typical bilingual systems translated the source language into English and then back into the target language. The team decided to eliminate English as a medium. It allows languages to be translated directly into other languages without going via English, thereby improving the efficiency and quality of these systems.
Multilingual models were previously unable to achieve the same degree of quality as bespoke bilingual systems, despite the fact that removing English enhanced the model’s capability. On the other hand, Meta’s MT systems are found to surpass even the most advanced bilingual models.
Researchers are now also working on a speech-to-speech translation system that doesn’t generate an intermediate textual representation during inference to make their technology more inclusive. This method outperforms a standard cascaded system that combines independent voice recognition, machine translation, and speech synthesis, models.
They also plan to add some features of the input audio, such as intonation, in the generated audio translations to do spoken translations that keep the expressiveness and character of everyone’s voice.
The researchers added that evaluating a large-scale, multilingual model is a difficult task. This is because it demands expertise in all of the languages covered by the model. To that end, the team introduced FLORES-101, the first multilingual translation assessment data set, which covers 101 languages. FLORES-101 enables researchers to measure the performance of systems in every language direction, not just English-to-English translation.
The team hopes that their work will inspire researchers to bring real-world translation system applications closer to reality.
Reference: https://ai.facebook.com/blog/teaching-ai-to-translate-100s-of-spoken-and-written-languages-in-real-time
Suggested
Credit: Source link
Comments are closed.