Salesforce AI Research Propose ‘BLIP’: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation

Just how humans use vision and language to experience the environment, AI models are built on the foundations of vision and language.
Vision-language pre-training has been widely adopted to enable AI agents to understand the world and communicate with humans. This approach involves training a model on image-text data to teach how to grasp both visual and written information. The model is pretrained before fine-tuning it. Skipping this step would reduce the model’s performance because the model then must be trained from the beginning on each subsequent task.
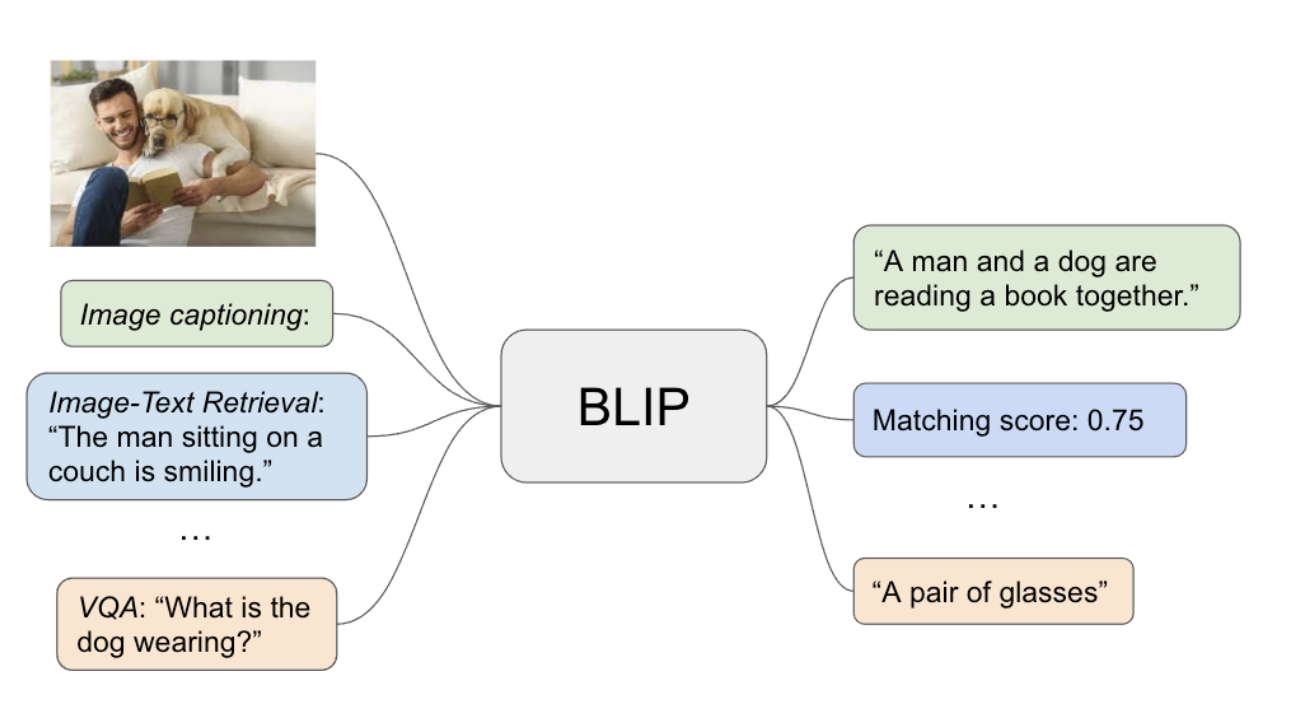
Vision-language pre-training has proven to improve performance on downstream vision-language tasks like image-text retrieval, image captioning, and visual question answering.
But, the majority of available pre-trained models aren’t adaptable enough to a wide range of vision-language tasks. This is because the encoder-based models are more difficult to apply directly to text production tasks, whereas encoder-decoder models have yet to be accepted for image-text retrieval. Further, models are pre-trained on the picture and alt-text pairs automatically acquired from the web. However, site writings frequently misrepresent the visual content of images.
To overcome these issues, the salesforce team has come up with BLIP: Bootstrapping Language-Image Processing for comprehension and development of a unified visual language model. BLIP has a novel model architecture that allows for a broader range of downstream tasks than previous methods and also includes a new dataset bootstrapping strategy for learning from noisy web data.
To overcome this issue of captions from noisy image-text pairs, the team uses two modules:
- Captioner: a text decoder that works with images to generate synthetic captions as extra training examples based on the web images.
- Filter: a text encoder with picture grounding to remove distracting captions that don’t correspond to the visuals.

BLIP is based on a multimodal mixture of encoder-decoder, a multi-task model that can operate in one of three functionalities to achieve listed objectives:
- Unimodal encoders: It is used to encode pictures and text separately. It comprises of vision transformer as an image encoder and BERT’s text encoder. The unimodal encoder is activated by Image-Text Contrastive Loss (ITC). In contrast to negative image-text pairs, it seeks to align the feature space of the visual and text transformers by encouraging positive image-text pairs to have similar representations.
- The image-grounded text encoder: It has a cross-attention layer inserted between the self-attention layer and the feed-forward network for each transformer block of the text encoder to inject visual information. It is activated by Image-Text Matching Loss (ITM). The ITM challenge asks the model to predict whether an image-text pair is positive (matched) or negative (unmatched) based on their multimodal feature.
- Image-grounded text decoder: It uses causal self-attention layers instead of bi-directional self-attention layers in the text encoder. The decode is activated by Language Modeling Loss (LM), which seeks to create textual descriptions based on the images.
The team also notes that the stochastic decoding method is better compared to beam search for caption generation because of the higher level of diversity in the synthetic captions.
The results suggest that BLIP achieves state-of-the-art on seven vision-language tasks, including image-text retrieval image captioning, visual question answering, visual reasoning, visual dialogue, and zero-shot text-video retrieval zero-shot video question answering.
Paper: https://arxiv.org/abs/2201.12086
Project: https://huggingface.co/spaces/Salesforce/BLIP
Github: https://github.com/salesforce/BLIP
References:
- https://blog.salesforceairesearch.com/blip-bootstrapping-language-image-pretraining/
Suggested
Credit: Source link
Comments are closed.