Researchers from Tel Aviv Propose Long-Text NLP Benchmark Called SCROLLS

Although lengthier texts contain a significant quantity of natural language in the wild, NLP benchmarks have always primarily focused on short texts, such as sentences and paragraphs. Short text classification has consistently been a driving force behind standard benchmarks like GLUE, WMT, and SQuAD. A considerable amount of natural language is produced in the context of lengthier discourses, such as books, essays, and meeting transcripts, as is widely known. As a result, model structures are required to address the computing constraints associated with processing such long sequences.
Researchers from Tel-Aviv University, Meta AI, IBM Research, and Allen Institute for AI (AI2) introduce Standardized CompaRison Over Long Language Sequences (SCROLLS) to tackle this issue. SCROLLS is a collection of summarization, question-answering, and natural language inference tasks that span a variety of topics, including literature, science, commerce, and entertainment.
The Transformer has recently emerged as the most popular framework for deep-learning NLP models. However, one of its flaws is that the Transformer can only handle inputs up to a specific length, and the model’s memory and computational requirements increase as this length squares. To address these concerns, the fundamental Transformer has been altered from various angles, resulting in minimalist Transformers, Reformer, and Performer. However, the SCROLLS team found that the evaluation tasks and metrics for these different solutions differed widely from system to system, making it hard to compare the models’ capacity to manage long-range text dependencies.
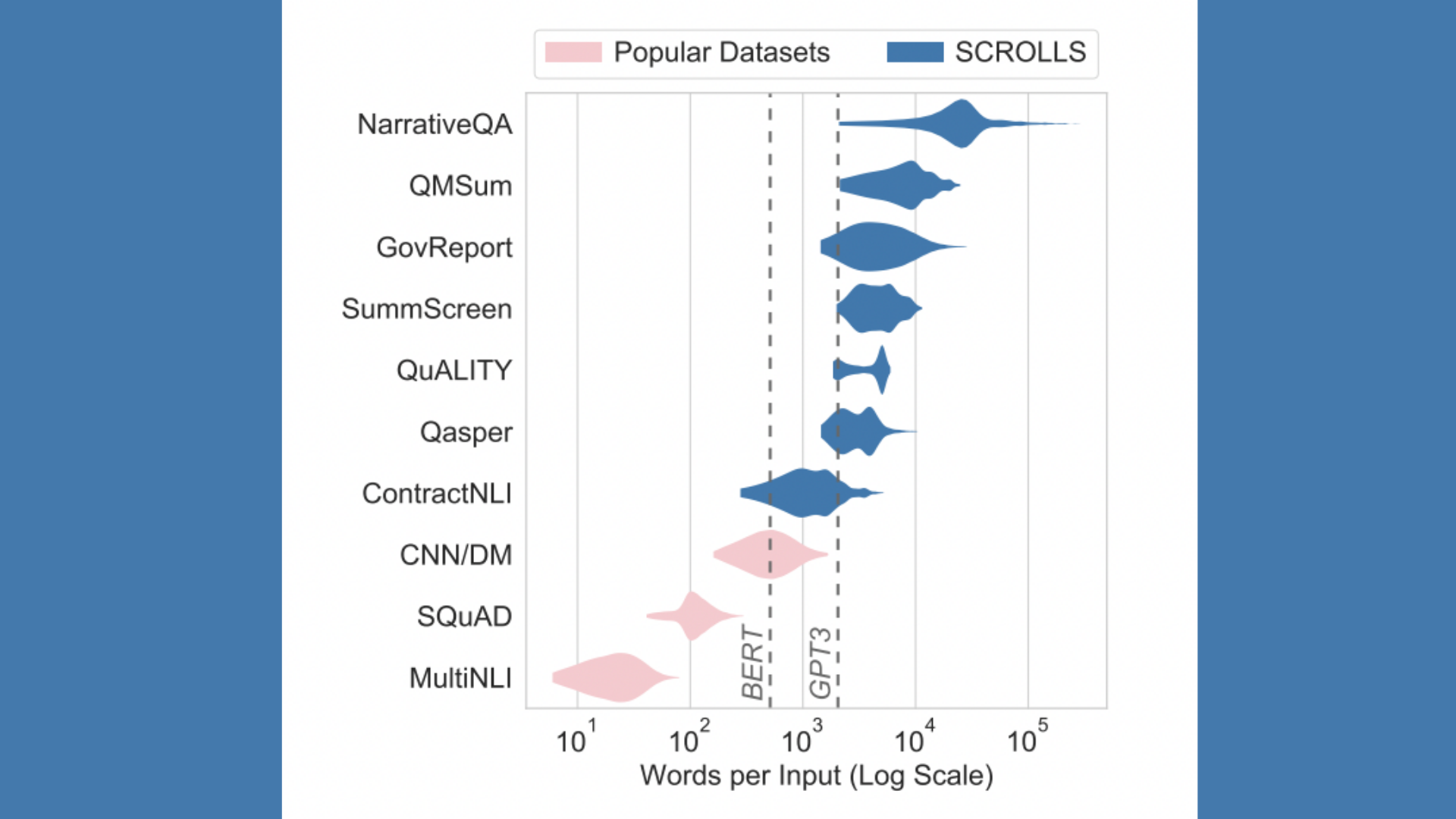
Language modeling perplexity evaluates long-context models, but this metric indicates model sensitivity to local, short-range patterns. The researchers combed through the current literature on long-text tasks. They hand-curated a subset of seven datasets, focusing on those requiring contextualizing and abstracting information from several text parts. The data is subsequently cleaned and translated to a unified text-to-text format, allowing a single model to be evaluated across all datasets. SCROLLS datasets are shown to be significantly longer than commonly used NLP benchmarks.
Hand curated datasets containing naturally long discourses:
- GovReport: An executive summary can be generated from a government report
- SummScreenFD: A recap can be generated from a given TV show transcript.
- QMSum: A query-based summary can be produced given a transcript of an academic, business, or government meeting.
- Qasper: Questions about the content of a scientific publication can be answered.
- NarrativeQA: Questions regarding the subject of a book or movie script can be addressed.
- QuALITY: Given a story or article, multiple-choice questions about the content can be answered.
- Contract NLI: Given a legal contract, it is possible to forecast whether or not a legal statement can be “entailed” from it.
The research team then compared SCROLLS to two other basic Transformer models: BART and Longformer Encoder-Decoder (LED). They also constructed a “naive” SCROLLS heuristic baseline by just recycling the starting of the feed as the output and evaluating the outcome. The researchers noticed a few patterns in the model’s performance. First, both models performed better when given larger “contexts” or input sequences. BART outperformed LED for a given context length, “suggesting that LED may be under-optimized.” By “7 to 10 points,” both models outscored the basic heuristic.
Initial baselines, such as the Longformer Encoder-Decoder, show that SCROLLS has much space for development. It’s past time to move beyond the single-sentence comfort zone and focus more on Long-Text NLP’s under-represented sector.
Paper: https://arxiv.org/pdf/2201.03533.pdf
Details: https://www.scrolls-benchmark.com/
Suggested
Credit: Source link
Comments are closed.