Princeton University Researchers Introduce ‘DataMUX’: A Technique That Enables Deep Neural Networks to Process Multiple Inputs Simultaneously Using a Single Compact Representation

A Princeton University research team proposed Data Multiplexing for Neural Networks in their new study DataMUX: Data Multiplexing for Neural Networks (DataMUX). This new method allows neural networks to analyze several inputs simultaneously and make correct predictions, improving model throughput while requiring minimal additional memory.
Because of its unique capacity to represent complicated real-life issues, deep neural networks (DNNs) are a famous architecture in the machine learning field. Recent research suggests that such networks are grossly overparameterized, necessitating significant and possibly wasteful increases in model size and compute burden to construct modern DNNs.
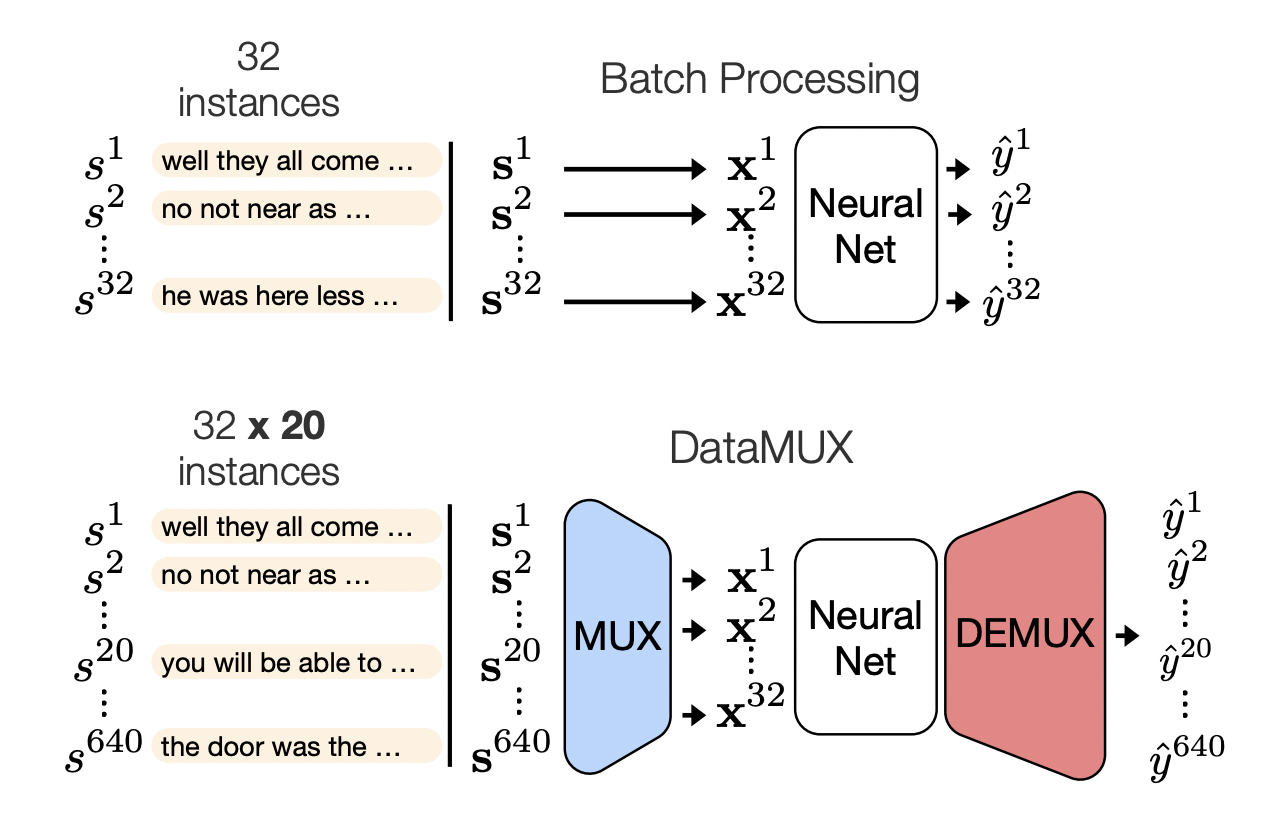
The proposed DataMUX is aimed to compress a mixture of inputs (up to 40) concurrently and effectively over a shared neural network with little overhead during inference. It is made up of three parts:
- A multiplexer module that combines many input instances into a superposed representation
- a neural network backbone and
- a demultiplexing approach for individual prediction.

Before combining them as a single “mixed” representation that is sent into the base network and processed into a “mixed” vector representation, the DataMUX multiplexing layer performs a fixed linear transformation to each input. The demultiplexing layer then turns this vector representation back into a collection of vector representations corresponding to each original input, then utilized to create each instance’s final outputs. Because the multiplexing and demultiplexing layers are end-to-end differentiable, traditional gradient descent methods may be used to train the complete model simultaneously.

The researchers tested the proposed DataMUX on six tasks in phrase classification, named entity identification, and picture classification using a transformer, MLP, and CNN architectures.
Multiplexing causes minor performance losses, according to the findings of the experiments. On the retrieval warm-up work, perfect multiplexing (near 100 percent) may be accomplished for vast numbers of instances, and throughput can be boosted by a factor of ten. According to the findings, the number of attention heads appears to be insensitive to multiplexing. DataMUX can raise throughput on smaller transformers, and performance varies more across various indices as the number of instances grows.
Overall, the research shows that neural networks can be trained to predict multiple input instances simultaneously with minimal additional compute overhead or learned parameters using data multiplexing techniques. The proposed DataMUX setting for multiplex training and inference is offset by dramatically increased system throughput.
Future research in this area could include large-scale pretraining, multi-modal processing, multilingual models, various multiplexing and demultiplexing mechanisms, and a more thorough examination of the architectural, data, and training conditions that enable effective data multiplexing, according to the researchers.
Paper: https://arxiv.org/pdf/2202.09318.pdf
Github: https://github.com/princeton-nlp/datamux
Suggested
Credit: Source link
Comments are closed.