A New Deep Learning Study Investigate and Clarify the Intrinsic Behavior of Transformers in Computer Vision

In recent years, Transformers have overcome classic Convolutional Neural Networks (CNNs) and have rapidly become the state-of-the-art in many vision tasks. This power has always been explained as a consequence of the multi-head self-attention (MSA), and, in particular, its weak inductive bias and ability to capture long-range dependencies. But due to this over-flexibility, Vision Transformers (ViTs) have a tendency to (apparently) overfit training datasets, consequently leading to poor predictive performances in small data regimes. However, most of the concepts related to Transformer have been inferred empirically, and until now there has been no in-depth study of their inherent behavior.
In this paper, the NAVER AI Lab and Yonsei University filled this lack and solve several doubts by investigating Vision Transformer in relation to three fundamental questions: 1) What properties of MSAs do we need to better optimize NNs? 2) Do MSAs behave like Convs (convolutional layers)? If not, how are they different? 3) How can MSAs be harmonized with Convs (convolutional layers)?
- What properties of MSAs do we need to better optimize NNs?
To evaluate MSAs, the authors investigated the properties of the generic ViT family (e.g., the original ViT, PiT and Swin) and compared them with a classical ResNet.
Firstly, they studied the common belief that models with weak inductive biases tend to overfit the training dataset. This was done for several networks by calculating the error on the test dataset and the negative log-likelihood (NNL) on the training dataset. As shown in the figure below (left), models with MSA and thus weak inductive bias, such as ViT, do not overfit the training dataset (the error and NNL values are very close to each other). This was also confirmed, again in the figure below (right), for small datasets, where it is possible to see that both error and NLL decrease (comprehensibly) with fewer images, but still do not overfit.
All of this suggested a very important concept: the poor performance of ViT with small datasets does not derive from overfitting.

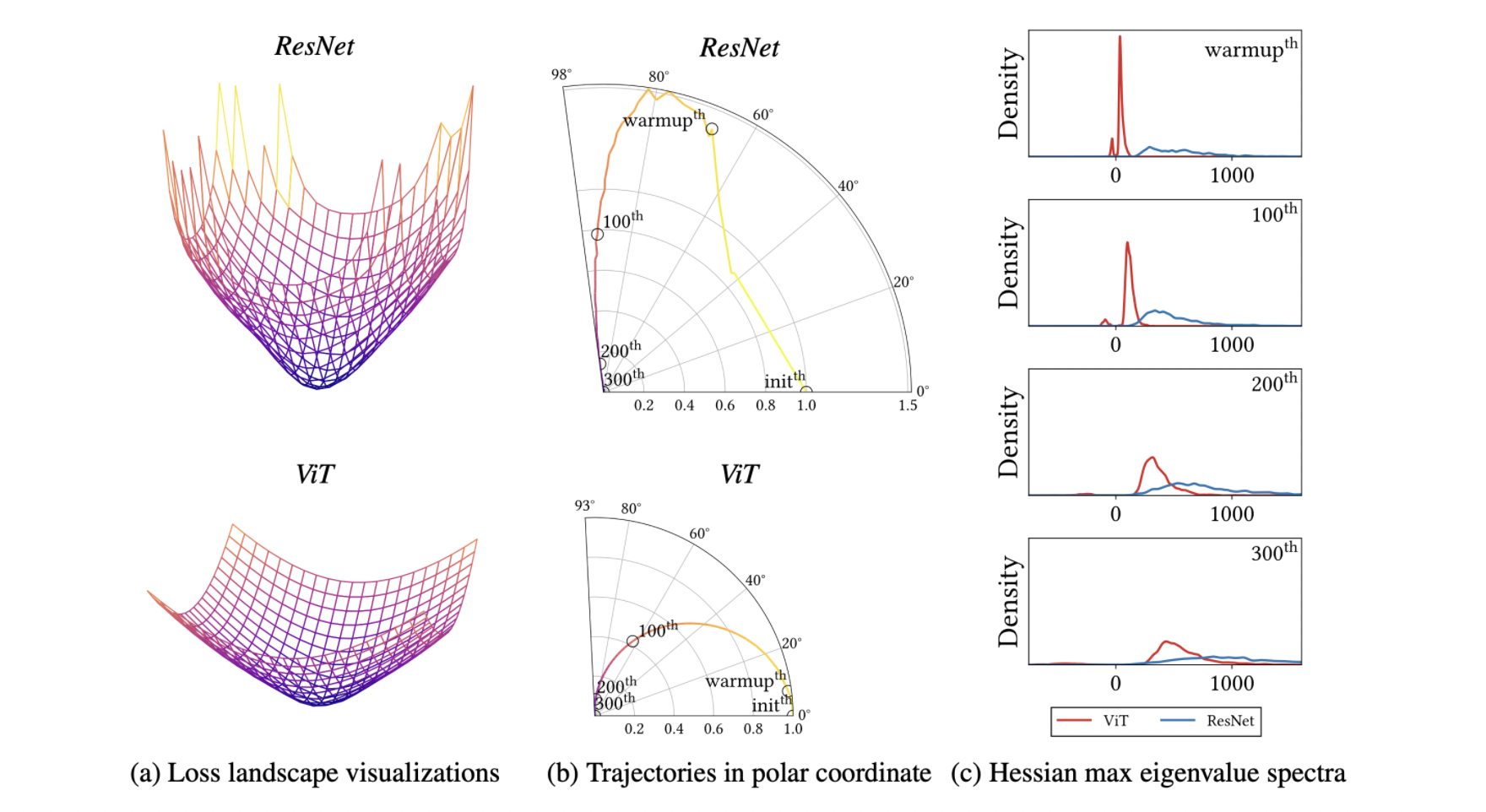
The next step was then to figure out what the actual reason might be. The fascinating discovery was that the weak inductive bias leads to a non-convex loss function which has been demonstrated to disrupt training, while the one of ResNet is strongly convex (figure below).

Furthermore, the density of Hessian eigenvalues (figure below), showed that ViT has a large number of negative eigenvalues (a characteristic that disturbs neural network optimization) while ResNet does not, with a small dataset (dashed line) the magnitude of these eigenvalues is even higher, suggesting that large dataset suppress negative eigenvalues and help ViT in convexifying the loss. On the other hand, a positive feature of ViT is that the magnitude of positive eigenvalues is lower than the one of ResNet, and it is a well-known property that large eigenvalues impede training.
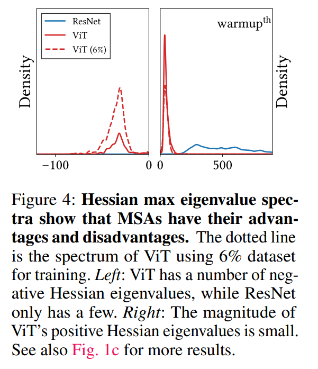
In summary, when MSAs leverage large dataset, the negative eigenvalues disappears and only the benefits of small positive eigenvalues remain.
In addition, for small datasets, this problem can be solved by loss landscape smoothing methods such as Global Average Pooling (GAP), as was demonstrated in the image below, which shows that GAP suppressed the negative eigenvalues.

- Do MSAs behave like Convs?
First, a Fourier analysis allowed the authors to understand that MSAs reduce high-frequency signals (acting as low-pass filters) while Convs (convolutional layers) on the contrary amplify them (acting as high-pass filters). From this, it can be inferred that low-frequency signals and high-frequency signals are informative to MSAs and Convs (convolutional layers), respectively, also shown in the figure below. Also, as low-frequency signals correspond to the shape and high-frequency signals to the texture of images, the results suggest that MSAs are shape-biased, whereas Convs (convolutional layers) are texture-biased.

Another important aspect is that MSAs aggregate feature maps by reducing variance, while Convs (convolutional layers) do not. It has been noticed that ResNet’s variance has its peak at the end of each stage. Therefore, a first idea on how to harmonize MSA with Convs (convolutional layers) would be to insert MSAs blocks here.
3) How can MSAs be harmonized with Convs (convolutional layers)?
Based on these findings, the authors proposed an alternating pattern based on the complementarity between Convs (convolutional layers) and MSAs. The design pattern naturally derives from the structure of canonical Transformer, but with an MSA module at the end of each stage, and not at the end of the model as the popular belief. To build the configuration, the authors started with an all-Convs (convolutional layers) model and gradually substituted (starting from the end) Convs (convolutional layers) with MSAs until the performances stopped improving. The resulting model was called AlterNet. A comparison between the pattern of ResNet, a canonical Transformer, and AlterNet is shown in the figure below.

Conclusion
Surprisingly, AlterNet, with its alternating pattern of Convs (convolutional layers) and MSAs, outperformed CNNs not only on large datasets but also on small datasets, such as CIFAR. This contrasts with canonical ViTs, models that perform poorly on a small amount of data. It implies two important facts: 1) that MSAs are generalized spatial smoothings that complement Convs (convolutional layers), not simply generalized Convs (convolutional layers) and 2) that MSAs help NNs learn strong representations by ensembling feature map points and flattening the loss landscape.
Paper: https://arxiv.org/pdf/2202.06709v1.pdf
Github: https://github.com/xxxnell/how-do-vits-work
Suggested
Credit: Source link
Comments are closed.