Google and Cornell Researchers Introduce FLASH: A Machine Learning Model That can Achieve High Transformer Quality in Linear Time

The introduction of attention-based transformer architectures has permitted numerous language and vision tasks improvements. However, their use is limited to small context sizes due to their quadratic complexity over the input length. Many scientists have been working on strategies to develop more efficient attention mechanisms and decrease complexity to linear to speedup transformers. So far, these techniques have many shortcomings, such as poor quality, large overhead in practice, or ineffective auto-regressive training.
The Google Brain and Cornell University team has proposed FLASH (Fast Linear Attention with a Single Head) can achieve quality (perplexity) comparable to fully-augmented transformers to deal with these issues. This first model family can achieve quality (perplexity) comparable to fully-augmented transformers while being significantly faster to train than existing efficient transformer variants. This work has established it as a viable method for addressing the drawbacks of existing efficient transformer variants.
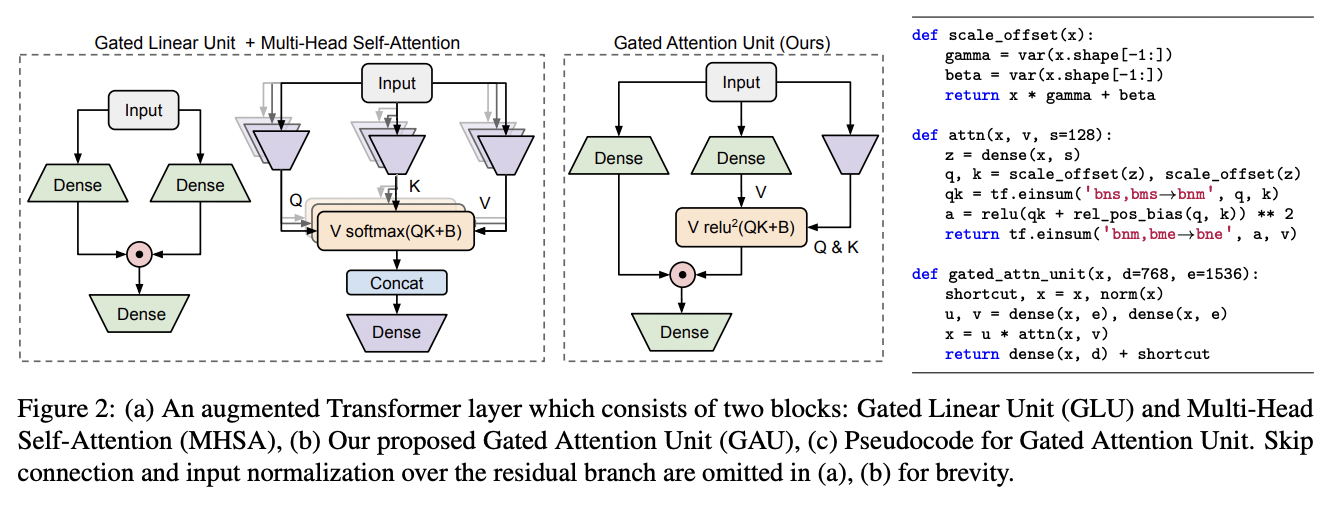
They offer a new layer design that can make a more effective approximation. The used Gated Attention Unit (GAU) mechanism with layers is less expensive than transformer layers, and attributes are less dependent on attention accuracy. The assessment result shows that GAU with a modest single-head, softmax-free attention performs better than transformers. Despite the fact that GAU still has a quadratic complexity problem with transformers, it reduces the significance of attention, allowing the team to make approximations with minimal quality loss later.
To approximate quadratic attention in GAU, an efficient token-grouping algorithm is used, resulting in a layer variation with linear complexity over the context size. With only a few lines of code change, the accelerator-efficient implementation obtained from this method can achieve linear scalability in practice.
The team used the benefits of partial attention and linear attention to suggest a unique mixed-chunk attention mechanism. To construct part of the pre-gating state, local quadratic attention is applied independently to each chunk. The global linear attention mechanism is then used to record long-range interactions between chunks. FLASH achieves its transformer-level quality in linear time on lengthy sequences thanks to a combination of the accelerator-efficient approximation technique and the mixed chunk attention mechanism.
The researchers tested their FLASH models on extended sequences against two popular linear-complexity transformer variants: Performer and Combiner.
FLASH demonstrated training speedups of up to 4.9 on Wiki-40B and 12.1 on PG-19 for auto-regressive language modeling, and 4.8 on C4 for masked language modeling, in the assessments. FLASH also outperformed the full-attention transformer variations in terms of confusion, demonstrating the usefulness of its unique, efficient attention design.
Paper: https://arxiv.org/pdf/2202.10447.pdf
Suggested
Credit: Source link
Comments are closed.