CMU Researchers Open Source ‘PolyCoder’: A Machine Learning-Based Code Generator With 2.7B Parameters

Language models (LMs) are commonly used in natural language literature to assign probabilities to sequences of tokens. LMs have recently demonstrated outstanding performance in modeling source code written in programming languages. These models are particularly good at jobs like code completion and code generation from natural language descriptions. For AI-based programming support, the current state-of-the-art big language models for code have demonstrated tremendous improvement. One of the largest of these models, Codex, has been implemented as an in-IDE developer assistant that automatically writes code based on the user’s context in the real-world production tool GitHub Copilot.
Despite the huge success of massive language models of code, the most powerful models aren’t available to the public. This limits research in this sector for low-resource firms and prevents the use of these models outside of well-resourced companies. Codex, for example, allows non-free access to the model’s output via black-box API calls but not to the model’s weights or training data. Researchers are unable to fine-tune and adopt this approach to domains and activities other than code completion as a result of this. The absence of access to the model’s internals also limits researchers from looking into other important characteristics of these models, such as interpretability, model distillation for more efficient deployment, and introducing extra components like retrieval.
GPTNeo, GPT-J, and GPT-NeoX are three publicly available pre-trained language models that range in size from medium to big. Despite being trained on a wide variety of content, including news articles, internet forums, and a small number of (GitHub) software repositories, these language models are capable of producing source code with decent speed. There are also a few open-source language models that are purely trained on source code. CodeParrot, for instance, was trained on 180 GB of Python code.

The influence of various modeling and training design decisions is unclear due to the variety of model sizes and training strategies used in these models and the absence of comparisons between them. The actual data set on which Codex and other private models were trained, for example, is unknown. Some public models were trained on a combination of natural language and code in various programming languages, while others (e.g., CodeParrot) were trained only on code in one programming language. Because different programming languages share comparable keywords and features, multilingual models may enable superior generalization, as demonstrated by the effectiveness of multilingual models for real language and code. This could indicate that multilingual LMs can generalize across languages, outperform monolingual models, and be effective for modeling low-resource programming languages, albeit this has yet to be empirically proven.
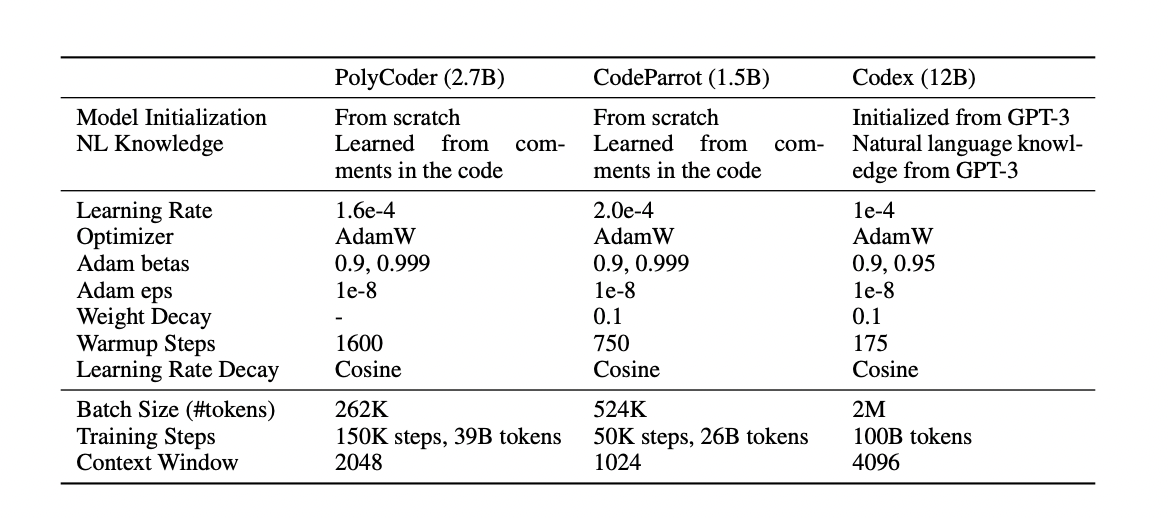
Researchers from Carnegie Mellon University recently published a paper that compares existing code models – Codex, GPT-J, GPT-Neo, GPT-NeoX, and CodeParrot – across programming languages. By comparing and contrasting various models, they want to offer more light on the landscape of code modeling design decisions, as well as fill in a major gap: no big open-source language model has been trained purely on code from several programming languages. Under the umbrella name “PolyCoder,” the team proposes three such models with parameters ranging from 160M to 2.7B.
First, the team compares and contrasts PolyCoder, open-source models, and Codex in terms of training and evaluation settings. Second, the team investigates how models of various sizes and training steps scale, as well as how varying temperatures affect generation quality, using the HumanEval benchmark. Finally, because HumanEval only assesses natural language to Python synthesis, they create an unknown evaluation dataset in each of the 12 languages to assess the perplexity of various models.
Researchers discovered that, despite its ostensible specialization in Python, Codex performs admirably in other programming languages, outperforming GPT-J and GPT-NeoX, which were trained on the Pile. Nonetheless, the PolyCoder model achieves a lower perplexity in the C programming language than all of these models, including Codex.
In the C programming language, PolyCoder outperforms Codex and all other models. PolyCoder outperforms the similarly sized GPT-Neo 2.7B in C, JavaScript, Rust, Scala, and TypeScript when comparing solely open-source models. All other open-source models, including Polycoder, are much poorer (greater perplexity) than Codex in the 11 languages other than C. PolyCoder is trained on an unbalanced blend of languages, with C++ and C being related and the two most prevalent in the overall training corpus, according to researchers. As a result of the bigger total volume (due to lengthier files), PolyCoder considers C to be the “preferred” language. Because of the intricacy of the C++ language and Codex’s substantially larger context window size (4096 vs. PolyCoder’s 2048), or because Codex is likely trained on more C++ training data, PolyCoder does not outperform Codex in C++.
Conclusion
Researchers conduct a comprehensive examination of massive language models for code in this work. Larger models and more training time benefit performance in general. They also claim that GPT-superior Neo’s performance in some languages suggests that training on natural language text and code can help with code modeling. PolyCoder, a massive open-source language model for code that was trained only on code in 12 distinct programming languages, was released to aid future study in the field. PolyCoder produces lower perplexity in the C programming language than all other models, including Codex.
Paper: https://arxiv.org/pdf/2202.13169.pdf
Github: https://github.com/vhellendoorn/code-lms
Suggested
Credit: Source link
Comments are closed.