In the Latest Google AI’s Research, The Team Explains How They Reduced The Size of The High-Performing CAP12 Model By 6x-100x While Maintaining 90-96% of The Performance in TRILLsson Models

In recent years, there has been significant progress in lexical tasks like automatic speech recognition (ASR). Yet machine systems struggle to understand non-linguistic features such as tone, mood, or whether a speaker is wearing a mask, among other things. One of the most challenging difficulties in machine hearing is figuring out how to understand these elements. Furthermore, cutting-edge results are frequently derived from ultra-large models trained on private data, making them impractical to execute on mobile devices or to make publicly available.
CAP12, the 12th layer of a 600M parameter model trained on the YT-U training dataset using self-supervision, in “Universal Paralinguistic Speech Representations Using Self-Supervised Conformers,” was published at ICASSP 2022.
Even though earlier results are generally task-specific, the CAP12 model beats nearly all previous results in the paralinguistic benchmark, sometimes by substantial margins. It is compact, performant, and publicly available. Knowledge distillation on correctly sized audio bits and several architecture types were used to train smaller, quicker networks that can run on mobile devices to build TRILLsson.
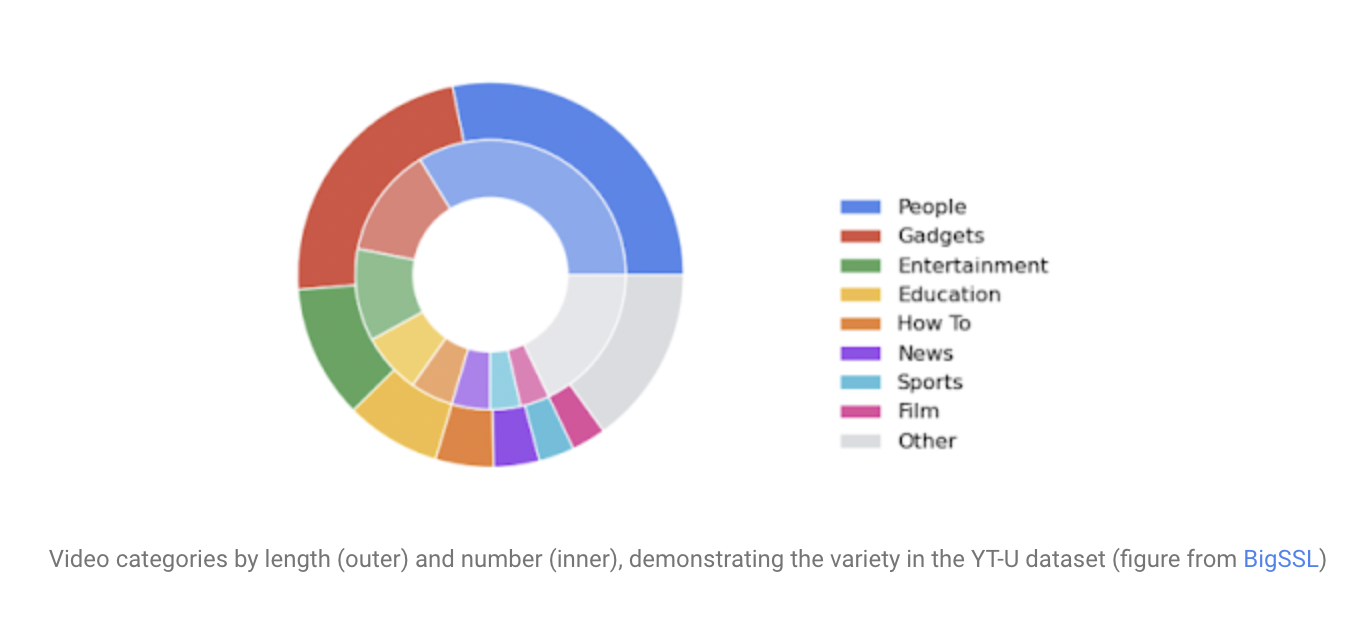
The ultra-large, self-supervised CAP12 model is trained using the YT-U training dataset. The YT-U dataset is a 900M+ hour audio collection with various topics, background settings, and speaker acoustic attributes. A Wav2Vec 2.0 self-supervised training paradigm was integrated with ultra-large Conformer models to solve challenges utilizing raw data without labels. Scaled up the use of YT-U to some of the largest model sizes ever trained, including 600M, 1B, and 8B parameters, because self-training doesn’t require labels.

Conformer Applied to Paralinguistics is the name given to the 600M parameter Conformer model without close attention (CAP).
Out of all intermediate terms of six ultra-large models, layer 12 (CAP12) outperforms prior representations by a wide margin. NOn-Semantic Speech (NOSS) benchmark was used to assess the quality of the roughly 300 candidate paralinguistic speech representations. The NOSS benchmark is a collection of well-studied paralinguistic speech tasks such as speech emotion recognition, language identification, and speaker identification. These tasks concentrate on paralinguistic components of speech, which necessitate evaluating speech features for 1 second or longer, rather than lexical features, which require 100ms or less.
A mask-wearing task from Interspeech 2020, a false speech detection task from ASVSpoof 2019, was added, and an extra speech emotion recognition work to the benchmark (IEMOCAP). CAP12 is even more valuable than prior representations and can diversify the tasks. On five paralinguistic jobs, simple linear models on time-averaged CAP12 representations beat complicated, task-specific models. This is unexpected because comparable models frequently use additional modalities (visual and voice or text and speech). Furthermore, CAP12 does particularly well in activities involving emotion identification.
Except for one supervised network embedding on the dysarthria detection task, CAP12 embeddings beat all other embeddings on all other jobs. Knowledge distillation was used to train simpler, quicker, and mobile-friendly architectures. EfficientNet, Audio Spectrogram Transformer (AST), and ResNet were all used in our research. These models come in various shapes and sizes, and they can handle both fixed-length and arbitrary-length inputs. EfficientNet results from a neural architecture search over vision models to uncover model structures that are both performant and efficient. Transformers with audio inputs are known as AST models. ResNet is a standard design that has demonstrated exemplary performance in various models.
Despite being 1 percent -15 percent of CAP12 and trained with only 6% of the data, models introduced performed 90-96 percent. Surprisingly, different forms of architecture functioned better at various scales. ResNet models outperformed EfficientNet models at the low end, and AST models outperformed AST models.
Two techniques for producing student targets are available: global and local matching. Global matching creates distillation targets by building CAP12 embeddings for an entire audio clip and then asking students to match the target using only a tiny portion of audio (e.g., 2 seconds). Local matching necessitates that the student network reaches the average CAP12 embedding just over the area of the audio that is visible to the student. Local matching was preferred over the global.

The distribution of paralinguistic data is bimodal in an unexpected way. Intermediate representations gradually rise in paralinguistic information, decrease, and increase again. Finally, lose this information towards the output layer for the CAP model that operates on 500 ms input segments and two of the full-input Conformer models. Surprisingly, this trend can also be found in the intermediate representations of networks trained on retinal pictures.
Smaller, faster paralinguistic speech models will open up new speech detection possibilities, text-to-speech production, and user intent interpretation. Correspondingly, smaller models will be easier to comprehend, allowing researchers to better grasp which components of speech are crucial for paralinguistics.
Paper: https://arxiv.org/pdf/2110.04621.pdf
Reference: https://ai.googleblog.com/2022/03/trillsson-small-universal-speech.html
Suggested
Credit: Source link
Comments are closed.