MIT Researchers Suggest That a Certain Type of Robust Computer-Vision Model Perceives Visual Representations Similarly To The Way Humans Do Using Peripheral Vision

Understanding the mechanisms that give rise to adversarial stimuli demonstrates a remarkable perceptual difference between man and machine. It is, therefore, one of the most critical challenges in modern computer vision.
While it may appear that escaping adversarial stimuli is theoretically impossible, it is vital to focus on understanding the physiologically realistic processes of the solutions that offer some level of adversarial robustness associated with the human mistake.
When used to synthesize feature-matching images, texture-based summary statistic models of the human periphery have been proven to explain crucial phenomena such as crowding and performance on visual search tasks. These analysis-by-synthesis models have also explained mid-level visual computation in humans and primates using perceptual discrimination tasks on images.
Summary statistic models can explain peripheral computation in humans. However, they can’t explain foveal computation or core object identification because it requires different representational strategies. Since computers lack a peripheral, practically all object identification systems in computer vision have focused on modeling foveal vision using deep learning. Yet, despite their broad success in various tasks, they are subject to adversarial perturbations.
Previous work on summary statistic models of peripheral computation showed their potential resemblance to inverted representations of adversarially trained networks. Inspired by this, the researchers from MIT investigated if these two seemingly different occurrences from separate areas had any parallels.
Although machines lack peripheral computation, they are still vulnerable to adversarial attacks that humans are not. According to the researchers, object representation emerging from human peripheral processing is important for robust high-level vision in perceptual systems.
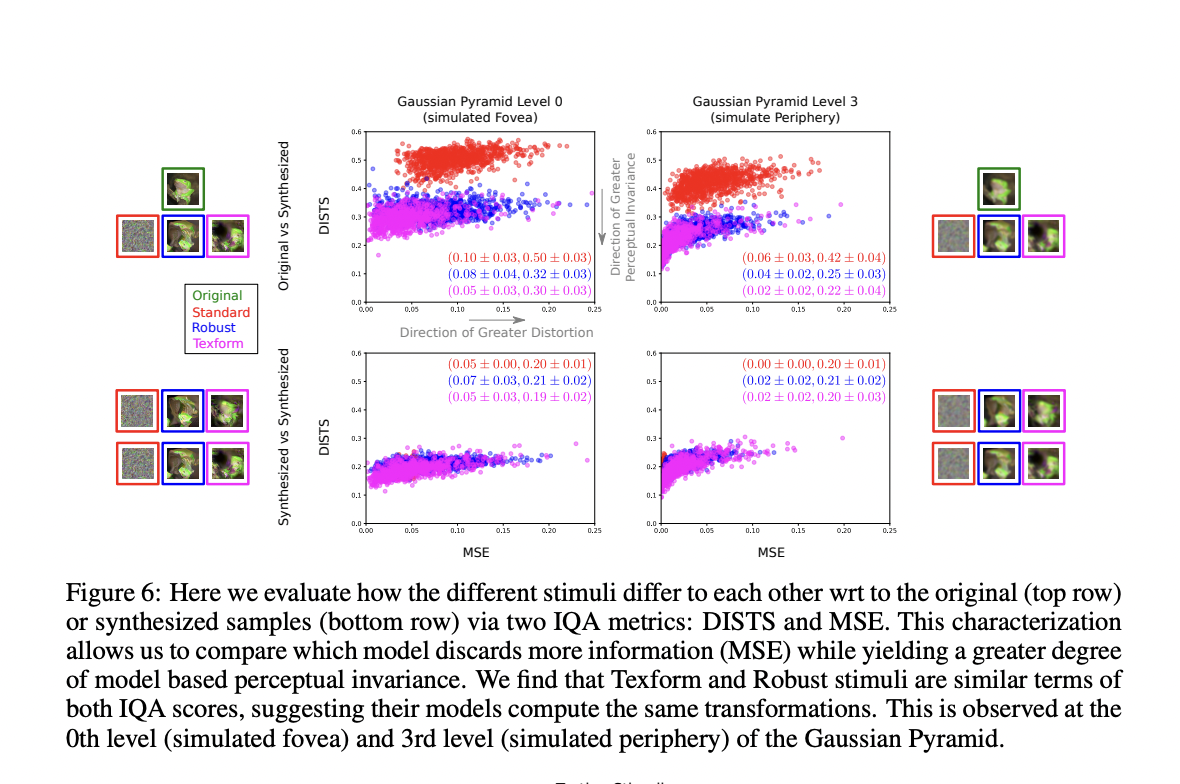
Therefore, they aimed to compare an adversarially trained neural network model to current peripheral/mid-level visual processing models – and, eventually, to human observers as the objective ground truth. However, calculating such perceptual parameterizations is computationally intractable. It is possible to assess how well the adversarially robust CNN model approximates the types of computations present in human peripheral vision. For this, a set of rigorous psychophysical experiments involving synthesized stimuli is needed.
The team conducted a series of tests to compare the rates of human perceptual discriminability as a function of retinal eccentricity between synthesized stimuli from an adversarially trained network and synthesized stimuli from mid-level/peripheral processing models. They hypothesized that if the decay rates of perceptual discriminability across different stimuli are similar, then the transformations acquired in an adversarially trained network are related to the transformations performed by peripheral computation models. Hence, they are also related to the human visual system.

Although adversarially resilient representations have been proven to be more human-perceptually aligned, they nevertheless look significantly different from the original reference image when placed in the foveal region. That can appear quite different than how information is processed in the fovea. However, empirical studies reveal that the human visual periphery represents input in a texture-like jumbled way.
For both the Oddity and 2AFC Matching tasks, the team discovered that stimuli synthesized from an adversarially trained (and thus robust) network are metameric to the original stimuli at the further periphery (just beyond 30 deg). However, when comparing the adversarially trained network’s robust stimuli with classical models of peripheral computation and V2 encoding (mid-level vision) used to render the texform stimuli, they discovered a surprisingly similar pattern of results in perceptual discrimination interacts with retinal eccentricity. Furthermore, for stimuli produced from non-adversarially trained (standard) networks, this form of eccentricity-driven interaction does not occur.
They demonstrate that adversarially trained networks encode a similar set of visual periphery modifications. The generalization and adversarial robustness were observed to be similar when standard training was done on robust images and when adversarial training was conducted on standard images. When humans learn to recognize objects, they not only focus on the target picture but also glance around. Eventually, they planned to learn where to make a saccade given candidate item peripheral templates, thereby learning certain invariances when the object is put in both the fovea and the periphery.
This could imply that spatially uniform high-resolution processing is redundant and sub-optimal. In other words, the visual representation computed is independent of the point of fixation – as seen in adversarially vulnerable CNNs that are translation invariant and have no foveated/spatially-adaptive computation. Surprisingly, the spatially adaptive human visual system may lead to a more robust visual input encoding process. This is because observers can encode a dispersion rather than a point as their center of sight moves.
Paper: https://openreview.net/pdf?id=yeP_zx9vqNm
Reference: https://news.mit.edu/2022/machine-peripheral-vision-0302
Suggested
Credit: Source link
Comments are closed.