In A Latest Machine Learning Research, NVIDIA Researchers Propose A Novel Critically-Damped Langevin Diffusion (CLD) For Score-Based Generative Modeling

A promising family of generative models has emerged: score-based generative models (SGMs) and denoising diffusion probabilistic models. SGMs have applications in image, voice, and music synthesis, image editing, super-resolution, image-to-image translation, and 3D shape generation because they provide high-quality synthesis and sample variety without requiring adversarial aims.
SGMs use a diffusion process to progressively introduce noise to the data, changing a complicated data distribution into a tractable prior distribution for analysis. The modified data’s score function—the gradient of the log probability density—is then learned using a neural network. To synthesize new samples, the learned scores can be used to solve a stochastic differential equation (SDE). Inverting the forward diffusion corresponds to an iterative denoising process.
The forward diffusion process has been proven to be the sole determinant of the scoring function that the neural network must learn. As a result, the difficulty of the learning problem is solely dependent on the diffusion, aside from the data itself. As a result, the diffusion process is a critical component of SGMs that must be explored in order to improve SGMs in terms of synthesis quality or sampling speed, for example.
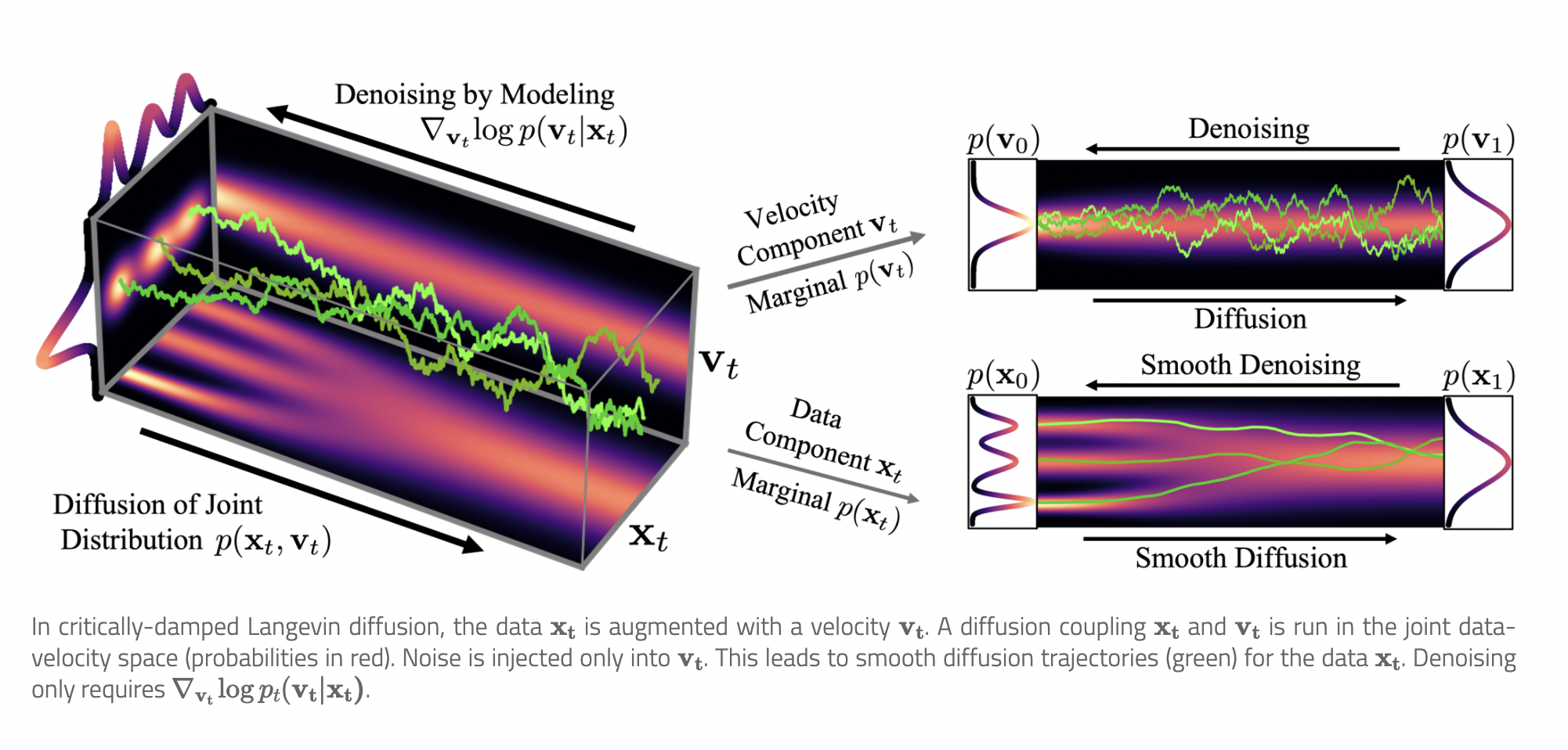
Nvidia researchers present the critically-damped Langevin diffusion, a revolutionary forward diffusion method inspired by statistical mechanics (CLD). In CLD, the data variable (time t along the diffusion) is supplemented with a “velocity” variable, and a diffusion process is performed in the combined data-velocity space. As in Hamiltonian dynamics, data and velocity are connected, and noise is injected only into the velocity variable.
The Hamiltonian component, as in Hamiltonian Monte Carlo, aids in traversing the joint data-velocity space effectively and converting the data distribution into the prior distribution more smoothly. Researchers establish the score matching objective for CLD and show that the neural network is charged with learning the score of the conditional distribution of velocity given data, which is arguably easier than learning the score of diffused data directly. The team also creates a novel SDE integrator adapted to CLD’s reverse-time synthesis SDE using molecular dynamics techniques.
The team examines the trade-off between sampling speed and synthesis quality for CLD-SGMs, as well as the performance of SSCS under various NFE budgets. They compare the results to previous studies and employ EM to solve the generative SDE for their VPSDE model and PC (reverse diffusion + Langevin sampler) for their VESDE model. They also compare generative SDE sampling with a higher-order adaptive step size solver to the GGF solver and probability flow ODE sampling with a higher-order adaptive step size solver. It’s also compared to LSGM (using our LSGM-100M), which uses probability flow sampling as well. The CLD-SGM outperforms all baselines, with the exception of VESDE with 2,000 NFE, for both adaptive and fixed-step size techniques.
There are a few points that stick out: As expected, SSCS outperforms EM for CLD when NFE resources are low. When the SDE is finely discretized (high NFE), the two methods perform equally, which is to be expected because the mistakes of both methods become minimal. In the adaptive solver configuration, the model outperforms GGF, which is optimized for image synthesis, utilizing a simpler ODE solver. In terms of FID, the CLD-SGM outperforms the LSGM-100M model. However, it’s worth mentioning that LSGM was created largely for speedier synthesis, which it accomplishes by modeling a smooth distribution in latent space rather than the more complex data distribution directly. This shows that merging LSGM with CLD and training a CLD-based LSGM could be beneficial, combining the merits of the two techniques.
Conclusions
Critically-damped Langevin diffusion, a unique diffusion mechanism for training SGMs, was introduced by Nvidia researchers. In comparison to prior SGMs, CLD diffuses the data in a smoother, easier-to-denoise manner, resulting in smoother neural network-parametrized score functions, faster synthesis, and increased expressivity. For similar-capacity models and sampling compute budgets, the studies reveal that CLD beats earlier SGMs in image synthesis, while the innovative SSCS outperforms EM in CLD-based SGMs. In terms of technology, in addition to proposing CLD, researchers derive HSM, a version of denoising score matching appropriate for CLD, and a customized SDE integrator for CLD. This work, which was inspired by statistical mechanics approaches, provides fresh insights into SGMs and suggests interesting research options for the future.
Paper: https://arxiv.org/pdf/2112.07068.pdf
Project: https://nv-tlabs.github.io/CLD-SGM/
Code: https://github.com/nv-tlabs/CLD-SGM
Suggested
Credit: Source link
Comments are closed.