This Latest Paper From Twitter and Oxford Research Shows That Feature Propagation is an Efficient and Scalable Approach for Handling Missing Features in Graph Machine Learning Applications
This research summary article is based on the paper 'ON THE UNREASONABLE EFFECTIVENESS OF FEATURE PROPAGATION IN LEARNING ON GRAPHS WITH MISSING NODE FEATURES' and Twitter's Engineering team's article 'Graph machine learning with missing node features'.
Graph Neural Networks (GNNs) have proved to be effective in a wide range of issues and fields. GNNs commonly use a message-passing mechanism, in which nodes communicate feature representations (“messages”) to their neighbors at each layer. Each node’s feature representation is initialized to its original features, and it is updated by aggregating incoming messages from neighbors on a regular basis. GNNs are distinguished from other purely topological learning systems such as random walks or label propagation by their ability to mix topological and feature information, which is arguably what contributes to their success.
Typically, GNN models assume a fully observed feature matrix, with rows representing nodes and columns representing channels. In real-world circumstances, however, each trait is frequently only observable for a subset of nodes. Demographic information, for example, maybe exposed to only a small percentage of social network users, while content features are typically only available to the most active users.
It’s possible that not all products in a co-purchase network have a complete description. As people become more conscious of the importance of digital privacy, data is becoming more accessible only with the explicit consent of the user. In all of the examples above, the feature matrix has missing values, making it impossible to apply most existing GNN models directly.
While traditional imputation methods can be used to fill the feature matrix’s missing values, they are blind to the underlying graph structure. Graph Signal Processing, a topic that aims to expand conventional Fourier analysis to graphs, provides a number of approaches for reassembling signals on graphs. However, they are infeasible for real applications since they do not scale beyond graphs with a few thousand nodes. To adapt GNNs to the issue of missing features, SAT, GCNMF, and PaGNN have been proposed more recently.
They are not, however, examined at large rates of missing features (> 90%), which occur in many real-world circumstances and where they are found to suffer. Furthermore, they can’t handle graphs with more than a few hundred thousand nodes. PaGNN is currently the most advanced approach for node classification with missing characteristics.

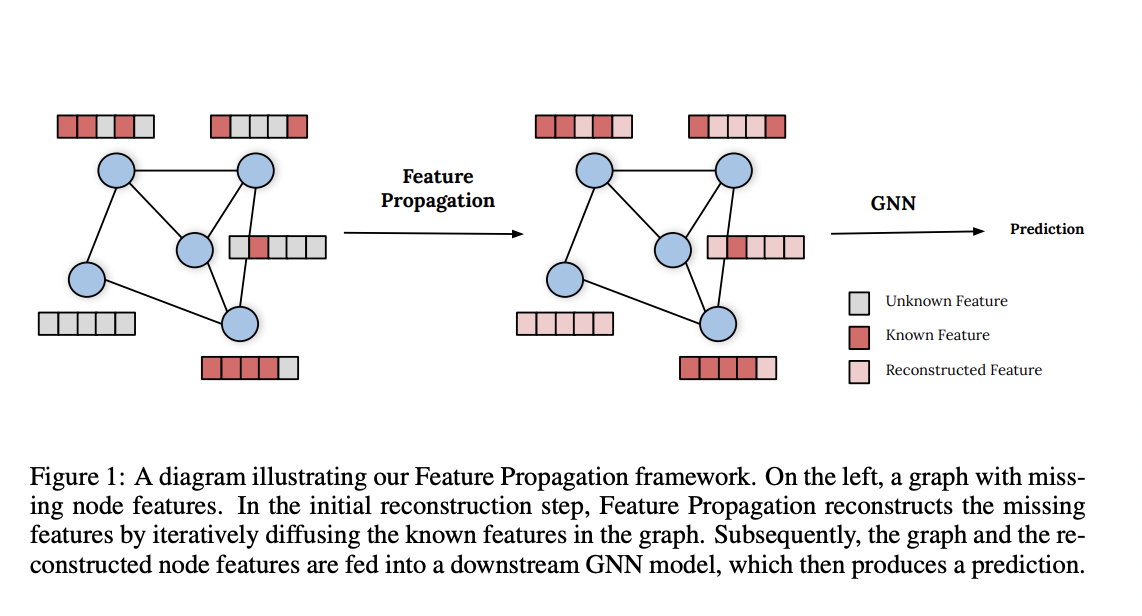
Twitter researchers have proposed a universal method for dealing with missing node features in graph machine learning applications. An initial diffusion-based feature reconstruction stage is followed by a downstream GNN in the framework. The reconstruction process uses Dirichlet energy minimization, which results in a graph with a diffusion-type differential equation. When this differential equation is discretized, a relatively simple, rapid, and scalable iterative procedure known as Feature Propagation emerges (FP).
On six standard node classification benchmarks, FP beats state-of-the-art approaches and offers the following benefits::
• Theoretically Motivated: FP appears naturally as a gradient flow that minimizes the Dirichlet energy and may be viewed as a graph diffusion equation with known features acting as boundary constraints.
• Robust to high rates of missing features: Surprisingly large rates of missing features can be tolerated by FP. When up to 99 percent of the characteristics are absent, the team notices a 4 percent relative accuracy loss in the studies. GCNMF and PaGNN, on the other hand, have experienced average drops of 53.33 percent and 21.25 percent, respectively.
• Generic: GCNMF and PaGNN, on the other hand, are particular GCN-type models that can be merged with any GNN model to perform the downstream task.
• Fast and Scalable: On a single GPU, the reconstruction step of FP on OGBNProducts (a graph with 2.5 million nodes and 123 million edges) takes about 10 seconds. On this dataset, GCNMF and PaGNN run out of memory.
The task of node classification is evaluated using many benchmark datasets, including Cora, Citeseer, PubMed, Amazon-Computers, Amazon-Photo, and OGBN-Arxiv. They also put the method to the test on OGBNProducts to see how scalable it is.
In every circumstance, FP matches or surpasses other approaches. The simple Neighbor Mean baseline regularly outperforms both GCNMF and PaGNN. This isn’t entirely surprising, given that Neighbor Mean is a first-order approximation of Feature Propagation, with only one stage of propagation (and with a slightly different normalization of the diffusion operator). Surprisingly, most approaches work exceptionally well up to 50% missing features, implying that node features are redundant in general, as replacing half of them with zeroa (zero baselines) has no influence on performance.
Conclusion
Twitter researchers have developed a new method for dealing with missing node information in graph-learning assignments. The Feature Propagation model can be derived directly from energy minimization and implemented as a fast iterative technique in which the features are multiplied by a diffusion matrix before the known features are reset to their original value. Experiments on a variety of datasets reveal that even when 99 percent of the features are absent, FP can recreate them in a form that is suitable for the downstream job. On popular benchmarks, FP surpasses recently proposed approaches by a large margin while also being extremely scalable.
Paper: https://arxiv.org/pdf/2111.12128.pdf
Source: https://blog.twitter.com/engineering/en_us/topics/insights/2022/graph-machine-learning-with-missing-node-features
Suggested
Credit: Source link
Comments are closed.