The Token-Dropping Approach Used By ML Researchers From Google and NYU Reduces BERT Pretraining Time And Cost By 25%
This research summary article is based on the paper 'Token Dropping for Efficient BERT Pretraining'. Please don't forget to join our ML Subreddit
The Pretraining of BERT-type large language models, which may scale up to billions of parameters, is essential to achieving best-in-class performance on various natural language processing (NLP) applications. However, the pretraining procedure is costly, and it has become a hurdle for the industrial deployment of big language models.
In a research paper, researchers from Google, New York University, and the University of Maryland recommend a simple but effective “token dropping” method that drastically reduces the pretraining cost of transformer models like BERT while maintaining downstream fine-tuning performance.
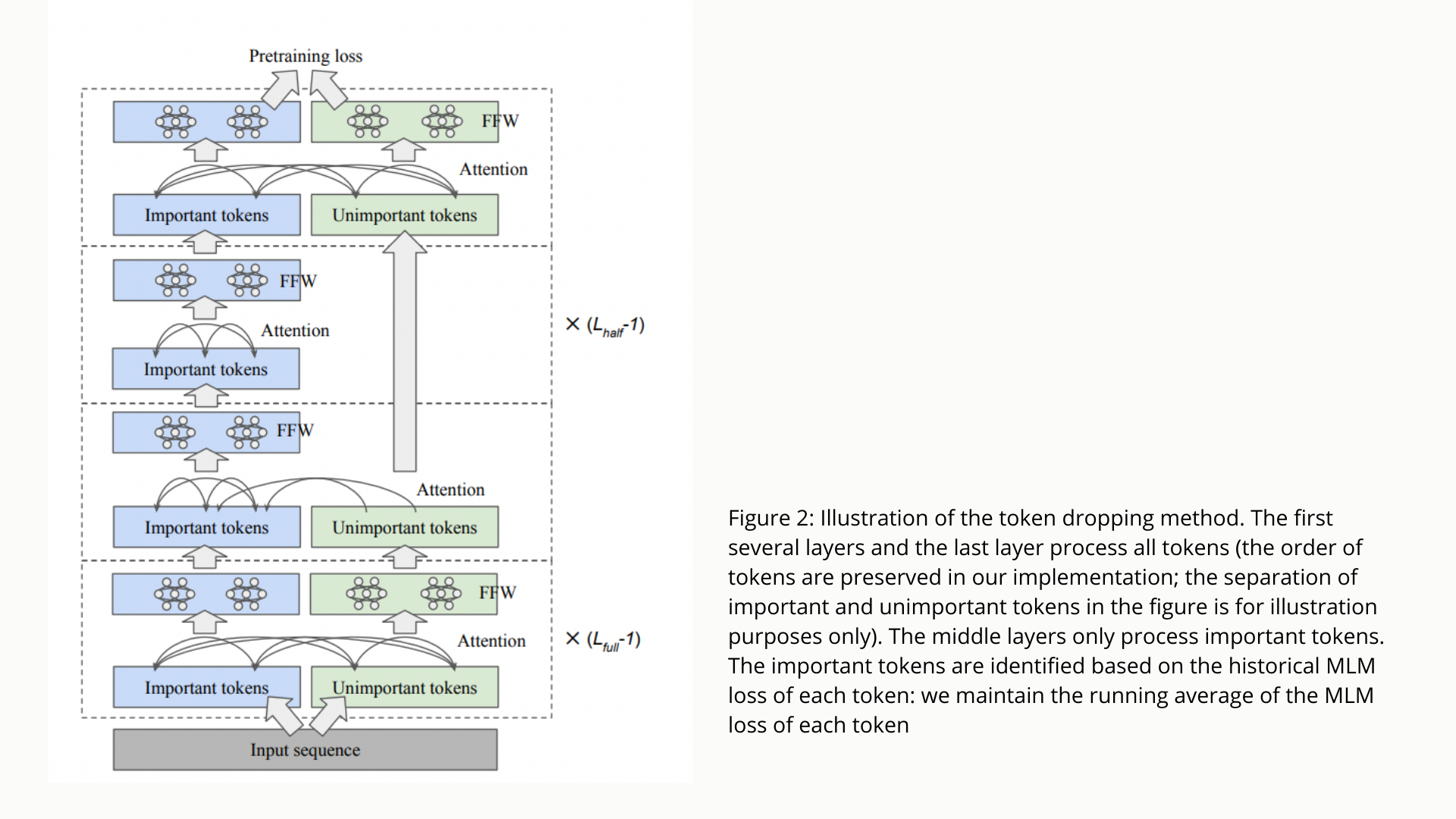
Token dropping is a technique for speeding up the pretraining of transformer models like BERT without sacrificing their performance on downstream tasks. Starting with an intermediate layer in the model, they eliminate uninteresting tokens to let the model focus on key tokens more effectively, given its limited computing resources. The model’s last layer then picks up the dropped tokens, producing full-length sequences. They use the built-in masked language modeling (MLM) loss and its dynamics to detect non-essential tokens with little computing complexity. According to their tests, this straightforward strategy decreases BERT’s pretraining cost by 25% while yielding somewhat higher overall fine-tuning performance on conventional downstream tasks.

Current transformer models spend the same amount of computation on each token in a sequence, which wastes a lot of the training budget on tokens that aren’t very informative. The researchers’ suggested token-dropping technique for BERT pretraining tackles this issue by deleting redundant or less informative tokens to training, allowing models to be trained on just the most informative tokens and input sequences.
While earlier research has assigned less computing to easy-to-predict tokens or used pooling on the embeddings of surrounding tokens, removing tokens directly is a novel method. Liu et al. identify key tokens in their 2021 study Faster Depth-Adaptive Transformers by using mutual information-based estimation between tokens and predetermined labels or using a separate BERT model that computes the masked language model (MLM) loss for each token.
The suggested technique seeks to speed up the task-agnostic pretraining phase by eliminating the need for labels or language model calculation. It categorizes significant tokens as complex for the model to predict through loss during training, a method that is flexible to the training process and has almost no processing cost. To substantially decrease compute and memory costs, the technique additionally recognizes tokens in each sequence with the minimal historical masked language model (MLM) loss as insignificant. It eliminates them from the intermediate layers of the BERT model during training.
Furthermore, because the proposed token dropping technique only needs intermediary training layers on a few relevant tokens, it may be modified without altering the original BERT architecture or training parameters. The researchers show that their straightforward technique works well on various downstream tasks using entire sequences.
The team hopes to use token-dropping to pretrain transformer models that can analyze considerably longer contexts in the future and apply the method to other transformer-based tasks like translation and text production.
Paper: https://arxiv.org/pdf/2203.13240.pdf
Github: https://github.com/tensorflow/models/tree/master/official/projects/token_dropping
Reference: https://syncedreview.com/2022/03/29/google-nyu-maryland-us-token-dropping-approach-reduces-bert-pretraining-time-by-25/
Suggested
Credit: Source link
Comments are closed.