Google AI Introduces a Common Voice-Based Speech-to-Speech Translation Corpus (CVSS) That Can Be Directly Used For Training Direct S2ST Models Without Any Extra Processing
This research summary is based on the paper 'CVSS Corpus and Massively Multilingual Speech-to-Speech Translation' Please don't forget to join our ML Subreddit
Speech-to-speech translation is the automatic translation of speech from one language to speech in another (S2ST). S2ST models have been widely accepted for bridging communication gaps between persons who speak different languages.
S2ST systems are traditionally developed with a text-centric cascade comprising automatic speech recognition (ASR), text-to-text machine translation (MT), and text-to-speech (TTS) synthesis subsystems. Recent studies have introduced S2ST, which does not rely on intermediary text representation. However, there are currently very few publicly available corpora directly relevant for such research.
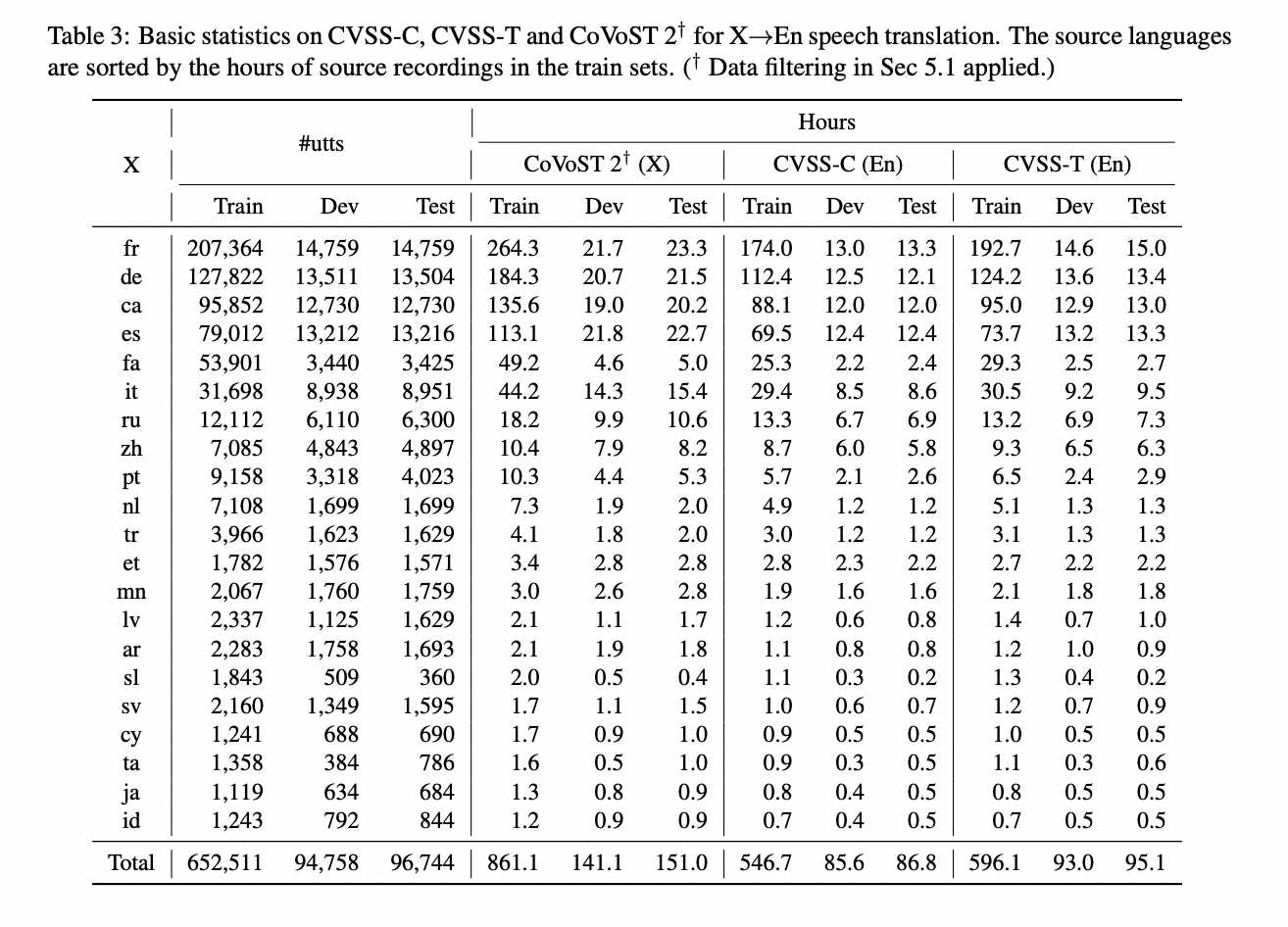
A new Google study has released CVSS, a Common Voice-based Speech-to-Speech translation corpus. From Arabic to Slovenian, CVSS provides sentence-level parallel speech-to-speech translation pairs into English from 21 languages. The Common Voice project used 1153 hours of crowdsourced human volunteer recordings to create the source talks in these 21 languages.
The CVSS corpus is generated directly from the CoVoST 2 ST corpus, derived further from the Common Voice speech corpus.
- Common Voice is a multilingual transcribed speech corpus created specifically for ASR. It was prepared by crowdsourcing the speech requiring volunteers to read text content from Wikipedia and other text corpora. There are 11,192 hours of validated speech in 76 languages in the current version 7.
- CoVoST 2 is a multilingual, large-scale ST corpus based on Common Voice. It includes translation from 21 languages into English and 15 languages into English. Experienced translators gathered the translation from Common Voice scripts. In total, there are 1,154 hours of speech in the 21 X-En language pairs.

For all of the source talks, two versions of translation speeches in English are provided, both synthesized using state-of-the-art TTS systems. Each version offers unique values that are mentioned below:
- CVSS-C: Each of the 719 hours of translation talks is delivered by a single canonical speaker who offers a consistent speaking style. These talks, despite their synthetic nature, exhibit a high level of naturalness and cleanliness. These features simplify target speech modeling and enable trained models to provide high-quality translation speech suitable for user-facing applications.
- CVSS-T: The translation speeches, totaling 784 hours, are invoices transferred from the matching source speeches. Despite being in different languages, each S2ST pair has similar voices on both sides. This makes the dataset appropriate for constructing models that preserve speakers’ voices while translating speech into foreign languages.
The two S2ST datasets contain 1,872 and 1,937 hours of speech, respectively, in addition to the source talks. CVSS delivers normalized translation text matching the pronunciation in the translation speech, which can assist both model training and evaluation.
CVSS’s target speeches are translation rather than interpretation. The translation is often literal and exact, whereas interpretation typically summarises and frequently omits less relevant aspects. Interpretation also has more language diversity and disfluency.
The team trained and compared a baseline cascade S2ST model and two baseline direct S2ST models on each CVSS version.
Cascade S2ST: The team trained the ST model on CoVoST 2 to construct robust cascade S2ST baselines. To produce highly powerful cascade S2ST baselines, this ST model is coupled to the same TTS models used to build CVSS (ST TTS). These models outperformed prior state-of-the-art by +5.8 average BLEU on all 21 language pairs (specified in the article) when trained on the corpus alone.
Direct S2ST: Using Translatotron and Translatotron 2, they created two baseline direct S2ST models. The translation quality of Translatotron 2 (8.7 BLEU) approaches that of the strong cascade S2ST baseline when trained from the start using CVSS (10.6 BLEU). Furthermore, the difference in ASR transcribed translation is only 0.7 BLEU when pre-training is applied to both.
Paper: https://arxiv.org/pdf/2201.03713.pdf
Github: https://github.com/google-research-datasets/cvss
Reference: https://ai.googleblog.com/2022/04/introducing-cvss-massively-multilingual.html
Suggested
Credit: Source link
Comments are closed.