OpenAI Introduces DALL-E 2: A New AI System That Can Create And Edit Realistic Images And Art From A Description In Natural Language
This research summary is based on the paper 'Hierarchical Text-Conditional Image Generation with CLIP Latents' Please don't forget to join our ML Subreddit
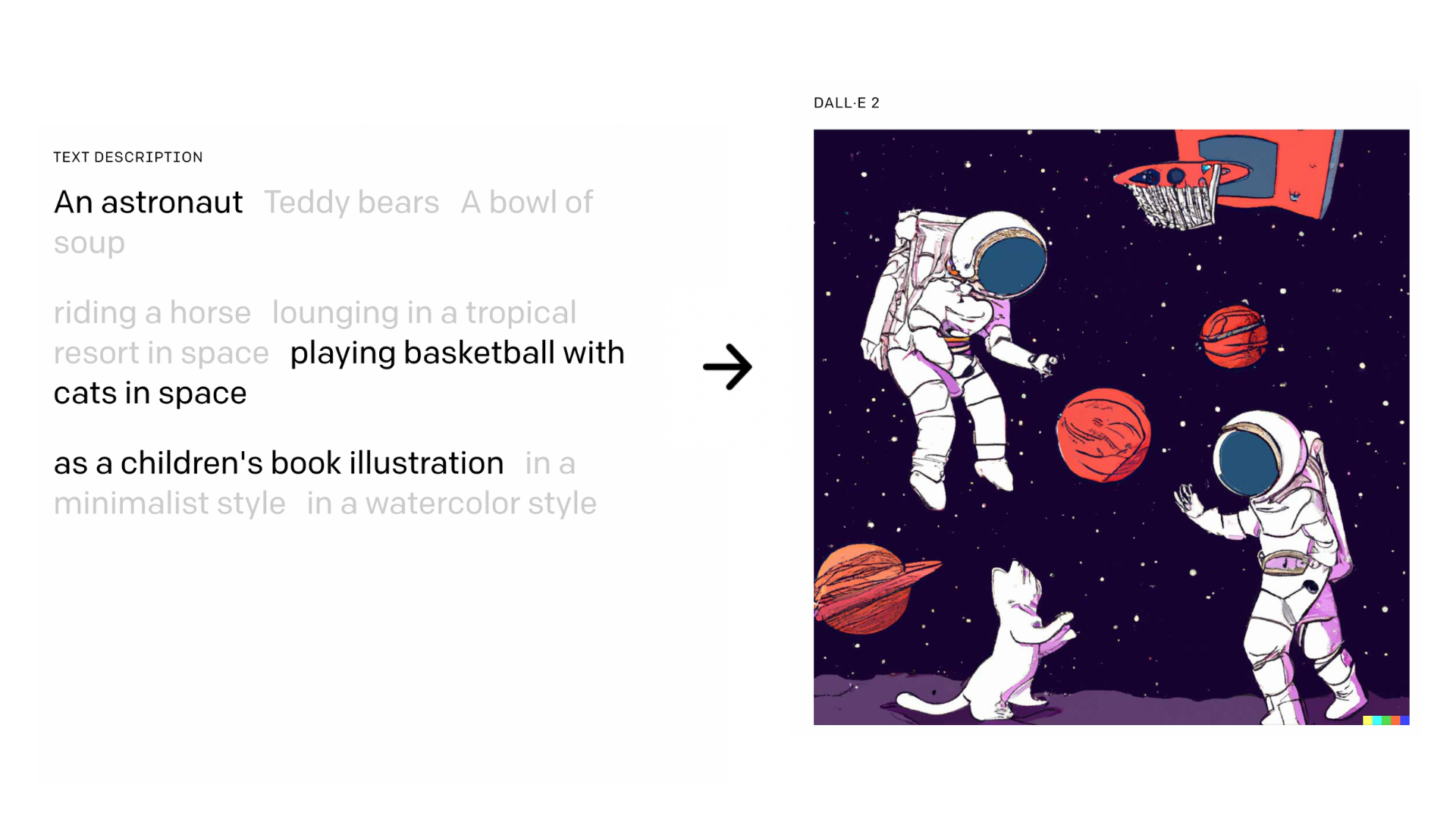
New research by the OpenAI team has released a new version of DALL-E, its text-to-image generation tool. DALL-E 2 is a higher-resolution and lower-latency variant of the original system, generating images based on user-written descriptions. It also has additional features, such as altering an existing image.

In January of 2021, the first DALL-E, a portmanteau of the artist “Salvador Dal” and the robot “WALL-E,” emerged, limited to AI’s capacity to visualize concepts. The researchers aimed to address the difficulties with technical safeguards and a new content policy, lower its computational load and advance the model’s basic capabilities.
Inpainting, one of the new DALL-E 2 features, applies DALL-E’s text-to-image capabilities at a finer level. Users can begin by selecting a section of an existing photograph and instructing the model to alter it. For example, users can cover a painting on a living room wall with a new picture or put a vase of flowers on a coffee table. The model can also fill (or remove) objects while considering factors such as shadow directions in a room. Variations is another function that works as an image search tool for photographs that don’t exist. Users can start with a single image and then make various modifications based on it.
They can also combine two photographs to create ones that have elements from both. The resulting images are 1,024 by 1,024 pixels, a significant improvement over the 256 x 256 pixels delivered by the previous model.
DALL-E 1 adapts over GPT-3 approach from language to picture production, in which images are compressed into a series of words and trained to predict what would happen next.
CLIP, a computer vision system that OpenAI also released last year, forms the foundation for DALL-E 2.
CLIP embeddings offer several appealing characteristics, such as resistance to picture distribution shift, excellent zero-shot capabilities, and cutting-edge outcomes on various vision and language tasks. On the other hand, diffusion models have emerged as a potential generative modeling framework, pushing the boundaries of picture and video production problems. Diffusion models use a guidance strategy to increase sample fidelity (for photos, photorealism) at the expense of sample diversity to attain the best results.
For the problem of text-conditional image generation, they combine these two approaches.
CLIP was created to look at photographs and summarize their contents similar to humans.
They iterated on this process to produce “unCLIP” — an inverted version that begins with the description and works its way to an image. Encoding and decoding images offer a way to see which features of the image are recognized by CLIP and which are ignored. DALL-E 2 creates the image by a technique known as diffusion, which involves starting with a “bag of dots” and gradually filling in a pattern with more and more complexity.
According to researchers, UnCLIP is partly immune to a quite amusing shortcoming of CLIP: humans can deceive the model’s identification capabilities by naming one object (such as a Granny Smith apple) with a term signifying something other (like an iPod)
In addition, the researchers have implemented some built-in precautions such as:
- The model is trained using data that had some offensive material removed, restricting the algorithm’s capacity to create unpleasant stuff. Although it may theoretically be cut out, there is a watermark identifying the AI-generated origin of the work.
- The model can’t create identifiable faces based on a name as a preventative anti-abuse feature. Even asking for the Mona Lisa would supposedly return a version of the painting’s genuine visage.
The researchers state that DALL-E 2 will be tested by vetted partners. Users are not allowed to upload or create photographs that are “not G-rated” or “may cause harm,” such as hate symbols, nudity, obscene gestures, or “big conspiracies or events relating to important ongoing geopolitical events.
The team aims to maintain a tiered process to keep reviewing how to securely distribute this technology based on the feedback they receive. Users are required to declare the use of AI in creating the photographs, which further cannot be shared with others via an app or website. However, the team plans to include it in its API toolbox in the future, allowing it for third-party apps.
Paper: https://cdn.openai.com/papers/dall-e-2.pdf
References:
- https://www.nytimes.com/2022/04/06/technology/openai-images-dall-e.html
- https://www.theverge.com/2022/4/6/23012123/openai-clip-dalle-2-ai-text-to-image-generator-testing
- https://openai.com/dall-e-2/
Suggested
Credit: Source link
Comments are closed.