Check Out This DeepMind’s New Language Model, Chinchilla (70B Parameters), Which Significantly Outperforms Gopher (280B) and GPT-3 (175B) on a Large Range of Downstream Evaluation Tasks
This research summary is based on the paper 'Training Compute-Optimal Large Language Models' Please don't forget to join our ML Subreddit
Extreme-scale language models have recently exhibited incredible performance on natural language processing challenges. This is due to their ever-increasing size, exceeding 500 billion parameters. However, while these models have grown in popularity in recent years, the amount of data utilized to train them has not increased. The current generation of huge language models is clearly undertrained. Three prediction approaches for optimally choosing both model size and training length have been proposed by a DeepMind research team.
The trade-off between model size and the number of training tokens:
Three approaches have been mentioned to estimate the optimal parameter:
- Change the size of the models and the number of training tokens.
- IsoFLOP profiles
- Using a parametric loss function to fit a model
The ultimate pretraining loss is calculated as the number of model parameters and training tokens. They minimize the loss function under the restriction of the FLOPs function, which is equal to the computational budget because the computational budget is a probabilistic function of the number of observed training tokens and model parameters.
The researchers altered the number of training steps for a fixed family of models, training each model using four distinct training sequences. They can immediately estimate the most negligible loss for a certain number of training FLOPs. The amount of training tokens is adjusted while the model sizes are fixed.
In the meantime, the IsoFLOP profiles method changes the model size for a predefined set of nine possible training FLOP counts. It takes the final training loss into account for each point.
All final losses from Approach 1 & 2 tests are modeled as a parameterized relation of input parameter count and the number of viewed tokens. They provide a functional form for capturing the loss of an ideal generative process on the data distribution and show that a wholly trained transformer underperforms the idealized productive strategy and is not taught to convergence.

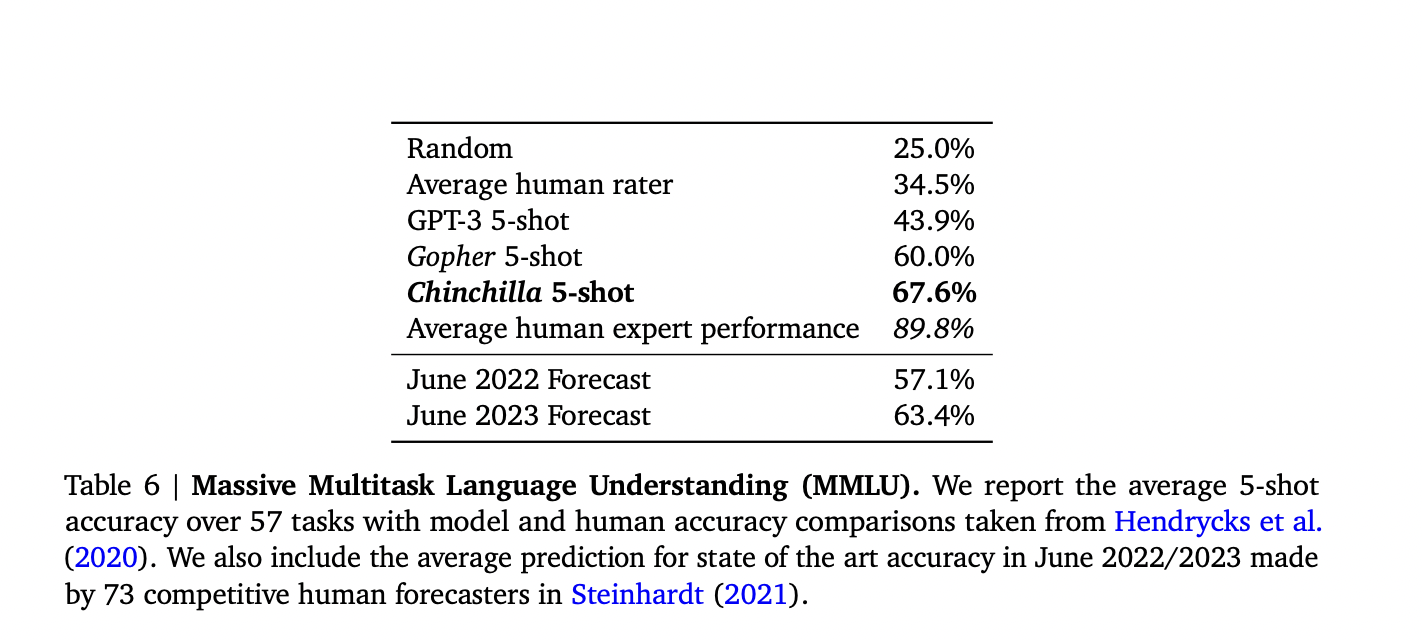
Following the methods outlined above, the suggested 70B Chinchilla outperforms Gopher (280B), GPT-3 (175B), Jurassic-1 (178B), and Megatron-Turing NLG consistently and significantly (530B). The researchers also discovered that, despite employing various fitting procedures and trained models, these three approaches produce comparable predictions for optimal parameter and token scaling with FLOPs.
Overall, this research contributes to developing an effective training paradigm for large auto-regressive language models with limited compute resources. It is standard practice to increase model size without matching the number of training tokens. However, the team recommends that the number of training tokens is twice for every model size doubling. This means that using larger, higher-quality training datasets can lead to better results on downstream tasks.
Paper: https://arxiv.org/pdf/2203.15556.pdf
Suggested
Credit: Source link
Comments are closed.