Baidu Researchers Propose PP-YOLOE Object Detector: an Evolved Version of YOLO Achieving SOTA Performance in Object Detection
This research summary is based on the paper 'PP-YOLOE: An evolved version of YOLO' Please don't forget to join our ML Subreddit
Object detection is a crucial problem in computer vision, and YOLO (You Only Look Once) one-stage object detectors have set the bar for performance since the release of YOLOv1 in 2015. The YOLO series has undergone considerable network and structural improvements over the years. The most recent version, YOLOX, has attained an optimal balance of speed and accuracy on the NVIDIA Tesla V100 Tensor Core GPU.
Baidu researchers have improved their earlier PP-YOLOv2 model, resulting in PP-YOLOE, a cutting-edge industrial object detector that beats YOLOv5 and YOLOX in speed and accuracy trade-off. The team’s PP-YOLOE-l variant outperforms PP-YOLOv2 by 1.9 percent AP and YOLOX-l by 1.3 percent AP on COCO datasets.

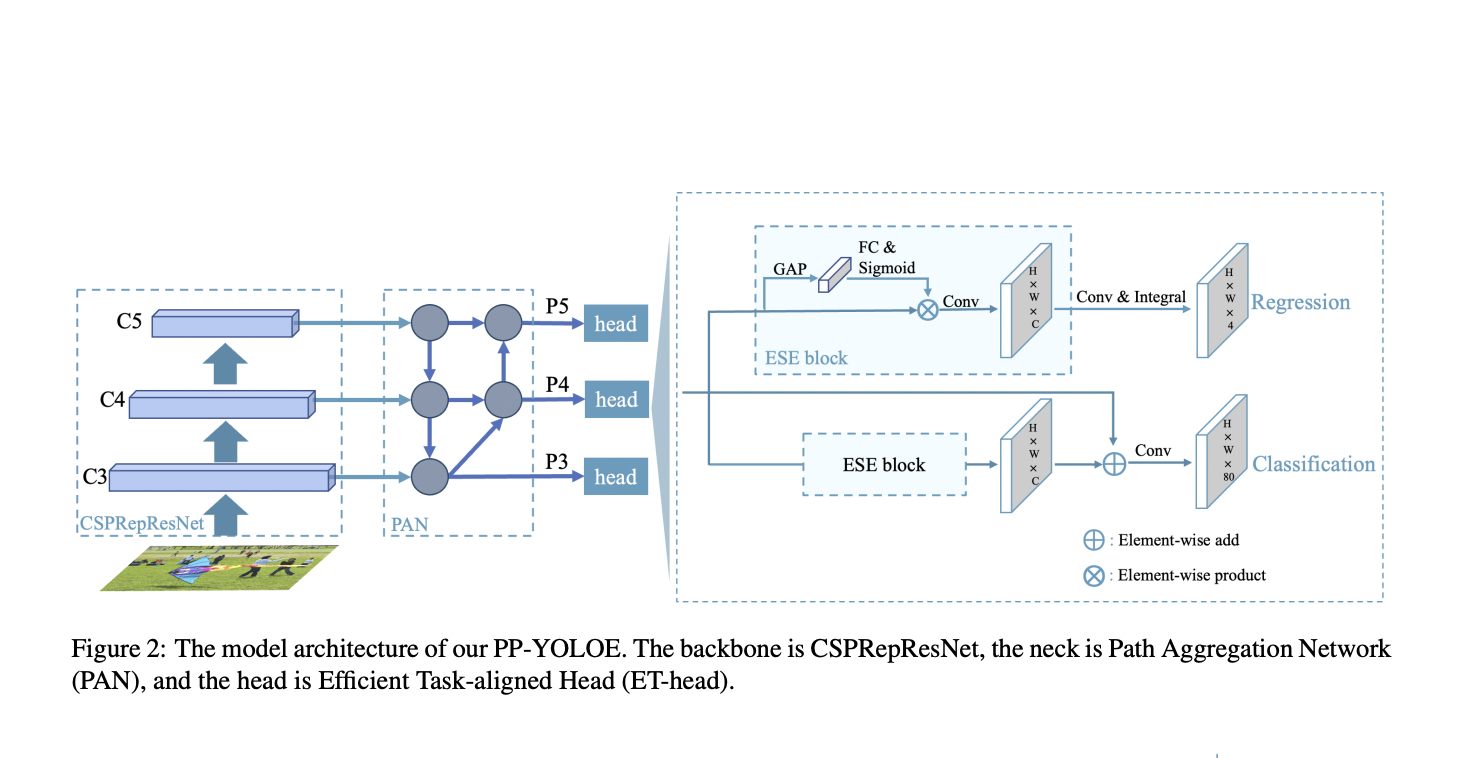
The PP-YOLOv2 baseline model architecture comprises a ResNet50-vd backbone with deformable convolution, a PAN neck with an SPP layer and DropBlock, and a lightweight IoU aware head. PP-YOLOv2 assigns only one anchor box to each ground truth object, similar to YOLOv3. It is strongly reliant on hand-crafted design, which may not generalize well enough when trained on other datasets. Conversely, this technique necessitates a lot of additional hyperparameters.
To overcome this problem, Baidu researchers have added an anchor-free technique to PP-YOLOv2 that tiles one anchor point on each pixel and assigns upper and lower bounds for detecting heads to assign ground facts to a matching feature map. The center of a bounding box can then be determined to choose positive samples from the closest pixels. A 4D vector is also predicted for regression, with minor model speedups and precision losses due to the changes.
Using a unique RepResBlock to build a CSPRepResNet backbone with one stem made of three convolution layers and four subsequent stages stacked by RepResBlock, the team improves the backbone and neck.
To jointly scale the basic backbone and neck, width, and depth multipliers are used to generate a series of detection networks (s/m/l/x) with variable parameters and compute costs. This update improves AP by 0.7 percent, bringing it to 49.5 percent.
The researchers also substitute label assignment with task alignment learning (TAL/TOOD, introduced by Feng et al. in 2021), which improves AP by 0.9 percent and raises overall AP to 50.4 percent.
Finally, the researchers use effective squeeze and extraction (ESE) to replace the layer attention in traditional task-aligned one-stage object detection, simplify the integration of classification branches to shortcuts, and replace the integration of regression branches with a focal distribution loss (DFL) layer to solve the task conflict between classification and localization in object detection. Further tweaks to the resulting Efficient Task-aligned Head (ET-head) have boosted performance.
The researchers compared the proposed PP-YOLOE to state-of-the-art object detectors such as YOLOX, YOLOv5, and EfficientDet on the MS COCO-2017 training set.
The PP-YOLOE-l variation earned 51.4 percent AP with 640 x 640 resolution at a speed of 78.1 FPS, a 1.9 percent AP improvement in the testing. It also achieved a 13.35 percent speedup over PP-YOLOv2, a 1.3 percent AP improvement, and a 24.96 percent speedup over YOLOX. With TensorRT and FP16-precision, the suggested model’s inference speed reached 149.2 FPS.
PP-YOLOE has been proved to be a high-performance object detector in general. The team expects their improved design and promising findings to motivate object detection developers and researchers.
Paper: https://arxiv.org/pdf/2203.16250.pdf
Github: https://github.com/PaddlePaddle/PaddleDetection
Suggested
Credit: Source link
Comments are closed.