Researchers From KAIST (Korea) Propose ‘DiffusionCLIP’: A Novel Method That Performs Text-Driven Image Manipulation Using Diffusion Models


This research summary is based on the paper 'DiffusionCLIP: Text-Guided Diffusion Models for Robust Image Manipulation' Please don't forget to join our ML Subreddit
GAN inversion approaches combined with CLIP (Contrastive Language-Image Pretraining) have recently gained popularity because they can do zero-shot picture alteration. However, due to the restricted GAN inversion performance, real-world application on many types of images is still difficult.
Successful image manipulation should, in particular, convert the image attribute to that of the target without changing the input information unintentionally. Regrettably, contemporary SOTA encoder-based GAN inversion techniques frequently fail to reconstruct images with fresh poses, viewpoints, and details. For instance, the encoder could fail to rebuild a feature, resulting in an unexpected change.
This is due to the fact that they have rarely seen such hands-on faces during their training. This problem is exacerbated when photos originate from a dataset with a lot of variance, such as the church images in the LSUNChurch and ImageNet datasets. Existing GAN inversion approaches, for example, construct false designs that can be regarded as various buildings when converting to a department store.
Recent successes in picture generating problems have been gained using diffusion models such as denoising diffusion probabilistic models (DDPM) and score-based generative models. Recent research has shown that picture synthesis performance is even better than that of variational autoencoders (VAEs), flows, auto-regressive models, and generative adversarial networks (GANs). Furthermore, a recently developed denoising diffusion implicit model (DDIM) accelerates the sampling process and allows for near-perfect inversion.
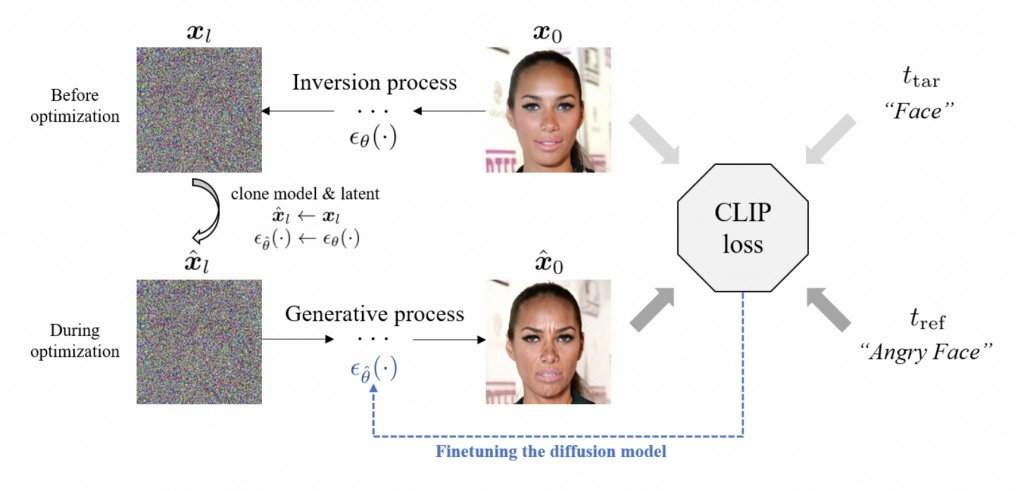
Researchers at the Korea Advanced Institute of Science and Technology (KAIST) have proposed a unique DiffusionCLIP – a CLIP-guided robust image alteration method based on diffusion models – in a recent study. Through forward diffusion, an input image is first converted to latent sounds.
If the score function for the reverse diffusion is kept the same as the score function for the forward diffusion, the latent noises can be inverted nearly precisely to the original picture using DDIM. DiffusionCLIP’s main idea is to use a CLIP loss to fine-tune the score function in the reverse diffusion process, which controls the properties of the created image based on the text prompts.
As a result, DiffusionCLIP can successfully manipulate images in both the trained and unseen domains. The team can even translate an image from one domain to another or construct images in a different domain using the strokes. Furthermore, numerous properties can be altered simultaneously using only one sampling method by simply mixing the noise predicted by several fine-tuned models.
DiffsuionCLIP also makes a step toward universal applicability by modifying images from the ImageNet dataset, which has rarely been studied with GAN-inversion due to its poor reconstruction. In addition, the team provides a method for systematically determining the best sample settings for high-quality and quick picture alteration. The approach may deliver robust and accurate picture alteration, outperforming SOTA baselines, according to qualitative comparison and human evaluation results.
The size of images used by DiffusionCLIP for all alteration results is 2562. They manipulate photos of human faces, dogs, bedrooms, and churches using models trained on the CelebA-HQ, AFHQ-Dog, LSUN-Bedroom, and LSUN-Church datasets, respectively.
The results show that the reconstruction is practically faultless and that high-resolution images can be modified flexibly outside the taught domains’ boundaries. GAN-based inversion and manipulation in ImageNet’s latent space, in particular, demonstrate limited performance due to the diversity of the images in ImageNet. DiffusionCLIP allows for zero-shot text-driven picture editing, taking a step closer to generic text-driven manipulation.
Conclusion
In this work, researchers at the Korea Advanced Institute of Science and Technology (KAIST) offer DiffusionCLIP, a text-guided picture alteration approach based on pre-trained diffusion models and CLIP loss. DiffusionCLIP displays exceptional performance for both in-domain and out-of-domain manipulation by fine-tuning diffusion models, thanks to its near-perfect inversion property. The team also shows how fine-tuned models can be used in new ways by combining different sampling procedures.
Paper: https://arxiv.org/pdf/2110.02711.pdf
Github: https://github.com/gwang-kim/DiffusionCLIP
The post Researchers From KAIST (Korea) Propose ‘DiffusionCLIP’: A Novel Method That Performs Text-Driven Image Manipulation Using Diffusion Models appeared first on MarkTechPost.
Credit: Source link
Comments are closed.