Researchers Propose a Novel Framework ‘LilNetX’ For Training Deep Neural Network With Extreme Model Compression, and Structured Sparsification
This summary article is based on the paper 'LilNetX: Lightweight Networks with EXtreme Model Compression and Structured Sparsification' and all credit goes to the authors of this paper. Please don't forget to join our ML Subreddit
In this research, the researchers from the paper ‘ LilNetX: Lightweight Networks with EXtreme Model Compression and Structured Sparsification’ talk about the importance of larger parameter-heavy and computationally costly architectures in deep neural networks (DNNs) and how it improves the computer vision tasks. They also mentioned in the paper that it is not as simple as it seems since, as the DNNs become more common in the business, they are frequently required to be trained multiple times, communicated across the network to various devices, and executed under hardware limits with minimum loss of accuracy, all while maintaining accuracy. Then the question arises of how to reduce the models’ size on the devices while still enhancing their run-time. Explorations in this field have tended to take one of two paths: lowering model size via compression approaches or reducing computing demands through model pruning.
The main achievement of this research from the University of Maryland and Google Research is the introduction of ‘LilNetX’, an end-to-end trainable neural network technique that allows learning models with specified accuracy-rate-computation trade-offs. Prior work has taken a piecemeal approach to these difficulties, which necessitates post-processing or multistage training, which is not efficient and does not scale well for big datasets or architectures. To encourage modest model size, the strategy is to create a joint training goal that penalizes the self-information of network parameters in a reparameterized latent space while simultaneously incorporating priors to increase structured sparsity in the parameter space to decrease computation.
LilNetX is a network inference approach that combines model compression, organized and unstructured sparsification, and direct computational improvements. The system can be trained from start to finish using a single joint optimization target, with no post-hoc training or post-processing required.
The strategy’s effectiveness can be proved while surpassing existing approaches in both model compression and pruning in most networks and dataset setups with thorough ablation trials and results.
The researchers consider the classification task using a convolutional neural network (CNN) to train a CNN that is jointly optimized to: 1) maximize classification accuracy, 2) reduce the number of bits required to store the model on disk, and 3) reduce the computational cost of inference in the model. The researchers point out that the method can be used for other tasks such as object detection or generative modeling and that theirs is the first work to show that models can be optimized in terms of compression and structural sparsity simultaneously.
The state-of-the-art performance of the proposed LilNeX in simultaneous compression and FLOPs reduction correlates to inference speedups. It confirms the method’s capacity to jointly optimize DNNs in compression (to reduce memory requirements) and structured sparsity (to reduce computation).
To conduct model compression, reparameterized quantization has been used by penalizing the entropy of weights quantized in a reparameterized latent space. This method is particularly valuable for lowering the size of the effective model on the disk. There have also been significant adjustments to reparameterized quantization, such as encouraging structured and unstructured parameter sparsity in the model and allowing trade-offs between model compression rates and accuracy so that the whole dense model is no longer required during inference. The researchers also use priors to boost structured sparsity in the parameter space and reduce computation, and the model is dubbed LilNetX (Lightweight Networks with EXtreme Compression and Structured Sparsification).

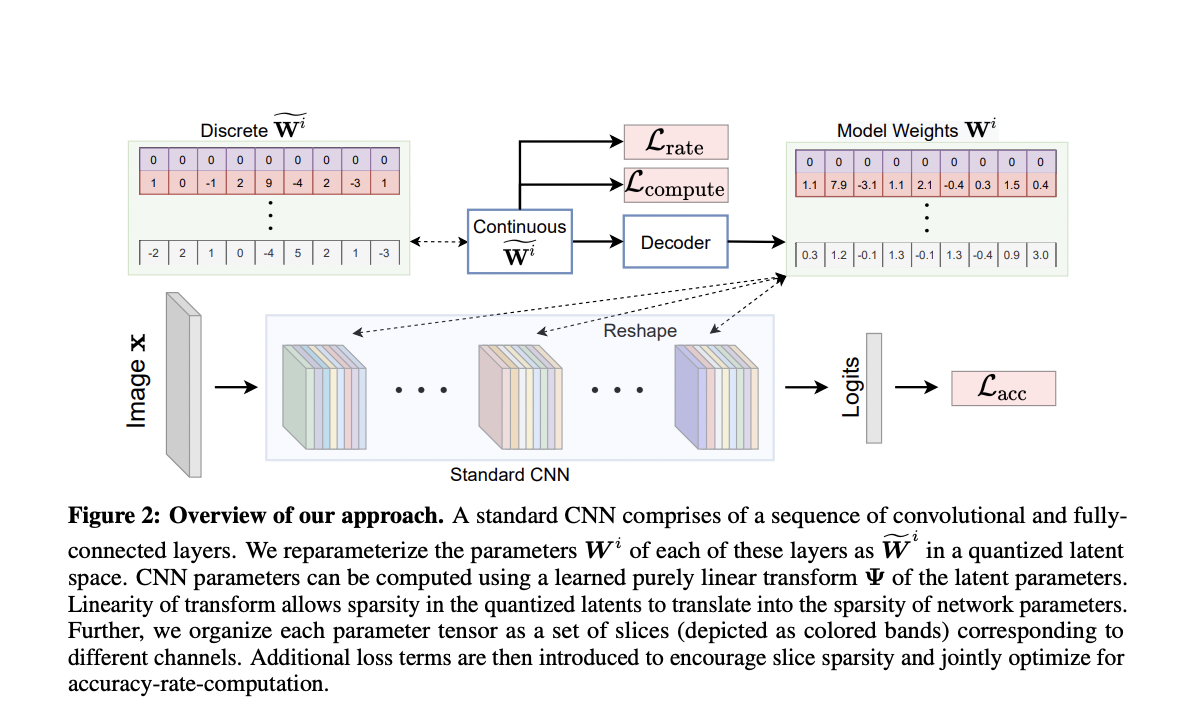
Fig – Overview of the approach: A conventional CNN comprises convolutional and wholly linked layers. The Wi parameters of each layer are re-parameterized as Wi in a quantized latent space. A learned purely linear transform of the latent parameters could be used to compute CNN parameters. The linearity of the transform enables the quantized latents’ sparsity to be translated into the sparsity of network parameters. Each parameter tensor has also been divided into slices (shown as colored bands). Then, more loss terms are incorporated to encourage slice sparsity and jointly optimize for accuracy-rate computation.
The method achieves state-of-the-art performance in simultaneous compression and reduction in FLOPs, which translates to faster inference. The team tested the methods on three datasets using three different network topologies (VGG-16, ResNet, and MobileNet-V2) (CIFAR-10, CIFAR-100, and ImageNet). LilNeX achieves up to 50% smaller model size and 98 percent model sparsity on ResNet-20 while maintaining the same accuracy on the CIFAR-10 dataset compared to existing state-of-the-art model compression methods. On ResNet-50 trained on ImageNet, the technique results in a 35 percent reduced model size and 42 percent structural sparsity.
Paper: https://arxiv.org/pdf/2204.02965.pdf
Github: https://github.com/Sharath-girish/LilNetX
Credit: Source link
Comments are closed.