Meta AI’s Self-Supervised Learning Demo For Images Are Now Live
This summary article is based on Meta AIs research article 'Explore Meta AI’s self-supervised learning demo for images' and all credit goes to Meta Researchers. Please don't forget to join our ML Subreddit
The first-ever demo based on Meta AI’s self-supervised learning research is now public. It’s concentrated on Vision Transformers pre-trained using DINO, a method that has risen in popularity due to its ability to comprehend the semantic layout of a picture.
DINO is chosen for the first example because of its capacity to learn generic and strong semantic characteristics, such as patch-level matching and retrieval. People will be able to see these breakthroughs directly by using the demo, which includes discovering comparable photos or fragments of similar images, such as matching the eyes of a puppy to find similar-looking pups, independent of their position, location, or illumination in an image.
While this may be a little use case, this demonstration’s technology is vital for the larger-picture future. Self-supervised learning-powered computer vision is a crucial aspect of enabling Meta AI researchers to develop AI systems that are more resilient and less domain-centric in nature.

DINO enables AI researchers to create highly efficient computer vision systems that excel at various tasks and are significantly less reliant on labeled data sets. Large-scale self-supervised learning training for computer vision requires an algorithm that can learn from random, unlabeled photos and videos and a massive quantity of data to capture every detail of diversified, ordinary life.
The new AI Research SuperCluster will enable investigating the training of larger models on increasingly larger data sets, pushing the limits of what self-supervised learning can do. Self-supervised learning is being used to enhance computer vision.
While the DINO code has already been provided, this demo allows academics and engineers to investigate how the model interprets photos, verify its resilience, and try it independently. It also enables those interested in novel AI approaches to show how a single methodology may provide general models to address many problems.
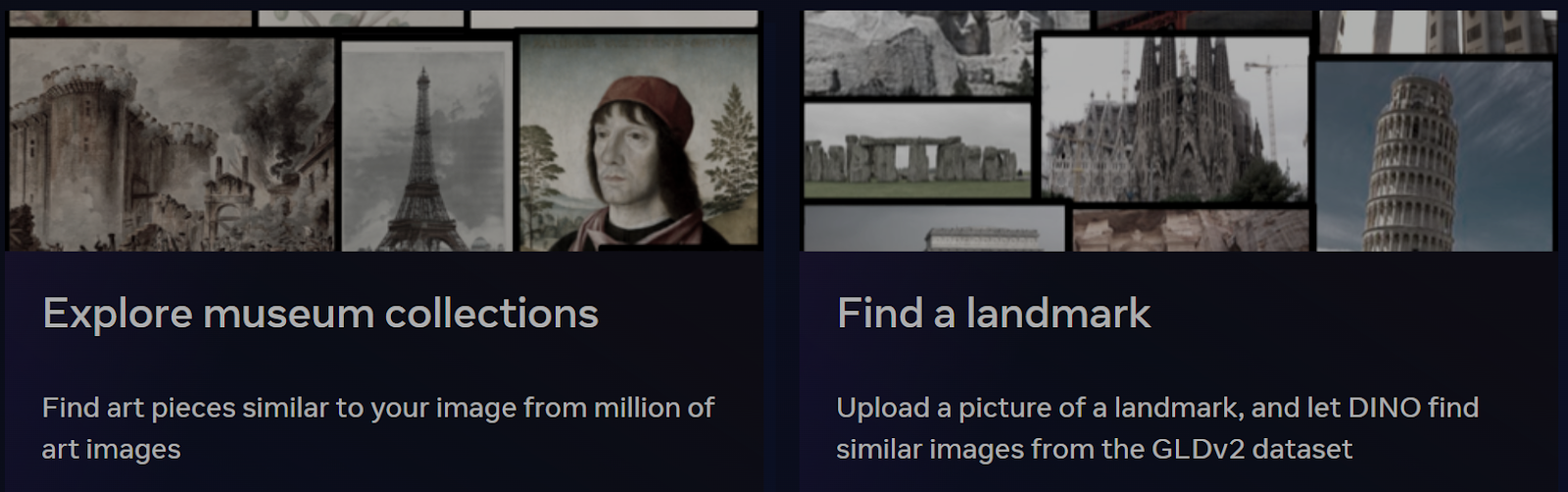
In the demo, users may try out a variety of experiences. A user may use image retrieval to choose a photo and discover related images from a data collection of five million images owned by a third party. Patch-level recovery allows users to select an object or portion of an image to find related pictures, such as the dog eyes mentioned previously. Finally, patch-matching may detect comparable regions in two photographs despite variations in the backdrop, object orientation, and illumination.
When a user launches the demo and enters a picture or specifies a patch of an image, DINO generates characteristics and descriptions that may be used to determine how similar the idea is to others.
These outputs are valuable because they can be used to compute the distance between two pictures in the same way that distances between three-dimensional locations defined by three integers can be calculated. (For example, a cat picture is “far away” from a car image yet near a dog image and even closer to another cat image.) This distance attribute drives the DINO demo and produces results, whether obtaining the nearest picture or utilizing patch-matching to show the closest patch.
DINO includes a training approach that allows an untrained model to learn this attribute without requiring labeled data.
It is built on a simple intuition: given a picture, make multiple adjustments and train the model that the changed image should still look like the original image. Changes to the brightness or contrast, clipping a smaller portion of the image or rotating the image are examples of these alterations. The model may learn something new with each tweak. It comprehends by rotating that a rabbit in different stances represents the same thing. However, the brightness modification teaches that a bunny in the shade is equivalent to a bunny in brilliant sunshine.
While this architecture was not designed with metaverse uses in mind, there are possible future applications for doing customized visual queries that remain exclusively on a person’s device, which can help keep data more private. Take a snapshot of an object, for example, to educate DINO, “these are my vehicle keys.” When you’re hunting for your keys later, you might ask, “Where are my vehicle keys?” This application necessitates the ability to recall items and locate them in photos, which the DINO model excels at.
Another potential future use case is duplicate image detection. DINO-based models might aid in detecting duplicates of a specific piece of dangerous information, even if the picture has been altered. The breakthroughs in self-supervised learning will eventually pave the way for a future in which machine learning algorithms may be created on and remain on a person’s device, resulting in a more private and customized future driven by AI assistants.
Self-supervised learning allows getting a comprehensive grasp of real-world surroundings and how people interact with them, which is too large and diverse to capture in labeled data sets. We’ll need AI to learn from everything it sees and hears, which can only be accomplished through self-supervised learning.
While DINO demonstrates progress in self-supervised learning and has many intriguing possible future use cases, it is ensured to be utilized as a part of open science ethical AI. Uploading images of humans is against the demo’s terms of service, and a detector was added to prevent human faces.
Everyone is welcome to partake in the demonstration. While self-supervised learning is still unwinding, the future possibilities of more private and personalized AI endeavors are pretty thrilling.
References:
- https://ai.facebook.com/blog/dino-self-supervised-learning-demo/
- https://ssl-demos.metademolab.com/home
Credit: Source link
Comments are closed.