“Doodle It Yourself” DIY-FSCIL: A Novel AI Framework For Few Shot Class Incremental Learning Without Violating The Data Privacy And Ethical Norms
This summary article is based on the paper 'Doodle It Yourself: Class Incremental Learning by Drawing a Few Sketches' and all credit goes to the authors of this paper. Please don't forget to join our ML Subreddit
Class Incremental Learning methods aim at extending the ability of machine learning models in recognizing novel classes, while not forgetting what they know about already known classes. Few-Shot Class Incremental Learning is a recent solution that pushes the model to learn the new classes with very few examples. In this research topic, it is important to consider two key questions: (1) what data modality should be used for the samples of the new classes and (2) how such samples could be obtained in practice. The researchers of the University of Surrey that proposed this paper considered a scenario in which the machine learning model is a photo classifier. Their purpose is to have a model that could be used in real-world scenarios while simulating how humans learn during their life. Specifically, the idea is two-fold: (1) as humans, the model must learn from different data modalities (i.e., not only photos) (2) without asking the users to provide photos that can be unavailable (also for privacy and ethical constraints like copyright issues).
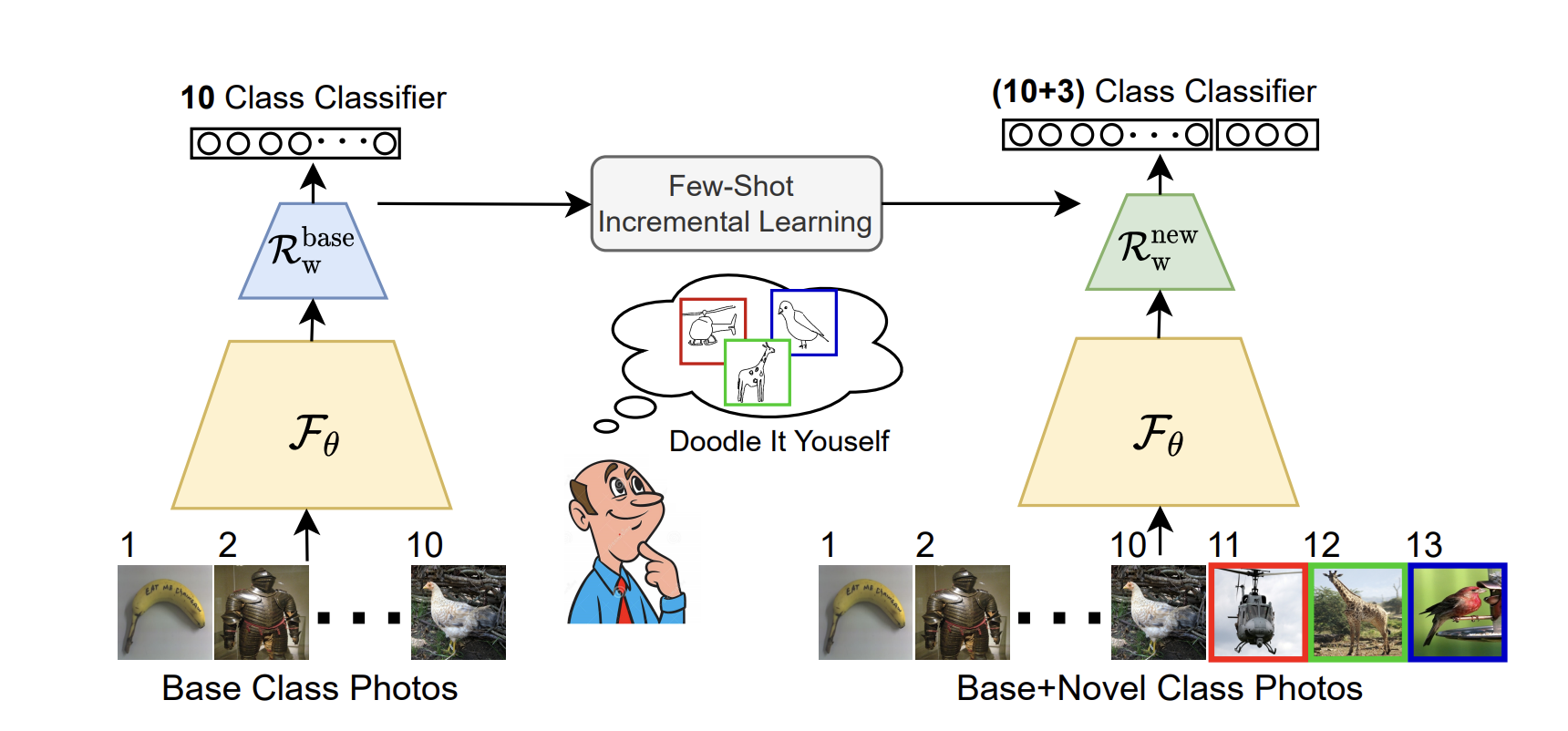
The Figure above depicts the overall architecture of Doodle It Yourself – Few-Shot Class Incremental Learning (DIY-FSCIL), the framework proposed in this paper. In the beginning, we start with a 10-class classifier (Rwbase) that receives as input the features extracted by a feature extractor (F) for the base class photos. Then, given sketch exemplars provided by the users (1 sketch for each novel class in the figure) for 3 novel classes, we obtain Rwnew, a (10+3)-class classifier that is able to classify photos from both base and novel classes.
To develop DIY-FSCIL, the authors faced three design challenges: (1) how to obtain a cross-modalities model minimizing the domain gap between sketch samples and real photos, (2) how to preserve and not forget base classes information, and (3) how to exploit information from base classes to quickly learn the novel classes using few samples. For the first problem, the authors trained a domain-agnostic feature extractor through gradient consensus. For the second problem, they used a knowledge distillation loss to keep knowledge about the base classes while incrementing the classifier to novel ones. For the third problem, this framework relies on a graph neural network to generate more discriminative decision boundaries between the old and the novel classes. The framework follows a two-stage training process which is described in the following paragraphs.
In the first stage, the goal is to learn a domain-agnostic feature extractor F through gradient consensus to handle the domain gap between photos and sketches. During this training stage, the authors relied on mini-batches that are equally composed of both labeled photos and sketches. At the same time, the loss function used in this stage is composed of two individual losses: one for the photos and one for the sketches. The idea is to update the model so that there is an agreement in the gradient space (i.e., gradient consensus) between the two domains, in order to learn a domain-invariant representation for the features. In this way, the model parameters are updated to improve the generalization capabilities of the framework on both photos and sketches.
During the second stage, the framework learns a weight generator G through incremental learning, involving two steps. In the first step of this second stage, the purpose is to obtain an updated base+novel classifier (Rwnew) through a sketch support set that is used to produce weight vectors for the novel classes and to refine the weight vectors related to the base classes. This process allows obtaining a better decision boundary in the presence of photos of both base and novel classes. Note that, during this second stage, the weights of F are freezed to avoid overfitting during the few-shot update and to alleviate the catastrophic forgetting issue for the base classes.
Let’s describe what happens in the first step of this second stage in detail. The generator G takes as input (1) the weight matrix Wbase from the Rwbase classifier, representing previous base classes knowledge, and (2) the class-wise representative features of the novel classes obtained from sketch exemplars Wnovel . These class-wise representative features are obtained by averaging the feature representations of the sketches of each class. In order to obtain an optimized decision boundary for both base and novel classes, the generation of the weight vectors Wnew for both base and novel classes are obtained through an information passing mechanism implemented by using a Graph Attention Network.
In the second step of the second stage, the classifier Rwnew is used to classify a query set of real photos from both base and novel classes. This step is necessary to compute the final loss which is used to optimize the weights Wnew by using the gradient descent algorithm. Finally, in order to further optimize Rwnew based on the knowledge learned from Wbase, a distillation loss is added to the standard classification loss during the training process applied over the query set. This distillation loss ensures that the weight vectors Wnew remain close to what has been learned during the first stage of training. Specifically, the distillation loss is computed by considering the predictions of Rwbase over the query set as ground truths.
Paper: https://arxiv.org/pdf/2203.14843.pdf
Credit: Source link
Comments are closed.