Google Researchers Introduce ‘MAXIM’: Multi-Axis MLP Based Architecture For Image Processing
This article summary is based on the research paper: 'MAXIM: Multi-Axis MLP for Image Processing'. All credits for this research goes to the authors of this paper. 👏 👏 👏 👏 Please don't forget to join our ML Subreddit Need help in creating ML Research content for your lab/startup? Talk to us at [email protected]
Google Intern Researchers Proposed a Multi-Axis Multi-Layer Perceptron Technique for several vision applications utilizing fewer or comparable parameters compared to the state-of-the-art. Image Restoration and Image Degradation help to generate the desired output from the degraded image. Several techniques are implemented by researchers to resolve low vision tasks that include dense connections, attention-based techniques, residual learning mechanisms, etc. The traditional techniques utilize Transformers, which can produce artifacts on the boundary in larger images.
Following these concepts, the Google Research team introduces multi-axis Multi-Layer Perceptron (MAXIM) that parallelly captures local and global interactions. It integrates a single axis for each branch which makes it fully convolutional as well as scalable. To boost the performance cross gating module is utilized, which adaptively gates the skip connection.
The major contributions of the research are a unique architecture consisting of a stack of encoder-decoder backbones controlled by a multi-scale, and multi-stage loss. A module comprising of a multi-axis gated Multi-Layer Perceptron (MLP) has linear complexity. A block to cross condition the two separate features is known as a cross gating block.
The complexity of the proposed approach is the summation of Global MLP, Local MLP, and dense layers.

The complexity of the above equation is linear to image size HW, although it is quadratic for the global models like ViT, Mixer, and gMLP.
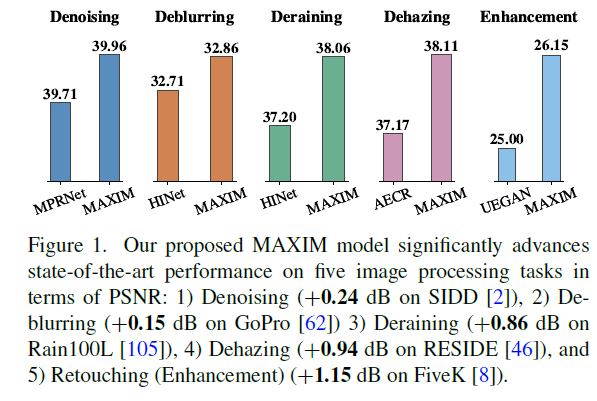
Furthermore, it accomplishes State of the Art results with fewer parameters on more than 10 standard datasets with a variety of image processing tasks like denoising, deraining, dehazing, deblurring and enhancement as depicted in Figure 1.
Architecture
The proposed architecture follows a hybrid model in which conv is used for local level and MLP for long-range interactions. Multi-axis gated block is introduced along with a residual channel attention block (RCAB) at the encoder, decoder, and bottleneck for permitting long-range spatial mixing at different scales.
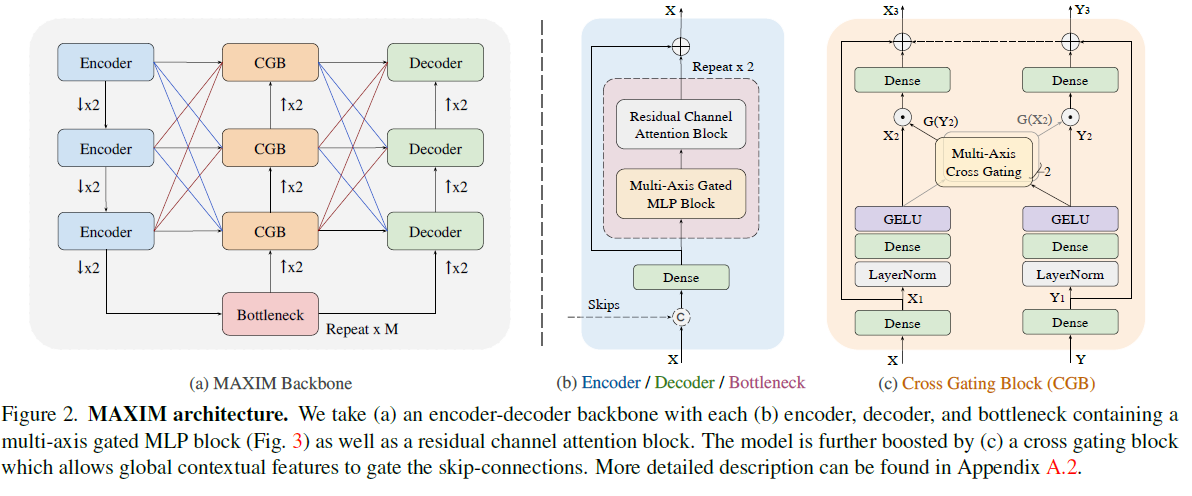
The research provides more focus on multiple axes. Regional and dilated attention are the two forms of sparse self-attention applied on two axes on blocked images.
As an alternative to applying multi-axis attention in a single layer, it is divided in half the heads. In the local branch, the first half head is congested into a tensor that represents partitioning into nonoverlapping windows while in the global branch the other half is gridded using a fixed grid. Finally, the processed heads are integrated. This helps to reduce the number of channels and the model is benefited to focus on reducing boundary artifacts.
This work introduces cross-gating features that interact with multiple features. In this approach to accomplish strong supervision, a multi-scale approach is applied at each stage that helps the network to learn. It is evaluated on several applications such as deblurring, denoising, dehazing, deraining, and enhancement on 17 datasets. The evaluation of the proposed model is performed using SSIM and PSNR to compare ground truth and predicted images quantitatively. Also, SIDD and DND are utilized for denoising, GoPro, HIDE, and RealBlur for deblurring. RESIDE is used for dehazing, FIVE-K, and LOL for enhancement.
The proposed model is end-to-end trainable. It does not require large-scale pretraining or progressive training. The architecture is trained on patches of size 256*256 of random cropped images. Data augmentation technique is also utilized by horizontal, vertical flips, 900 rotation, and MixUP with 0.5 probability.
The approach proposed two distinct models named MAXIM-2S which is a two-stage model and MAXIM-3S which is a three-stage model.
The approach is validated on the GoPro dataset on the MAXIM-2S model. Individual components were tested and effects of the multi-axis approach, multi-stage, and MAXIM families were tested.
Conclusion:
A generic network for enhancement as well as restoration tasks is utilized in this work. It also proposes a novel method by applying a gMLP to achieve global attention. The proposed approach is efficient for several vision applications such as denoising, deraining, deblurring, enhancement, and dehazing. This work can be enhanced for extremely high image processing applications, training larger models to adapt to multiple tasks, and for other enhancement and restoration applications.
Paper: https://arxiv.org/pdf/2201.02973v2.pdf
Github: https://github.com/google-research/maxim
Credit: Source link
Comments are closed.